


















动手实现会写数字的神经网络—半监督学习和生成式对抗网络介绍
在1889年,梵高画了这个美丽的艺术品:星月夜。如今,我的生成式对抗网络GAN模型只使用20%的标签数据,学会了画MNIST数字!它是怎么实现的?让我们动手做做看。

半监督学习
大多数深度学习分类器需要大量的标签样本才能很好地泛化,但获取这些数据是的过程往往很艰难。为了解决这个限制,半监督学习被提出,它是利用少量标记数据和大量未标记数据的分类技术。许多机器学习研究人员发现,将未标记数据与少量标记数据结合使用时,可以显著提高学习准确性。在半监督学习中,生成式对抗网络GAN表现出了很大的潜力,其中分类器可以用很少的标签数据取得良好的表现。
生成式对抗网络GAN的背景
生成式对抗网络GAN是深度生成模型的一种。它们特别有趣,因为它们没有明确表示数据所在空间的概率分布。而是通过从中抽取样本,提供了一些不直接与这种概率分布不直接相关的方法。
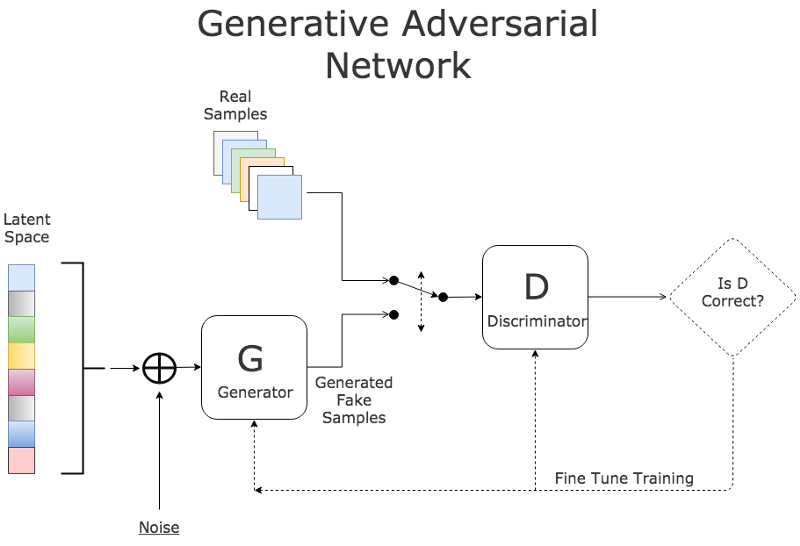
普通生成式对抗网络GAN架构
生成式对抗网络GAN的基本原理是在两个“玩家”之间建立一场比赛:
- 生成器(G):取随机噪声z作为输入并输出图像x。它的参数被调整以让它产生的假图像从判别器中获得高分。
- 判别器(D):获取图像X作为输入,并输出一个反映了它对于这是否是真实图像的信心得分。它的参数被调整为:当有真实图像馈送时反馈高分,并且发生器馈送假图像时会反馈低分。
现在,让我们来稍微讨论一下生成式对抗网络GAN最重要的应用之一,半监督学习。
直觉
普通判别器架构只有一个输出神经元用于分类R / F概率(对/错)。我们同时训练两个网络并在训练完成后丢弃判别器,因为它仅用于改进发生器。
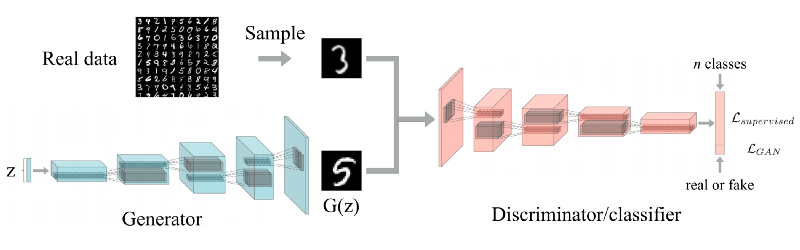
对于半监督任务,除了R / F神经元之外,判别器现在将具有10个用于MNIST数字分类的神经元。而且,这次他们的角色会改变,我们可以在训练后丢弃生成器,其唯一目标是生成未标记的数据以提高判别器的性能。
现在判别器成为了11个类的分类器,其中1个神经元(R / F神经元)代表假数据输出,另外10个代表具有类的实际数据。你必须牢记以下几点:
- 当来自数据集的真的无监督(或者说标签)数据被馈送时,要保证R / F神经元输出标签= 0
- 当来自发生器的假的无监督数据被馈送时,要保证R / F神经元输出标签= 1
- 当真实有监督数据被馈送时,要保证R / F输出标签= 0并且相应的标签输出= 1
不同数据来源的组合将有助于判别器的分类更精确。
架构
现在我们动手进行编码。
判别器
下面的架构与DCGAN 论文中提出的架构类似。我们使用跨卷积(strided convolutions)来减少特征向量的维度,而不是任何池化层,并且为所有层应用一系列的leaky_relu,dropout和BN来稳定学习。输入层和最后一层中BN被舍弃(为了特征匹配)。最后,我们执行全局平均池化(Global Average Pooling)以取得特征向量空间维度上的平均值。这可以将张量维度压缩为单个值。在扁平化了特征之后,为了多类输出增加一个11个类的稠密层和softmax激活函数。
def discriminator(x, dropout_rate = 0., is_training = True, reuse = False):
# input x -> n+1 classes
with tf.variable_scope('Discriminator', reuse = reuse):
# x = ?*64*64*1
#Layer 1
conv1 = tf.layers.conv2d(x, 128, kernel_size = [4,4], strides = [2,2],
padding = 'same', activation = tf.nn.leaky_relu, name = 'conv1') # ?*32*32*128
#No batch-norm for input layer
dropout1 = tf.nn.dropout(conv1, dropout_rate)
#Layer2
conv2 = tf.layers.conv2d(dropout1, 256, kernel_size = [4,4], strides = [2,2],
padding = 'same', activation = tf.nn.leaky_relu, name = 'conv2') # ?*16*16*256
batch2 = tf.layers.batch_normalization(conv2, training = is_training)
dropout2 = tf.nn.dropout(batch2, dropout_rate)
#Layer3
conv3 = tf.layers.conv2d(dropout2, 512, kernel_size = [4,4], strides = [4,4],
padding = 'same', activation = tf.nn.leaky_relu, name = 'conv3') # ?*4*4*512
batch3 = tf.layers.batch_normalization(conv3, training = is_training)
dropout3 = tf.nn.dropout(batch3, dropout_rate)
# Layer 4
conv4 = tf.layers.conv2d(dropout3, 1024, kernel_size=[3,3], strides=[1,1],
padding='valid',activation = tf.nn.leaky_relu, name='conv4') # ?*2*2*1024
# No batch-norm as this layer's op will be used in feature matching loss
# No dropout as feature matching needs to be definite on logits
# Layer 5
# Note: Applying Global average pooling
flatten = tf.reduce_mean(conv4, axis = [1,2])
logits_D = tf.layers.dense(flatten, (1 + num_classes))
out_D = tf.nn.softmax(logits_D)
return flatten,logits_D,out_D
发生器
发生器架构旨在模仿判别器的空间输出。使用部分跨卷积来增加表示的空间维度。噪声的四维张量的输入z被馈送,它经过转置卷积,relu,BN(输出层除外)和dropout操作。最后,tanh激活将输出图像映射到(-1,1)范围内。
def generator(z, dropout_rate = 0., is_training = True, reuse = False):
# input latent z -> image x
with tf.variable_scope('Generator', reuse = reuse):
#Layer 1
deconv1 = tf.layers.conv2d_transpose(z, 512, kernel_size = [4,4],
strides = [1,1], padding = 'valid',
activation = tf.nn.relu, name = 'deconv1') # ?*4*4*512
batch1 = tf.layers.batch_normalization(deconv1, training = is_training)
dropout1 = tf.nn.dropout(batch1, dropout_rate)
#Layer 2
deconv2 = tf.layers.conv2d_transpose(dropout1, 256, kernel_size = [4,4],
strides = [4,4], padding = 'same',
activation = tf.nn.relu, name = 'deconv2')# ?*16*16*256
batch2 = tf.layers.batch_normalization(deconv2, training = is_training)
dropout2 = tf.nn.dropout(batch2, dropout_rate)
#Layer 3
deconv3 = tf.layers.conv2d_transpose(dropout2, 128, kernel_size = [4,4],
strides = [2,2], padding = 'same',
activation = tf.nn.relu, name = 'deconv3')# ?*32*32*256
batch3 = tf.layers.batch_normalization(deconv3, training = is_training)
dropout3 = tf.nn.dropout(batch3, dropout_rate)
#Output layer
deconv4 = tf.layers.conv2d_transpose(dropout3, 1, kernel_size = [4,4],
strides = [2,2], padding = 'same',
activation = None, name = 'deconv4')# ?*64*64*1
out = tf.nn.tanh(deconv4)
return out
模型损失
我们首先通过将实际标签附加为零来准备整个批次的扩展标签。这样做是为了在标记数据馈送时,R / F神经元的输出为0。未标记数据的判别器损失可以被认为是一个二元sigmoid损失,通过将R / F神经元输出为1声明假图像,而真实图像输出为0。
### Discriminator loss ###
# Supervised loss -> which class the real data belongs to
temp = tf.nn.softmax_cross_entropy_with_logits_v2(logits = D_real_logit,
labels = extended_label)
# Labeled_mask and temp are of same size = batch_size where temp is softmax cross_entropy calculated over whole batch
D_L_Supervised = tf.reduce_sum(tf.multiply(temp,labeled_mask)) / tf.reduce_sum(labeled_mask)
# Multiplying temp with labeled_mask gives supervised loss on labeled_mask
# data only, calculating mean by dividing by no of labeled samples
# Unsupervised loss -> R/F
D_L_RealUnsupervised = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = D_real_logit[:, 0], labels = tf.zeros_like(D_real_logit[:, 0], dtype=tf.float32)))
D_L_FakeUnsupervised = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = D_fake_logit[:, 0], labels = tf.ones_like(D_fake_logit[:, 0], dtype=tf.float32)))
D_L = D_L_Supervised + D_L_RealUnsupervised + D_L_FakeUnsupervised
发生器损失是fake_image损失与特征匹配损失的组合,前者错误的将R / F神经元输出断言为0,后者惩罚训练数据上一组特征的平均值与生成样本中这组特征的平均值之间的平均绝对误差。
### Generator loss ###
# G_L_1 -> Fake data wanna be real
G_L_1 = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = D_fake_logit[:, 0],labels = tf.zeros_like(D_fake_logit[:, 0], dtype=tf.float32)))
# G_L_2 -> Feature matching
data_moments = tf.reduce_mean(D_real_features, axis = 0)
sample_moments = tf.reduce_mean(D_fake_features, axis = 0)
G_L_2 = tf.reduce_mean(tf.square(data_moments-sample_moments))
G_L = G_L_1 + G_L_2
训练
训练图像从[batch_size,28,28,1]调整为[batch_size,64,64,1]以适应发生器和判别器架构。计算损失,准确性和生成样本,并观察每个周期的改进。
for epoch in range(epochs):
train_accuracies, train_D_losses, train_G_losses = [], [], []
for it in range(no_of_batches):
batch = mnist_data.train.next_batch(batch_size, shuffle = False)
# batch[0] has shape: batch_size*28*28*1
batch_reshaped = tf.image.resize_images(batch[0], [64, 64]).eval()
# Reshaping the whole batch into batch_size*64*64*1 for disc/gen architecture
batch_z = np.random.normal(0, 1, (batch_size, 1, 1, latent))
mask = get_labeled_mask(labeled_rate, batch_size)
train_feed_dict = {x : scale(batch_reshaped), z : batch_z,
label : batch[1], labeled_mask : mask,
dropout_rate : 0.7, is_training : True}
#The label provided in dict are one hot encoded in 10 classes
D_optimizer.run(feed_dict = train_feed_dict)
G_optimizer.run(feed_dict = train_feed_dict)
train_D_loss = D_L.eval(feed_dict = train_feed_dict)
train_G_loss = G_L.eval(feed_dict = train_feed_dict)
train_accuracy = accuracy.eval(feed_dict = train_feed_dict)
train_D_losses.append(train_D_loss)
train_G_losses.append(train_G_loss)
train_accuracies.append(train_accuracy)
tr_GL = np.mean(train_G_losses)
tr_DL = np.mean(train_D_losses)
tr_acc = np.mean(train_accuracies)
print ('After epoch: '+ str(epoch+1) + ' Generator loss: '
+ str(tr_GL) + ' Discriminator loss: ' + str(tr_DL) + ' Accuracy: ' + str(tr_acc))
gen_samples = fake_data.eval(feed_dict = {z : np.random.normal(0, 1, (25, 1, 1, latent)), dropout_rate : 0.7, is_training : False})
# Dont train batch-norm while plotting => is_training = False
test_images = tf.image.resize_images(gen_samples, [64, 64]).eval()
show_result(test_images, (epoch + 1), show = True, save = False, path = '')
结论
由于GPU的限制,训练已完成5个周期和20%的 labeled_rate。想要获得更好的结果,建议使用较小的label_rate的训练更多周期。
完整代码:https://github.com/raghav64/SemiSuper_GAN/blob/master/SSGAN.py
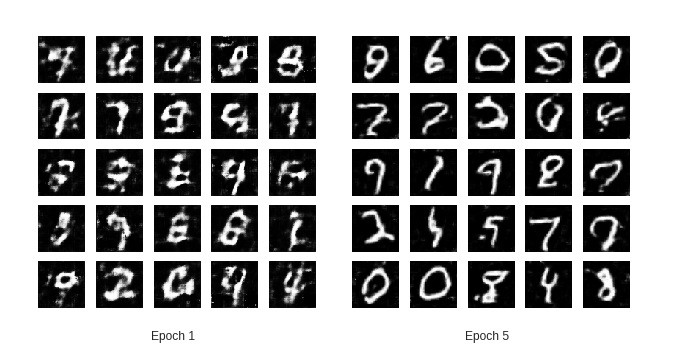
训练结果









