


















使用Tensorflow对象检测接口进行像素级分类

Tensorflow对象检测的Mask RCNN
实例分割
实例分段(Instance segmentation)是对象检测的扩展,其中二进制掩码(即对象与背景)与每个边界框相关联。这允许有关框内对象范围更细粒度的信息。
那么我们在哪些情况需要这种额外的粒度呢?很容易想到的例子有:
1)自驾车 - 可能需要确切知道在路上的其他车辆或者横穿马路的行人的位置
2)机器人系统 - 知道对象两部分的确切位置并结合起来,可能会使他表现得更好
有几种实现实例分段的算法,而Tensorflow对象检测API所使用的算法是Mask RCNN。
Mask RCNN
让我们先从Mask RCNN开始。
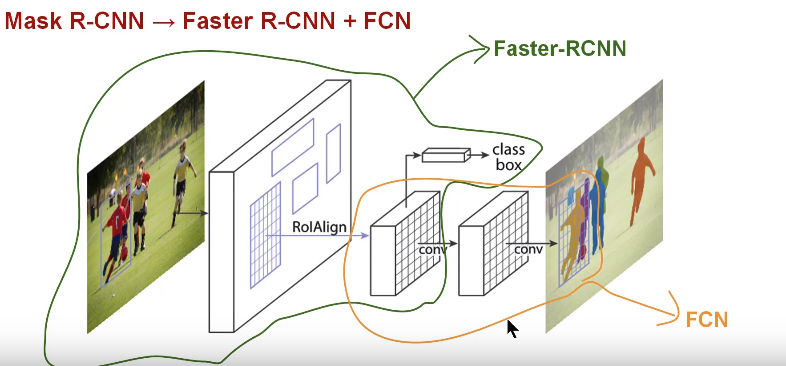
Mask RCNN架构
Faster RCNN是用于物体检测的算法。它由两个阶段组成。第一阶段称为RPN(Region Proposal Network),提出候选的对象边界框。第二阶段才是Fast R-CNN的实质,它使用RoIPool从每个候选框中提取特征,并执行分类和边界框回归。两个阶段使用的特征可以共享以加快推断速度。
Mask R-CNN的概念非常简单:Faster RCNN每个候选对象具有两个输出,一个类标签和一个边界框补偿;为此,我们添加了另一个阶段输出对象的mask,mask 是一个二进制掩码,用于指示对象位于边界框中的像素。于类和边界框输出不同的是,它需要提取对象更精细的空间布局。为此,Mask RCNN使用了Mask RCNN论文中的全卷积网络(FCN)。
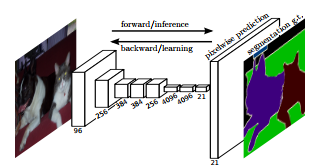
全卷积网络架构
FCN是一种常用的语义分割算法。该模型使用各种卷积和最大池层,首先将图像解压缩至其原始大小的1/32。然后在这个粒度级别上进行类别预测。最后,它使用采样和去卷积层将图像调整到原始尺寸。
所以简而言之,我们可以说Mask RCNN将两个网络(Faster RCNN和FCN)结合在一个大型架构中。模型的损失函数是在进行分类、生成边界框和生成掩码时的总损失。
关于Mask RCNN的一些额外的改进(这使它比FCN更准确)可以阅读他们的论文。
实现
使用图像测试
要使用图像测试此模型,可以利用tensorflow共享的代码。我测试了他们最轻量级的模型 - mask_rcnn_inception_v2_coco。只需下载模型并升级到tensorflow 1.5(升级很重要!)。示例结果如下:

在风筝图像上面具RCNN
代码链接:https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
使用视频测试
更有趣的练习是在视频上运行目标检测模型。我用keepvid从YouTube上下载了几个视频。我很喜欢用于处理视频文件的moviepy。
主要步骤是:
- 使用VideoFileClip函数从视频中提取每个帧
- fl_image函数有一个非常棒的功能,它可以在得到图像后将其替换为修改后的图像。我用它来对从视频中提取的每个图像运行对象检测
- 将修改后的剪辑图像合并到一个新的视频中
代码链接:https://github.com/priya-dwivedi/Deep-Learning/blob/master/Mask_RCNN/Mask_RCNN_Videos.ipynb
其他
想要进一步探索此API:
- 尝试更精确、高负荷的对象检测模型,看看它们有多大的差异
- 使用API在自定义数据集上训练Mask RCNN
参考
Mask RCNN论文:https://arxiv.org/pdf/1703.06870.pdf
Tensorflow对象检测Github:https://github.com/tensorflow/models/tree/master/research/object_detection
COCO数据集:http://mscoco.org/home/









