











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






IBM称其机器学习库的速度比TensorFlow快了46倍
2018年03月22日 由 nanan 发表
500782
0

IBM声称POWER9服务器和Beastly处理器(GPU)相结合,可以让Google Cloud发生颠覆。
IBM宣称,其POWER服务器上的机器学习不仅比Google Cloud中的TensorFlow快,而且速度快了46倍之多。
今年2月,谷歌软件工程师Andreas Sterbenz写了关于使用Google Cloud Machine Learning和TensorFlow进行大规模广告和推荐场景点击预测的文章。
他训练了一个模型来预测对Criteo Labs日志的点击率,这些日志的大小超过1TB,并包含来自数百万展示广告的特征值和点击反馈。
数据预处理(60分钟)之后进行实际学习,使用60台工人机器和29台参数机器进行训练。该模型花了70分钟进行训练,评估损失为0.1293。我们知道这是结果准确性的粗略指标。
然后,Sterbenz采用了不同的建模技术来获得更好的结果,降低了评估损失,这一切都花费了更长的时间,最终使用了具有三个时期的深度神经网络(测量了所有训练矢量一次用来更新权重的次数的度量),耗时78小时。
但IBM对此并不感兴趣,他们希望证明在POWER9服务器和GPU上运行的自己的训练框架,可以在基本的初始训练上,胜过Google Cloud 平台的89台机器。
位于苏黎世IBM研究公司的Thomas Parnell和Celestine Dunner使用了相同的源数据——Criteo Terabyte Click Logs,拥有42亿个训练样本和100万个特性,以及相同的机器学习模型、逻辑回归,但还有一个不同的机器学习库。这就是所谓的快速机器学习。
他们使用运行在四台Power System AC922服务器上的Snap ML运行会话,即8个POWER9 CPU和16个Nvidia Tesla V100 GPU。它以91.5秒的速度完成,整整快了46倍。
他们准备了一张显示Snap ML,Google TensorFlow和其他三项结果的图表:
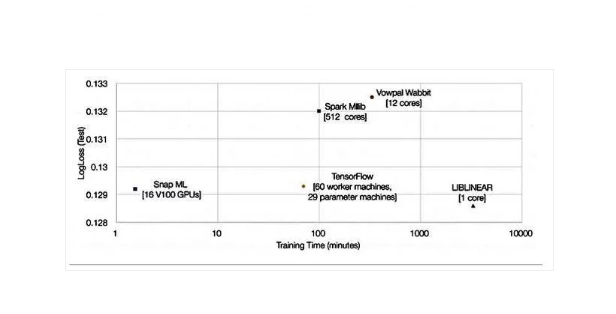
TensorFlow的46倍速度改进是不可忽视的。他们把它归因于什么?
他们表示,Snap ML具有多层次的并行性,可以在集群中的不同节点间分配工作负载,利用加速器单元,以及单个计算单元的多核心并行性:
1.首先,数据分布在集群中的各个工作节点上
2.在节点数据上,主机中央处理器与CPU和GPU并行运行的GPU之间的分割
3.数据被发送到GPU中的多个内核,并且CPU工作负载是多线程的
Snap ML具有嵌套的分层算法特性,可以利用这三个级别的并行性。
IBM研究人员并没有声称TensorFlow没有利用并行性,也没有提供Snap ML和TensorFlow之间的任何比较。
但是他们说:“我们实施专门的解算器,旨在利用GPU的大规模并行架构,同时尊重GPU内存中的数据局部性,以避免大量数据传输开销。”
该报告称,采用NVLink 2.0接口的AC922服务器比采用其Tesla GPU的PCIe接口的至强服务器(至强金6150 CPU @ 2.70GHz)要快。“对于基于PCle的设置,我们测量的有效带宽为11.8GB/秒,对于基于NVLink的设置,我们测量的有效带宽为68.1GB/秒。”
训练数据被发送到GPU,以在那里进行处理。NVLink系统会比PCIe系统更快地向GPU发送块,时间为55m/s,而不是318m/s。
IBM团队还表示:“当我们应用于稀疏数据结构时,我们对系统中使用的算法进行了一些新的优化。”
从总体上看,Snap ML似乎更能利用Nvidia GPU的优势,通过NVLink更快地将数据传输到它们,而不是通过商用x86服务器的PCIe链接。我们不知道POWER9 CPU与Xeons的速度相比如何;就我们所知,IBM还没有公开发布任何POWER9与Xeon SP的直接比较。
我们也不能说Snap ML比TensorFlow好多少,直到我们在相同的硬件配置上运行两个吸盘。
不管原因是什么,46x的降幅都让人印象深刻,并且给了IBM很大的空间来推动其POWER9服务器,作为插入Nvidia GPU,运行Snap ML库以及进行机器学习的场所。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消