











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌新技术:神经优化器搜索,自动找到可解释的优化方法
2018年03月30日 由 yuxiangyu 发表
647163
0
如今,深度学习模型已经部署在众多谷歌产品中,如搜索、翻译和照片等。而在训练深度学习模型时,优化方法的选择至关重要。例如,随机梯度下降在大多情况下都很有效,但更先进的优化器可能会更快,特别是在训练非常“深”的网络时。然而,由于优化问题的非凸性,为神经网络提供新的优化器十分具有挑战性。在Google Brain团队中,我们想看看是否可能用类似于AutoML如何用于发现新的有竞争力的神经网络架构的方法,自动化发现新的优化器的过程。
在论文“ Neural Optimizer Search with Reinforcement Learning ”中,我们提出了一种使用深度学习架构发现优化方法的方法 — 神经优化器搜索(Neural Optimizer Search)。使用这种方法,我们发现了两种新的优化器PowerSign和AddSign,它们在各种不同的任务和架构上具有竞争力,包括ImageNet分类和Google的神经机器翻译系统。为了帮助其他人从这项工作中受益,我们将这些优化器加入了Tensorflow。
神经优化器搜索利用一个递归神经网络控制器,它可以访问通常与优化相关的简单原语(primitives)列表。例如,这些原语包括梯度或梯度的运行平均值,并具有超过1*10 10 种可能组合的搜索空间。控制器然后为这个搜索空间中的候选优化器或更新规则生成计算图。
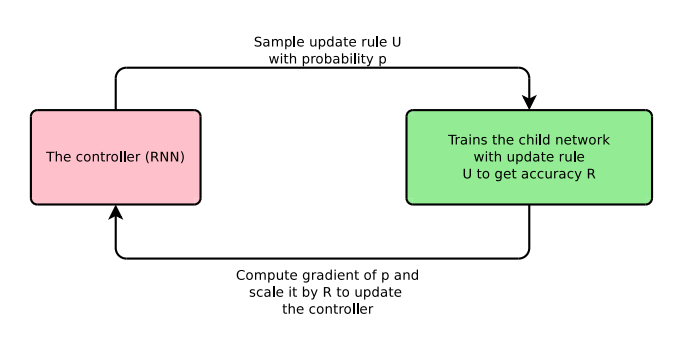
在论文中,提出的候选更新规则(U)用于在CIFAR10上训练一个子卷积神经网络几个周期,最终的验证准确性(R)作为奖励馈给控制器。控制器通过强化学习进行训练最大化所抽取的更新规则的验证准确性。这个过程如下图所示。
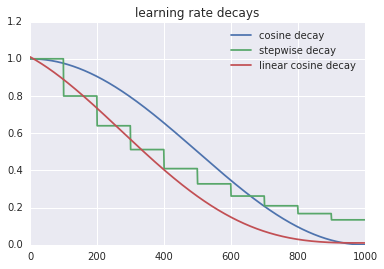
有趣的是,我们找到的这些优化器是可解释的。例如,在我们发布的PowerSign优化器中,每次更新都会比较梯度信号和其运行平均值,并根据这两个值是否一致来调整步长。这背后的直觉是,如果这些值一致,那么它对正确的更新方向更为确定,因此步长可以更大。我们还发现了一个简单的学习率衰减方案,线性余弦衰减( linear cosine decay),我们发现可以让收敛更快。
神经优化搜索找到了几个优化器,它们的表现胜过了在小型ConvNet模型中常用的优化器。在一些可以很好迁移到其他任务优化器中,我们发现PowerSign和AddSign将最先进ImageNet mobile-sized模型的前1和前5的准确性提高了0.4%。他们在Google的神经机器翻译系统上也运行良好,英语对德语翻译任务的双语评估指标(BLEU)增加了0.7。
让我们感到兴奋的是,神经优化器搜索不仅可以提高机器学习模型的性能,还可能发现新的可解释的方程和发现。我们希望在Tensorflow中开源的这些优化器会对机器学习从业者有用。
论文:https://arxiv.org/pdf/1709.07417.pdf
在论文“ Neural Optimizer Search with Reinforcement Learning ”中,我们提出了一种使用深度学习架构发现优化方法的方法 — 神经优化器搜索(Neural Optimizer Search)。使用这种方法,我们发现了两种新的优化器PowerSign和AddSign,它们在各种不同的任务和架构上具有竞争力,包括ImageNet分类和Google的神经机器翻译系统。为了帮助其他人从这项工作中受益,我们将这些优化器加入了Tensorflow。
神经优化器搜索利用一个递归神经网络控制器,它可以访问通常与优化相关的简单原语(primitives)列表。例如,这些原语包括梯度或梯度的运行平均值,并具有超过1*10 10 种可能组合的搜索空间。控制器然后为这个搜索空间中的候选优化器或更新规则生成计算图。
在论文中,提出的候选更新规则(U)用于在CIFAR10上训练一个子卷积神经网络几个周期,最终的验证准确性(R)作为奖励馈给控制器。控制器通过强化学习进行训练最大化所抽取的更新规则的验证准确性。这个过程如下图所示。
使用迭代过程来发现新优化器的神经优化器搜索示意图。
有趣的是,我们找到的这些优化器是可解释的。例如,在我们发布的PowerSign优化器中,每次更新都会比较梯度信号和其运行平均值,并根据这两个值是否一致来调整步长。这背后的直觉是,如果这些值一致,那么它对正确的更新方向更为确定,因此步长可以更大。我们还发现了一个简单的学习率衰减方案,线性余弦衰减( linear cosine decay),我们发现可以让收敛更快。
图表比较了余弦衰减,阶梯衰减和线性余弦衰减的学习率衰减函数。
神经优化搜索找到了几个优化器,它们的表现胜过了在小型ConvNet模型中常用的优化器。在一些可以很好迁移到其他任务优化器中,我们发现PowerSign和AddSign将最先进ImageNet mobile-sized模型的前1和前5的准确性提高了0.4%。他们在Google的神经机器翻译系统上也运行良好,英语对德语翻译任务的双语评估指标(BLEU)增加了0.7。
让我们感到兴奋的是,神经优化器搜索不仅可以提高机器学习模型的性能,还可能发现新的可解释的方程和发现。我们希望在Tensorflow中开源的这些优化器会对机器学习从业者有用。
论文:https://arxiv.org/pdf/1709.07417.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消