


















如何使虚拟特技人模仿的动作流畅自然?Berkeley实验室利用RSI结合ET技术另辟蹊径


模拟类人表演一系列动态性强的特技
运动控制问题作为强化学习的基准,深度强化学习方法无论对操纵还是运动型任务都十分有效。然而,经过深度强化学习训练的人体模型常常会作出不自然的行为动作,例如抖动、不对称步态以及过度的四肢动作。那么,我们能将人体模型的行为动作训练得更为自然吗?
从计算机图形学中可以得到大量的灵感,基于物理的自然运动模拟研究已然持续了几十年。对于运动质量的重视往往由影视、视觉效果和游戏应用所激发。多年来,基于物理的人物模型动画的大量研究,开发出了控制器,可为重要任务和角色制作强健且自然的动作。这些方法能够利用人类的洞察力合并特定的任务控制结构,用于提供在运动中人物模型能够达成的较强的感应偏差(例如有限自动机、简化模型及逆动力学)。不过由于这些设计上的问题,控制器只能对应特定的角色或任务,而为行走所开发的控制器可能无法做到更具动态性的技巧,在这一层面人类的洞察力也变得无力。
研究者从两个领域获取灵感,不仅利用深度学习模型带来的普遍性,还有能与计算机图形学中最先进的全身动作模拟争锋的自然动作。首先呈现概念性的简单强化学习框架,使模拟人物从动作参考视频中学习动态和特技,视频以动作捕捉数据记录的形式从真人那里获取。之后展示一个技巧范例,比如旋风踢或后空翻,让模拟人物学习模仿这一技巧。生成动作的策略在动作捕捉中几乎是无法辨别的。
动作模仿
在大多强化学习的基准上,模拟人物往往代表着用简单的模型,粗略模拟出近似于真实世界的动态。因此模拟人物可能倾向于利用模拟中特有的性质,导致生成真实世界中不可能出现的不自然动作。结合更真实的生物力学模型可以得出更多的自然动作,不过构建高逼真模型的确非常有挑战性,出现不自然的动作也很寻常。
可替代的方法便是依照数据处理,捕捉到的人类参照动作提供了自然的动作,训练人物模仿参考动作来实现更为自然的动作。模仿动作数据在计算机动画中有悠久的历史,近期还用深度强化学习做了很多展示。尽管结果看上去更为自然,但想要如实复制大量动作还是远远不够。
因此,训练策略将会是动作模仿任务,模拟人物的目标便是重现已出现过的动态参考动作。每个参考动作由一系列的目标动作由q^0,q^1,…,q^T代表,其中q^t是时步t中的目标动作。奖励机制可将最小二乘法中的动作错误最小化,即目标动作q^t和模拟人物qt动作之间的错误。
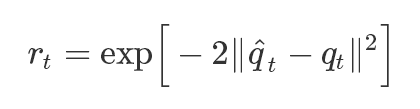
更精细的方法已在动作模仿中应用过,而且对于仅将跟踪误差(伴随着额外的洞察力)最小化相当有效。这些策略是通过用PPO来优化这一目标来训练的。
根据这一框架,可以开发出全套极具挑战性的技能,从运动到杂技,从武术到舞蹈皆可。


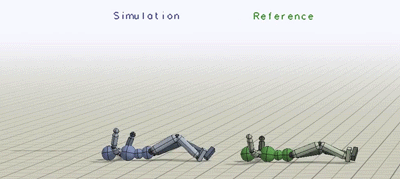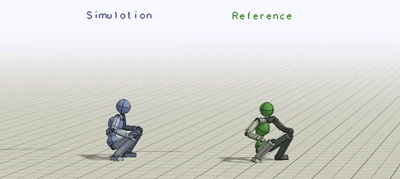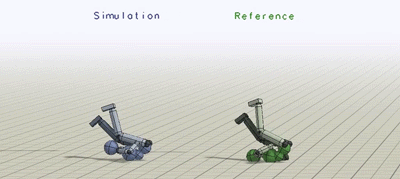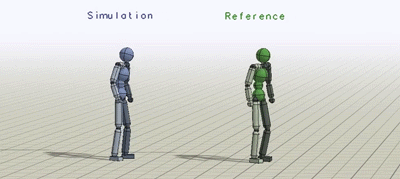

上图为类人学习模拟各种技巧
蓝色人物是模仿者,绿色人物则重复每段动作捕捉视频
动作(从上至下):侧空翻 侧手翻 蹬足上 单手跨栏
接下来,与过去常用的方法(如可生成的对抗性模仿学习,即GAIL)模仿动作捕捉视频的结果相比较。研究者所用的方法比GAIL简单得多,而且能更好地重现参考动作。由此产生的策略避免了许多深度强化学习方法带来的人工仿造感,并使人物能够产生一种真实、带有流动感的跑步姿态。


以上两图为新方法与Merel利用GAIL方法模仿动作捕捉数据的对比
新方法显然比过去利用深度强化学习的模仿更为自然
洞察力
参考状态初始化(RSI)
假设模拟人物要模仿后空翻的动作,它要如何得知做到半空中全程翻转便能获得高回报呢?大多数强化学习算法都是可回顾的,而他们只能通过既有的内容得知哪些状态可获得奖励。在后空翻一例中,模拟人物需要先观察到完美的后空翻轨迹线,才能了解那些状态将会获得高回报。不过后空翻对于起跳和落地这些初始状态要求精密,人物不太可能在随意探索中偶然得到完美的轨迹线。为了给人物提示,每一场实验的开始,研究者将人物状态初始化,从随机的参考动作开始。因此有时候模拟人物会从平地上开始动作,有时则从半空中的翻跳动作开始。这让人物能够在精通每一个状态前,就能记住哪些状态的结果会得到高回报。
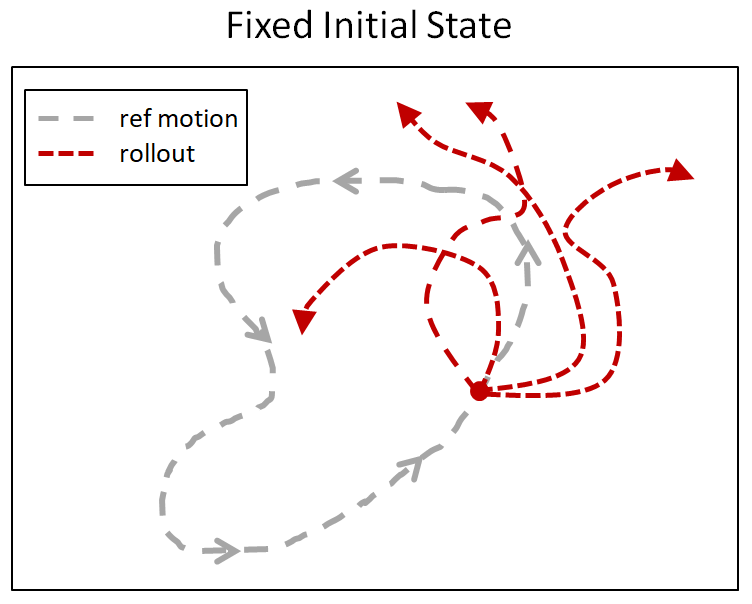
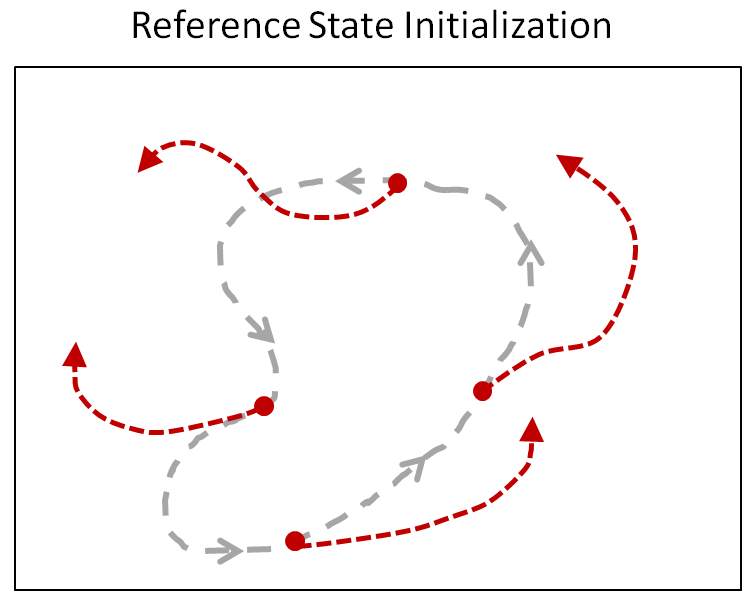
上图:固定初始状态
下图:参考状态初始化(RSI)
RSI通过初始化到随机参考动作状态,为模拟人物提供丰富的初始状态分布
下图是一组对比,利用RSI和没有RSI的后空翻训练,没有RSI技术,模拟人物总是处于固定动作的初始状态,人物并非学习后空翻,只是做后跳的假动作。

对比训练中没有利用RSI或ET的策略
RSI或ET对于学习更具动态的动作十分重要
左图 RSI+ET
中图 没有加入RSI技术
右图 没有加入ET技术
提前终止(ET)
提前终止在强化学习中很常见,经常用来提高模拟效率。一旦人物卡在某个无法做到完美动作的状态,那么这一节实验便可提前终止,不需再把注定失败的动作完成。接下来让我们来看看提前终止实际上会对结果有什么重要影响。仍然以后空翻为例,早期的训练中,策略十分简陋,人物大部分时间都会失败跌倒,人物跌倒后很难恢复到状态。因此那些首次展示的样本,只会是人物徒劳地在地上挣扎的动作。这类似于其他方法中遇到的类平衡性问题,比如监督学习。可以利用尽快终止人物做无用功的状态(比如跌倒)来解决这种问题。与RSI结合,ET会确保大部分包含样本的数据集无限接近参考轨迹。不用ET技术,人物将永远都无法成功完成空翻,只会一次又一次地跌倒,试图在平地上模拟动作。
更多的结果
总的来说,研究者为类人提供不同的参考动作,让其学习了超过24种技巧。
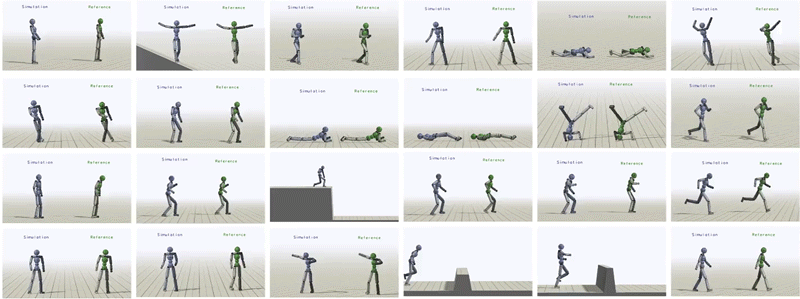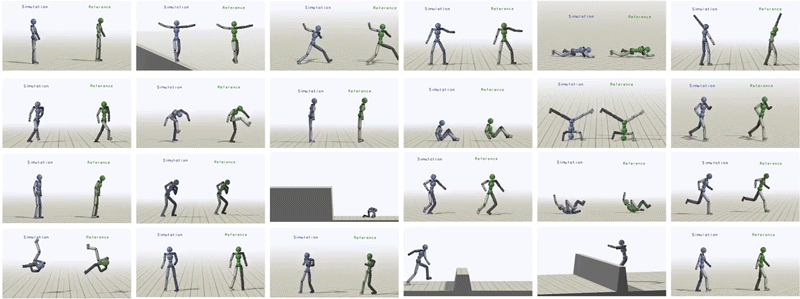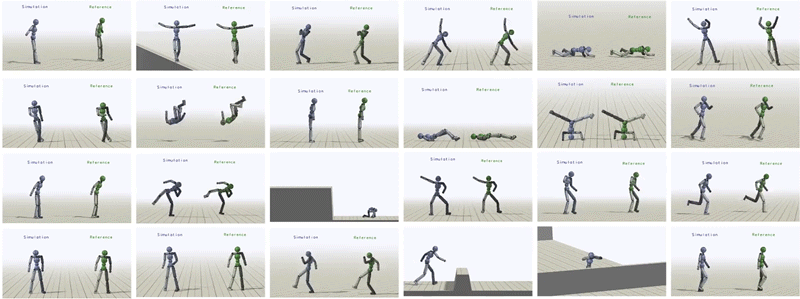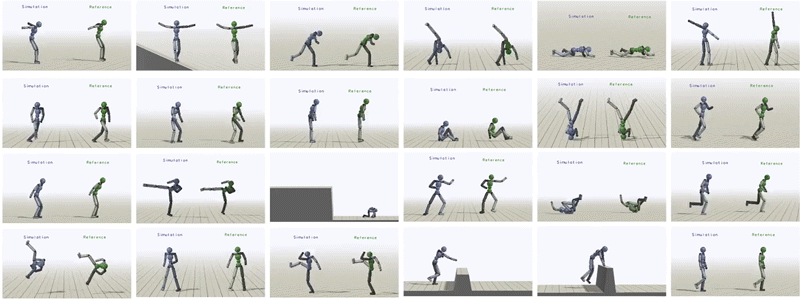
类人受训模仿丰富的技巧
除了动态捕捉视频,类人也被训练完成一些额外的任务,比如踢向随机位置的目标,或是向目标投球。
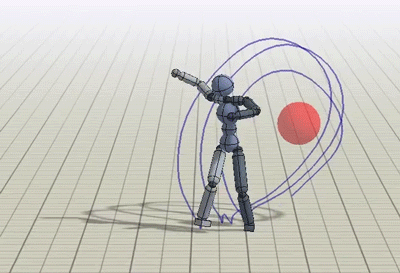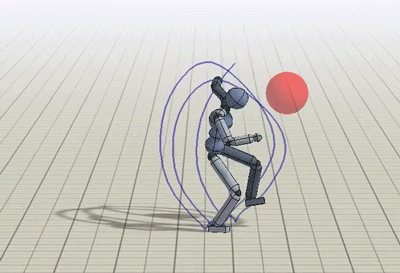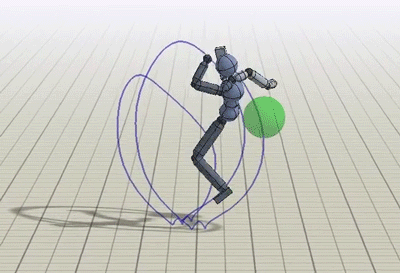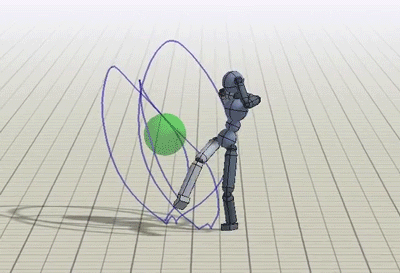

朝随机位置的目标踢腿或投球的策略
研究者也训练Atlas模拟机器人模仿真人动作捕捉视频。尽管Atlas有着非同寻常的形态,但仍然能够重现需要的动作。优势是不仅可以模仿参考动作,还可以不受混乱的环境干扰。


训练Atlas完成旋风踢和后空翻,不受环境干扰
不过如果不使用动作捕捉视频要怎样做?假设我们想要模仿霸王龙(T-Rex),由于许多原因,很难得到霸王龙的动作捕捉视频。所以作为替代,可以让艺术家手工制作关键帧,然后开发出模仿这些关键帧的训练策略。

训练模拟霸王龙模仿艺术家制作的关键帧
不光是霸王龙可以模拟,狮子也行:
模拟狮子
参考动作由Ziva Dynamics提供
当然,龙也可以模拟:

用418D状态空间和94D动作空间模拟龙
方法虽简单,效果却相当好。通过最小化轨迹的错误,可以为各种各样的人物和技巧提供训练策略。这种方法能够有助于现实世界的模拟人物和机器人获得更具动态的动作技能。对于动物和混乱环境那种具有挑战性的动作捕捉来说,从视频这样普遍的来源中模仿动作去探索,的确是令人印象深刻的方法。









