











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深度学习图像识别项目(上):如何快速构建图像数据集
2018年04月14日 由 yuxiangyu 发表
781623
0
在你还是个孩子时是否也是一个神奇宝贝迷?是否还记得里面的各种神奇宝贝,以及小智手中可以自动识别神奇宝贝的图鉴(Pokedex)?本文的作者带你利用计算机视觉技术,在手机中构建了一个一模一样的应用程序。
在我还是孩子时,我一直认为Pokedex特别的酷。所以,现在我带领大家建立一个利用计算机视觉技术的Pokedex。
本系列分三部分,完成后你将拥有自己的Pokedex:
- 本文中,我们使用Bing图像搜索API来构建我们的图像数据集。
- 下一篇,我将演示如何进行实现,使用Keras训练CNN来识别每个神奇宝贝。
- 最后,我们将使用我们训练好的Keras模型将其嵌入到iPhone应用程序中。
如何快速构建深度学习图像数据集
为了构建我们的深度学习图像数据集,我们需要利用微软的Bing图像搜索API,这是微软认知服务的一部分,用于将AI的视觉识别、语音识别,文本识别等内容带入应用程序。
我之前曾经抽取Google图像来构建自己的数据集,但这个过程十分麻烦。
于是,我正在寻找了一种解决方案,使我可以以编程方式通过查询下载图像。我可不想让人用浏览器搜索和下载图像文件的方法。
于是,我决定试试微软的Bing图像搜索API。这个API非常适合我们,并且容易上手。
它有30天的免费试用期,并且API看起来价格合理(我还没付费)。
在今天的博客文章的中,我将演示如何利用Bing图像搜索API快速构建适合深度学习的图像数据集。
创建认知服务帐户
在本节中,我将简要介绍如何获免费的Bing图片搜索API帐户。注册过程很简单,但开始注册流程的页面有点难找。
https://azure.microsoft.com/en-us/try/cognitive-services/?api=bing-image-search-api
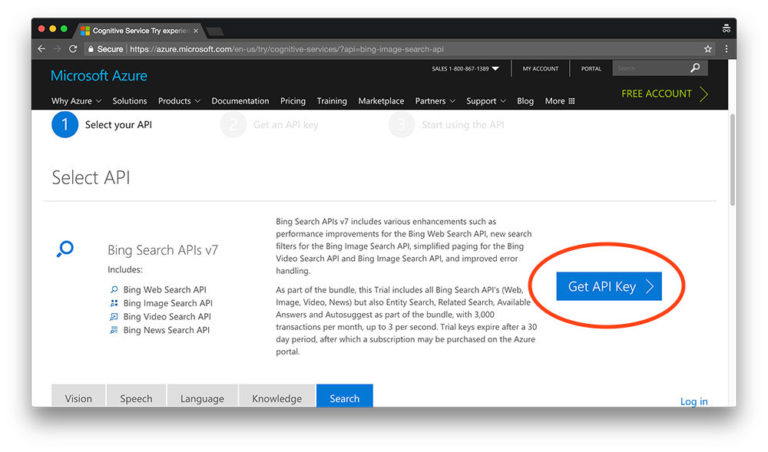
从截图中我们可以看到,该试用版包含了Bing的所有搜索API,每月总共有3,000次处理次数,足以满足我们构建第一个深度学习图像数据集需求。
要注册Bing图像搜索API,请单击“Get API Key”按钮。
在这里你可以通过登录你的微软,Facebook,LinkedIn或GitHub账户进行注册(为了简单起见,我使用了GitHub)。
完成注册过程后,你的界面大致如下:
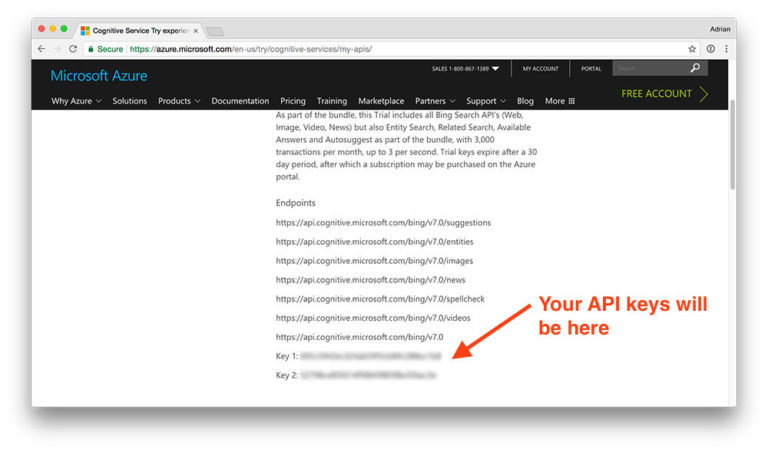
Microsoft Bing API端点以及该API的密钥。
在这里,你可以看到我的Bing搜索端点(endpoints)列表,包括我的两个API密匙(打码的那两行)。记下你的API密钥备用。
使用Python构建深度学习数据集
现在我们已经注册了Bing图像搜索API,我们准备构建深度学习数据集。
阅读文档
在继续之前,我建议你在浏览器中打开以下两个Bing图像搜索API文档页面:
- https://docs.microsoft.com/en-us/azure/cognitive-services/bing-image-search/quickstarts/python
- https://docs.microsoft.com/en-us/azure/cognitive-services/bing-web-search/paging-webpages
如果你对API的工作原理或我们在提出搜索请求后如何使用API有任何疑问,可以参考它们。
安装REQUESTS包
如果系统上未安装requests,则可以通过pip进行安装:
pip install requests
requests包使用户能够无比轻松为我们做出的HTTP请求,它使我们不必花精力处理与Python的冲突,优雅的处理请求。
此外,如果你正在使用Python虚拟环境,请确保在安装请求之前使用 workon命令访问环境 :
workon your_env_name
pip install requests
创建你的Python脚本来下载图像
现在,开始编码。创建一个新脚本,将其命名为 search_bing_api .py ,插入以下代码
# import the necessary packages
from requests import exceptions
import argparse
import requests
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-q", "--query", required=True,
help="search query to search Bing Image API for")
ap.add_argument("-o", "--output", required=True,
help="path to output directory of images")
args = vars(ap.parse_args())
第2-6行处理导入此脚本所需的包。你需要在虚拟环境中安装OpenCV和requests 。
接下来,我们解析两个命令行参数:
- --query:你正在使用的图片搜索查询,可能是诸如 “皮卡丘”,“圣诞老人”之类的任何内容。
- --output:图像的输出目录。我个人的偏好是将图像按类分成单独的分目录,所以一定要指定你想要图像进入的正确文件夹。
你不需要修改此脚本的命令行参数部分(第9-14行)。这些是你为脚本提供的运行时输入。
从那里,我们来配置一些全局变量:
# set your Microsoft Cognitive Services API key along with (1) the
# maximum number of results for a given search and (2) the group size
# for results (maximum of 50 per request)
API_KEY = "YOUR_API_KEY_GOES_HERE"
MAX_RESULTS = 250
GROUP_SIZE = 50
# set the endpoint API URL
URL = "https://api.cognitive.microsoft.com/bing/v7.0/images/search"
该脚本必须修改的一部分是API_KEY。你只需将API密钥粘贴到该变量的引号内即可。
你也可以修改 MAX_RESULTS 和 GROUP_SIZE 进行搜索。在这里,我将结果限制为前 250 张图片,并根据Bing API返回每个请求最大图像数量( 50)。
你可以将 GROUP_SIZE 参数视为每页返回的搜索结果的数量。因此,如果我们总共想要250张图片,那么我们需要浏览5页,每页50张。
在训练CNN时,我希望每个类都有约1000个图像,但这仅仅是一个示例。随意下载尽可能多的图片,只需要注意:
- 你下载的所有图片仍应与查询相关。
- 你不会突破Bing免费API的限制(否则你需要开始为服务付费)。
现在,我们准备好处理所有可能遇到的异常,这些异常可能会在尝试获取图像时发生。首先列出可能遇到的异常:
# when attempting to download images from the web both the Python
# programming language and the requests library have a number of
# exceptions that can be thrown so let's build a list of them now
# so we can filter on them
EXCEPTIONS = set([IOError, FileNotFoundError,
exceptions.RequestException, exceptions.HTTPError,
exceptions.ConnectionError, exceptions.Timeout])
在处理网络请求时,可能会抛出一些异常,所以我们在第5-7行中列出它们。我们会尝试抓取他们,然后进行处理。
下面,让我们初始化搜索参数并进行搜索:
# store the search term in a convenience variable then set the
# headers and search parameters
term = args["query"]
headers = {"Ocp-Apim-Subscription-Key" : API_KEY}
params = {"q": term, "offset": 0, "count": GROUP_SIZE}
# make the search
print("[INFO] searching Bing API for '{}'".format(term))
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
# grab the results from the search, including the total number of
# estimated results returned by the Bing API
results = search.json()
estNumResults = min(results["totalEstimatedMatches"], MAX_RESULTS)
print("[INFO] {} total results for '{}'".format(estNumResults,
term))
# initialize the total number of images downloaded thus far
total = 0
在 第3-5行,我们初始化搜索参数。请务必根据需要查看API文档。
然后,我们执行搜索(9-10行)并以JSON格式抓取结果(第14行)。
我们计算并将预计的结果数打印到终端(15-16行)。
我们要保留我们下载图像的一个计数器,所以我初始化了total(20)。
现在是时候循环遍历在GROUP_SIZE 块的结果了 :
# loop over the estimated number of results in `GROUP_SIZE` groups
for offset in range(0, estNumResults, GROUP_SIZE):
# update the search parameters using the current offset, then
# make the request to fetch the results
print("[INFO] making request for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
params["offset"] = offset
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
results = search.json()
print("[INFO] saving images for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
在这里,我们正在循环GROUP_SIZE 批处理结果的估计数量, 因为这是API允许的(第2行)。
当我们调用requests.get去获取JSON blob时,当前offset作为参数传递(8)。
让我们尝试保存当前批次的图像:
# loop over the results
for v in results["value"]:
# try to download the image
try:
# make a request to download the image
print("[INFO] fetching: {}".format(v["contentUrl"]))
r = requests.get(v["contentUrl"], timeout=30)
# build the path to the output image
ext = v["contentUrl"][v["contentUrl"].rfind("."):]
p = os.path.sep.join([args["output"], "{}{}".format(
str(total).zfill(8), ext)])
# write the image to disk
f = open(p, "wb")
f.write(r.content)
f.close()
# catch any errors that would not unable us to download the
# image
except Exception as e:
# check to see if our exception is in our list of
# exceptions to check for
if type(e) in EXCEPTIONS:
print("[INFO] skipping: {}".format(v["contentUrl"]))
continue
在这里,我们将循环遍历当前批次的图像,并将每个单独的图像下载到我们的输出文件夹中。
我们建立一个try-catch块,以便我们可以捕捉到我们之前在脚本中定义的异常。如果我们遇到异常,我们将跳过那个图像(第4 行和 第21-26行)。
在try 块内部 ,我们试图通过URL(第7行)获取图像,并为它建立一个路径+文件名(第10-12行)。
然后我们尝试打开并将文件写入磁盘(第15-17行)。这里值得注意的是,我们创建了一个的二进制文件对象,由在 “wb”中的b表示 。我们通过r.content二进制数据 。
接下来,让我们看看OpenCV能否实际加载图像,这意味着(1)图像文件已成功下载,(2)图像路径有效:
# try to load the image from disk
image = cv2.imread(p)
# if the image is `None` then we could not properly load the
# image from disk (so it should be ignored)
if image is None:
print("[INFO] deleting: {}".format(p))
os.remove(p)
continue
# update the counter
total += 1
在这个块中,我们加载2行的图像文件 。
只要图像数据不是None ,我们就更新total并循环回到顶部。
否则,我们调用os.remove,删除无效图像,继续回到循环的顶部,不更新计数器。第6行的if语句可能触发的原因有:下载文件时出现网络错误,未安装合适的图像I / O库等而触发。
下载图像

Bing图像搜索API非常好用,我喜欢它,就像喜欢皮卡丘一样!
现在我们已经编写好了脚本,让我们使用Bing图像搜索API下载深度学习数据集的图像。
就我的情况来说,我正在创建一个dataset目录:
mkdir dataset
下载的所有图像将存储在dataset中 。从那里,执行以下命令来创建子目录并运行搜索“charmander”(小火龙):
$ mkdir dataset/charmander
$ python search_bing_api.py --query "charmander" --output dataset/charmander
[INFO] searching Bing API for 'charmander'
[INFO] 250 total results for 'charmander'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: https://fc06.deviantart.net/fs70/i/2012/355/8/2/0004_c___charmander_by_gaghiel1987-d5oqbts.png
[INFO] fetching: https://th03.deviantart.net/fs71/PRE/f/2010/067/5/d/Charmander_by_Woodsman819.jpg
[INFO] fetching: https://fc05.deviantart.net/fs70/f/2011/120/8/6/pokemon___charmander_by_lilnutta10-d2vr4ov.jpg
...
[INFO] making request for group 50-100 of 250...
[INFO] saving images for group 50-100 of 250...
...
[INFO] fetching: https://38.media.tumblr.com/f0fdd67a86bc3eee31a5fd16a44c07af/tumblr_nbhf2vTtSH1qc9mvbo1_500.gif
[INFO] deleting: dataset/charmander/00000174.gif
在上面的命令中,我正在下载一个常见的小火龙的图像。250张图片中的大部分都会成功下载,但是如上面的输出所示,也会有一些OpenCV无法打开的被删除。
Pikachu(皮卡丘)也这样操作:
$ mkdir dataset/pikachu
$ python search_bing_api.py --query "pikachu" --output dataset/pikachu
[INFO] searching Bing API for 'pikachu'
[INFO] 250 total results for 'pikachu'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: http://www.mcmbuzz.com/wp-content/uploads/2014/07/025Pikachu_OS_anime_4.png
[INFO] fetching: http://images4.fanpop.com/image/photos/23300000/Pikachu-pikachu-23385603-814-982.jpg
[INFO] fetching: http://images6.fanpop.com/image/photos/33000000/pikachu-pikachu-33005706-895-1000.png
...
接着是Squirtle(杰尼龟):
$ mkdir dataset/squirtle
$ python search_bing_api.py --query "squirtle" --output dataset/squirtle
[INFO] searching Bing API for 'squirtle'
[INFO] 250 total results for 'squirtle'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: https://fc03.deviantart.net/fs71/i/2013/082/1/3/007_squirtle_by_pklucario-d5z1gj5.png
[INFO] fetching: https://fc03.deviantart.net/fs70/i/2012/035/b/2/squirtle_by_maii1234-d4oo1aq.jpg
[INFO] fetching: https://3.bp.blogspot.com/-yeK-y_dHCCQ/TWBkDZKi6vI/AAAAAAAAABU/_TVDXBrxrkg/s1600/Leo%2527s+Squirtle.jpg
...
然后是Bulbasaur(妙蛙种子):
$ mkdir dataset/bulbasaur
$ python search_bing_api.py --query "bulbasaur" --output dataset/bulbasaur
[INFO] searching Bing API for 'bulbasaur'
[INFO] 250 total results for 'bulbasaur'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: https://fc06.deviantart.net/fs51/f/2009/261/3/e/Bulbasaur_by_elfaceitoso.png
[INFO] skipping: https://fc06.deviantart.net/fs51/f/2009/261/3/e/Bulbasaur_by_elfaceitoso.png
[INFO] fetching: https://4.bp.blogspot.com/-b-dLFLsHtm4/Tq9265UAmjI/AAAAAAAAHls/CrkUUFrj6_c/s1600/001Bulbasaur+pokemon+firered+leafgreen.png
[INFO] skipping: https://4.bp.blogspot.com/-b-dLFLsHtm4/Tq9265UAmjI/AAAAAAAAHls/CrkUUFrj6_c/s1600/001Bulbasaur+pokemon+firered+leafgreen.png
[INFO] fetching: https://fc09.deviantart.net/fs71/i/2012/088/9/6/bulbasaur_by_songokukai-d4gecpp.png
...
最后是Mewtwo(超梦):
$ mkdir dataset/mewtwo
$ python search_bing_api.py --query "mewtwo" --output dataset/mewtwo
[INFO] searching Bing API for 'mewtwo'
[INFO] 250 total results for 'mewtwo'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: https://sickr.files.wordpress.com/2011/09/mewtwo.jpg
[INFO] fetching: https://4.bp.blogspot.com/-_7XMdCIyKDs/T3f-0h2X4zI/AAAAAAAABmQ/S2904beJlOw/s1600/Mewtwo+Pokemon+Wallpapers+3.jpg
[INFO] fetching: https://2.bp.blogspot.com/-3jDdQdPl1yQ/T3f-61gJXEI/AAAAAAAABmg/AUmKm65ckv8/s1600/Mewtwo+Pokemon+Wallpapers.jpg
...
我们可以通过使用一些find来计算每个查询下载的图像总数 :
$ find . -type d -print0 | while read -d '' -r dir; do
> files=("$dir"/*)
> printf "%5d files in directory %s\n" "${#files[@]}" "$dir"
> done
2 files in directory .
5 files in directory ./dataset
235 files in directory ./dataset/bulbasaur
245 files in directory ./dataset/charmander
245 files in directory ./dataset/mewtwo
238 files in directory ./dataset/pikachu
230 files in directory ./dataset/squirtle
在这里我们可以看到我们每个类大约有230-245个图像。理想情况下,我希望每类有大约1000幅图片,但为了简化示例,我只下载了250个。
修剪深度学习图像数据集
但是,并非我们下载的每个图片都与查询相关。这是手动干预步骤,你需要浏览目录并删掉不相关的图像。
如果你用的是macOS,这个过程可以很快完成。我的做法是打开Finder,然后在“Cover Flow”视图中浏览所有图像:
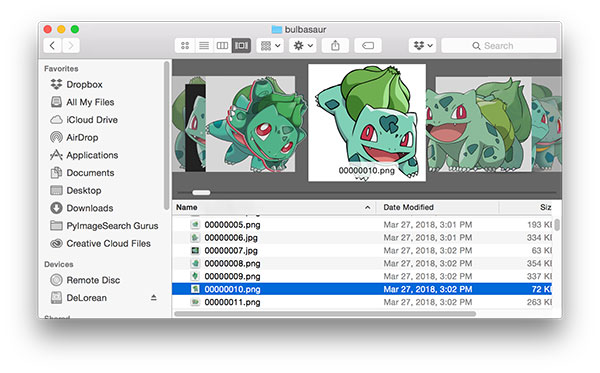
删除不相关的图片后,让我们再做一次图像计数:
$ find . -type d -print0 | while read -d '' -r dir; do
> files=("$dir"/*);
> printf "%5d files in directory %s\n" "${#files[@]}" "$dir";
> done
3 files in directory .
5 files in directory ./dataset
234 files in directory ./dataset/bulbasaur
238 files in directory ./dataset/charmander
239 files in directory ./dataset/mewtwo
234 files in directory ./dataset/pikachu
223 files in directory ./dataset/squirtle
正如你所看到的,我只需要删除每个类的一些图像 - Bing Image Search API工作得非常好!
注意:你还应该考虑删除重复的图像。我没有进行这一步,因为没有太多重复。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消