











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌又出新招数,利用深度学习的视听模型进行语音分离
2018年04月12日 由 浅浅 发表
865625
0

即使在嘈杂的环境下,人们也能够将注意力放在特定的人身上,选择性忽略其他人的声音和环境音。这被称作鸡尾酒会效应,对人类来说十分寻常。然而自动语音分离,将音频信号分离到各自的语音源中,仍是计算机面临的重大挑战。
谷歌提出深度学习的视听模型,以从混杂的声音中将单独的语音信号分离出来。在这项工作中,生成出视频,增强特定人群的语音,削弱其它杂音。这一方法需要带有单独音轨的原始视频,只需要用户选择他们想听到视频里哪个人的语音,抑或用基于内容的算法来选择特定的人。研究者认为这种能力能够广泛适用于应用程序,比如在视频会议中进行语音增强以及在视频中进行语音识别,也可用于解决各种听力问题,尤其是在大量语音并存的情况下。
[video width="1920" height="1080" mp4="https://www.atyun.com/uploadfile/2018/04/Looking-to-Listen-Stand-up.mp4"][/video]
这一技术的独特性在于结合听视觉信号来分离输入视频中的语音。直观来看,一个人的嘴部动作,应与他说话时产生的声音相关联,这反过来又能帮助识别出哪部分声音与之对应。在语音混杂的情况下,与仅用音频进行语音分离相对比,视觉信号不仅能显著提高语音分离的质量,更重要的是它能够利用视频中的可视话图像净化分离出的音轨。
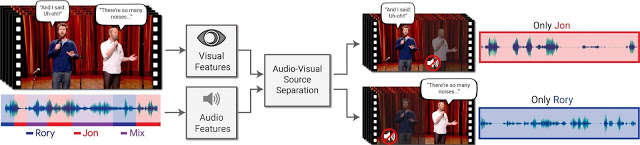
模型方法是输入视频中有一个或更多的人在说话,而语音被其他演讲者或背景噪音干扰。输出则是将输入音轨分解为纯净的语音轨道,每个音轨来自于视频中的每个发声者。
视听语音分离模型(Audio-Visual Speech Separation Model)
为了生成训练案例,研究者首先从YouTube收集了10万个高质量演讲和访谈视频。通过这些视频,研究者抽取了一些语音清晰的演讲片段(例如没有混合的音乐,观众的声音或其他的发言者),并且在视频画面中只有一个可见的人物。结果收集了大约2000个小时的视频片段,每一个片段都只有一个可见人物,且没有任何背景干扰。之后利用这些没被污染的数据生成“综合性鸡尾酒会”场景,即混合大量来自于不同视频的面部和相关的语音,以及从AudioSet获取的无语音的底噪。
利用这些数据,能够训练一个多流的卷积神经网络模型,将混合的场景分离,视频中每一个发言者都可以得到单独的音频流。从每帧中检测到的发声者的脸部缩略图以及音轨频谱图中,提取的视觉特征进行神经网络的输入。在训练过程中,单独的网络学习为视觉和听觉信号编码,然后将它们融合,形成联合的视听表现。用这样的联合表现,神经网络学会为每个发声者输出时频掩模。这样的输出掩模由噪声输入频谱图放大,并转换回时域波形,为每个发生者提取出独立且纯净的语音信号。
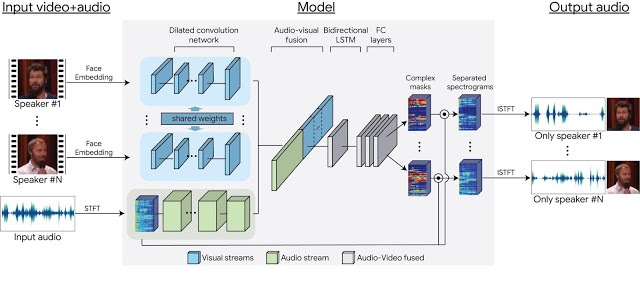
多流、基于神经网络的模型架构
下面是一些用这种方法得到的语音分离和增强结果,非选择的语音和噪音可被完全消除或是削弱到可接受的程度。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2018/04/Looking-to-Listen-Sports-debate.mp4"][/video]
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2018/04/Looking-to-Listen-Noisy-cafeteria.mp4"][/video]
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2018/04/Looking-to-Listen-Video-conferencing.mp4"][/video]
为了强调模型对视觉信息的利用,研究者从谷歌首席执行官Sundar Pichai的同一段视频中选取了两个不同的部分,并将它们并排放在一起。在这个例子中,仅使用音频中包含的特征语音频率来分离语音是非常困难的,然而视听模型在这个极具挑战性的情况下,仍然成功将语音分离开来。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2018/04/Looking-to-Listen-Double-Sundar.mp4"][/video]
在语音识别中的应用
这一方法也可以作为语音识别和自动添加视频字幕的预处理。处理重叠的声场对自动字幕系统来说并不新鲜,但将音频分离开来能够提供更准确而便于阅读的字幕。
[video width="640" height="360" mp4="https://www.atyun.com/uploadfile/2018/04/Looking-to-Listen-Stand-up-captions.mp4"][/video]
总的来说,视听模型技术可应用的范围很广,谷歌也在尝试将这一技术运用到各种产品中。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消