











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用深度学习来简化科学图像分析
2018年03月19日 由 nanan 发表
172445
0
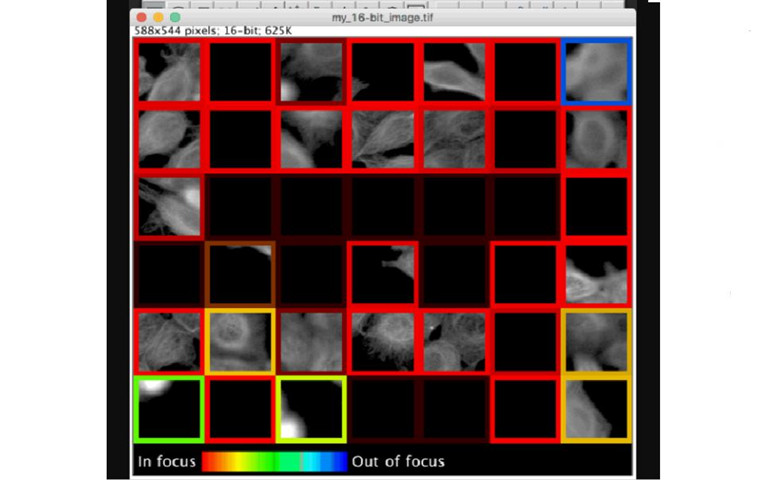
- 组装高质量的图像数据集
该显微镜主要用于成像应用程序,来分析每天TB数据。这些应用程序可以通过计算机视觉和深度学习的最新进展而获益。现在,Google工程师与机器人显微镜应用合作,组装了高质量的图像数据集,将信号与噪声分开。
在“深度学习评价显微镜图像聚焦质量”中,研究人员训练了一个深度神经网络,用比以往方法更高的准确率,来评价显微图像的焦点质量。他们在Fiji (斐济)和CellProfiler(两个领先的开源科学图像分析工具)中添加了预先训练的TensorFlow模型,该模型可用于图形用户界面或通过脚本调用。
Google Accelerated科学团队研究科学家Samuel Yang说:“我们的出版和源代码(TensorFlow、Fiji、CellProfiler)阐述了机器学习项目工作流程的基础知识:组装一个训练数据集(我们合成了384个焦点对焦图像细胞,避免需要手工标记的数据集),训练使用数据模型,评估泛化(在我们的例子中, 通过额外的显微镜获取看不见的细胞类型)并部署预先训练的模型。

预先训练的TensorFlow模型为Fiji(斐济)细胞的显微图像斑块的蒙太奇提供了对焦质量(ImageJ)。边界的色调和亮度分别表示预测的聚焦质量和预测不确定性。
“以前用于识别图像焦点质量的工具通常要求用户手动检查每个数据集的图像,以确定在焦点和非焦点图像之间的阈值;我们的预训练模型不需要用户设置参数,也不需要更精确地对焦点质量进行评估。为了提高可解释性,我们的模型评估了84×84像素色块的聚焦质量,这些色块可以用彩色色块边界进行可视化处理。”
我们克服的一个有趣的挑战是,经常存在没有对象的“空白”图像补丁,这是一种不存在焦点质量概念的场景。我们没有明确地标注这些“空白”补丁,并教导我们的模型将它们识别为一个单独的类别,而是配置我们的模型以预测散焦水平的概率分布,从而学习如何表达不确定性的(图中暗淡的边界)空白色块(例如,预测等于/不在焦点内)。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消