


















TensorFlow团队:TensorFlow Probability的简单介绍
在2018年TensorFlow开发者峰会上,我们(TensorFlow团队)宣布发布TensorFlow Probability:一种使机器学习研究人员及相关从业人员可以快速可靠地利用最先进硬件构建复杂模型的概率编程工具箱。TensorFlow Probability适用的情况包括:
- 你想建立一个数据生成模型,推理其隐藏的过程。
- 你需要量化预测中的不确定性,而不是预测单个值。
- 你的训练集具有大量与数据点数量相关的特征。
- 你的数据是结构化的 - 例如,使用组,空间,计算图或语言语义,并且你希望使用先验信息来获取这个结构。
- 你有一个,如我们在开发者大会上所讨论的,依靠测量值重构等离子体的逆问题。
TensorFlow Probability为你提供解决这些问题的工具。此外,它还继承了TensorFlow的优势,例如自动微分,以及通过多种平台(CPU,GPU和TPU)扩展性能的能力。
什么是TensorFlow Probability?
我们的机器学习概率工具为TensorFlow生态系统中的概率推理和统计分析提供了模块化抽象。
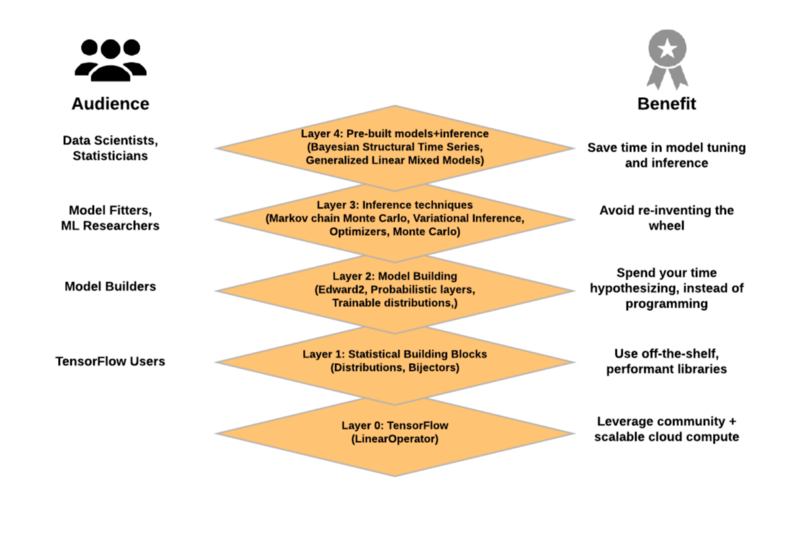
TensorFlow Probability结构图。
第0层
TensorFlow的数值运算。特别是,LinearOperator类实现了matrix-free,可以利用特殊结构(对角、低秩等)进行高效计算。它由TensorFlow Probability团队构建和维护,现在是TensorFlow的核心,tf.linalg的一部分。
第1层:统计的构建模块
- Distributions :包含批量和广播语义的概率分布和相关统计的大量集合。
- Bijectors:随机变量的可逆和可组合变换。Bijectors提供了丰富的变换分布的类,从经典的例子(如对数正态分布)到复杂的深度学习模型。
(有关更多信息,请参阅:https://arxiv.org/abs/1711.10604)
第2层:模型构建
- Edward2:一种将灵活的概率模型指定为程序的概率编程语言。
- 概率层:具有它们所代表函数不确定性的神经网络层,扩展了TensorFlow层。
- 可训练分布:由单个张量参数化的概率分布,使建立输出概率分布神经网络变得容易。
第3层:概率推理
- 马尔可夫链Monte Carlo:通过抽样逼近积分的算法。包括HMC(Hamiltonian Monte Carlo)算法,随机游走Metropolis-Hastings,以及构建自定义转换内核的能力。
- 变分推理:通过优化来近似积分的算法。
- 优化器:随机优化方法,扩展TensorFlow优化器。。
- 蒙特卡洛:用于计算蒙特卡罗期望值的工具。
第4层:预制模型和推理
- 贝叶斯结构的时间序列(即将推出):用于拟合时间序列模型的高级接口(即类似于R语言的BSTS包)。
- 广义线性混合模型(即将推出):用于拟合混合效应回归模型(mixed-effects regression models)的高级接口(类似于R的lme4包)。
TensorFlow Probability团队致力于通过尖端功能,持续代码更新和错误修复来支持用户和贡献者。我们将继续添加端到端的示例和教程。
示例:
使用Edward2构建线性混合效应模型
线性混合效应模型是一种对数据中结构化关系进行建模的简单方法。也称为等级线性模型(hierarchical linear model),它共享统计的各组数据点的强度,以改进对单个数据点的推理。
作为演示,我们使用R中流行的lme4包中的InstEval数据集,它由大学课程及其评级组成。使用TensorFlow Probability,我们将模型指定为Edward2概率程序(tfp.edward2,继承自Edward)。下面的程序根据其生成过程对模型进行具体化。
import tensorflow as tf
from tensorflow_probability import edward2 as ed
def model(features):
# Set up fixed effects and other parameters.
intercept = tf.get_variable("intercept", [])
service_effects = tf.get_variable("service_effects", [])
student_stddev_unconstrained = tf.get_variable(
"student_stddev_pre", [])
instructor_stddev_unconstrained = tf.get_variable(
"instructor_stddev_pre", [])
# Set up random effects.
student_effects = ed.MultivariateNormalDiag(
loc=tf.zeros(num_students),
scale_identity_multiplier=tf.exp(
student_stddev_unconstrained),
name="student_effects")
instructor_effects = ed.MultivariateNormalDiag(
loc=tf.zeros(num_instructors),
scale_identity_multiplier=tf.exp(
instructor_stddev_unconstrained),
name="instructor_effects")
# Set up likelihood given fixed and random effects.
ratings = ed.Normal(
loc=(service_effects * features["service"] +
tf.gather(student_effects, features["students"]) +
tf.gather(instructor_effects, features["instructors"]) +
intercept),
scale=1.,
name="ratings")
return ratings
该模型将“服务”,“学生”和“教师”的特征字典作为输入;这是每个元素描述单个课程的向量。模型对这些输入进行回归,假定潜在的随机变量,并返回课程评级的分布。在此输出上运行的TensorFlow会话将返回生成的评级。
详细请参阅:https://github.com/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Linear_Mixed_Effects_Models.ipynb
使用TFP Bijectors构建高斯Copula函数
Copula是多元概率分布,每个变量的边际概率分布是均匀的。要使用TFP内联函数构建copula,可以使用Bijectors和TransformedDistribution。这些抽象可以轻松创建复杂的分布,如:
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.distributions.bijectors
# Example: Log-Normal Distribution
log_normal = tfd.TransformedDistribution(
distribution=tfd.Normal(loc=0., scale=1.),
bijector=tfb.Exp())
# Example: Kumaraswamy Distribution
Kumaraswamy = tfd.TransformedDistribution(
distribution=tfd.Uniform(low=0., high=1.),
bijector=tfb.Kumaraswamy(
concentration1=2.,
concentration0=2.))
# Example: Masked Autoregressive Flow
# https://arxiv.org/abs/1705.07057
shift_and_log_scale_fn = tfb.masked_autoregressive_default_template(
hidden_layers=[512, 512],
event_shape=[28*28])
maf = tfd.TransformedDistribution(
distribution=tfd.Normal(loc=0., scale=1.),
bijector=tfb.MaskedAutoregressiveFlow(
shift_and_log_scale_fn=shift_and_log_scale_fn))
高斯copula创建一些自定义Bijectors,然后又展示了如何轻松地建立多个不同的Copula函数。
背景信息参阅“理解TensorFlow分布形状”:https://github.com/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Understanding%20TensorFlow%20Distributions%20Shapes.ipynb
使用TFP构建变分自动编码器
变分自动编码器是一种机器学习模型,它使用一个学习系统来表示一些低维空间中的数据,并且使用第二学习系统来将低维表示还原为原本的输入。由于TF支持自动微分,因此黑盒变分推理简直就是小case!例如:
import tensorflow as tf
import tensorflow_probability as tfp
# Assumes user supplies `likelihood`, `prior`, `surrogate_posterior`
# functions and that each returns a
# tf.distribution.Distribution-like object.
elbo_loss = tfp.vi.monte_carlo_csiszar_f_divergence(
f=tfp.vi.kl_reverse, # Equivalent to "Evidence Lower BOund"
p_log_prob=lambda z: likelihood(z).log_prob(x) + prior().log_prob(z),
q=surrogate_posterior(x),
num_draws=1)
train = tf.train.AdamOptimizer(
learning_rate=0.01).minimize(elbo_loss)
详细信息,请查看我们的变分自动编码器示例!
链接:https://github.com/tensorflow/probability/tree/master/tensorflow_probability/examples/vae
具有TFP概率层的贝叶斯神经网络
贝叶斯神经网络是在其权重和偏置上具有先验分布的神经网络。它通过这些先验提供了更多不确定性。贝叶斯神经网络也可以解释为神经网络的无限集合:它依据先验分配每个神经网络结构概率。
作为示范,我们使用CIFAR-10数据集:特征(形状为32 x 32 x 3的图像)和标签(值为0到9)。为了拟合神经网络,我们将使用变分推理(这是一套逼近神经网络权重和偏置的后验分布的方法)。也就是说,我们使用TensorFlow Probabilistic Layers模块(tfp.layers)中最近发布的Flipout estimator。
import tensorflow as tf
import tensorflow_probability as tfp
def neural_net(inputs):
net = tf.reshape(inputs, [-1, 32, 32, 3])
net = tfp.layers.Convolution2DFlipout(filters=64,
kernel_size=5,
padding='SAME',
activation=tf.nn.relu)(net)
net = tf.keras.layers.MaxPooling2D(pool_size=2,
strides=2,
padding='SAME')(net)
net = tf.reshape(net, [-1, 8 * 8 * 64])
net = tfp.layers.DenseFlipout(units=10)(net)
return net
# Build loss function for training.
logits = neural_net(features)
neg_log_likelihood = tf.nn.softmax_cross_entropy_with_logits(
labels=labels, logits=logits)
kl = sum(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
loss = neg_log_likelihood + kl
train_op = tf.train.AdamOptimizer().minimize(loss)
neural_net函数在输入张量上组建神经网络层,并且针对概率卷积层和概率稠密层执行随机前向迭代。该函数返回输出张量,它的形状具有批量大小和10个值。张量的每一行代表了logits(无约束概率值),即每个数据点属于10个类中的一个。
对于训练,我们建立损失函数,它包括两项:预期的负的对数似然和KL散度。我们通过蒙特卡罗近似预期的负对数似然。而KL散度作为层的参数,通过正则化项添加。
tfp.layers也可以用于使用tf.keras.Model类的eager execution (可以立即评估操作并且无需额外图形构建步骤)。
class MNISTModel(tf.keras.Model):
def __init__(self):
super(MNISTModel, self).__init__()
self.dense1 = tfp.layers.DenseFlipout(units=10)
self.dense2 = tfp.layers.DenseFlipout(units=10)
def call(self, input):
"""Run the model."""
result = self.dense1(input)
result = self.dense2(result)
# reuse variables from dense2 layer
result = self.dense2(result)
return result
model = MNISTModel()
入门
要开始在TensorFlow中进行概率机器学习,请运行:
pip install --user --upgrade tfp-nightly
对于所有的代码和细节,请查看github.com/tensorflow/probability。









