











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌利用深度学习结合荧光标记,准确预估显微图像
2018年04月13日 由 浅浅 发表
387115
0

在生物学和医学领域,显微技术为研究人员提供人肉眼无法观察到的细胞和分子的细节。透射光显微镜能够将生物样本在一边被照亮且成像,技术相对简单,生物样本耐受度高,然而缺点是产生的图像很难被合理评估。而在荧光显微镜下,生物样本(如细胞核)是专门针对荧光分子的,虽然分析过程有所简化,但事先需要的样本准备很麻烦。
随着机器学习在显微技术领域的深入应用,比如将算法用于自动评估图像质量以及协助病理学家诊断癌组织,就此而言,是否可以通过结合两种显微技术优势,同时将两种技术的缺陷最小化,开发一个深入学习系统?
从《硅片标记:从未被标记的图片中预测荧光标记》(In Silico Labeling: Predicting Fluorescent Labels in Unlabeled Images)一文中可以看出,深层神经网络可以从透射光图像中预测荧光图像,生成带有标记的有利用价值的图像,同时可能会用未改变特性的细胞进行纵向研究,以及微创细胞筛查的细胞疗法,并使用大量同时的标记进行调查研究。
谷歌开源了网络,提供完整的培训、测试数据,训练模型检查点和示例代码。
研究背景
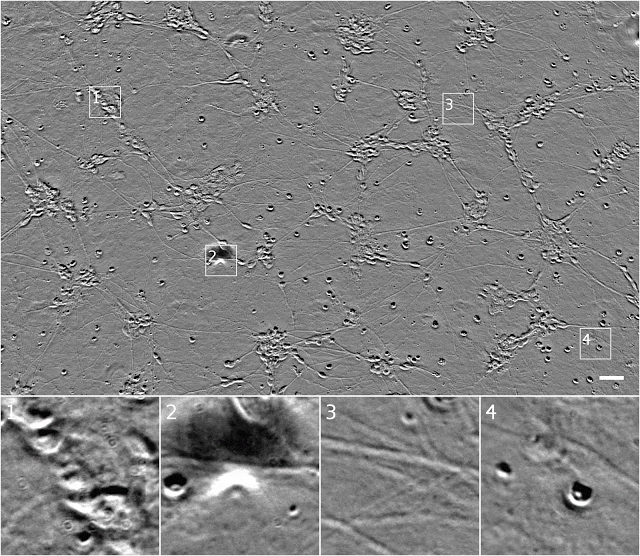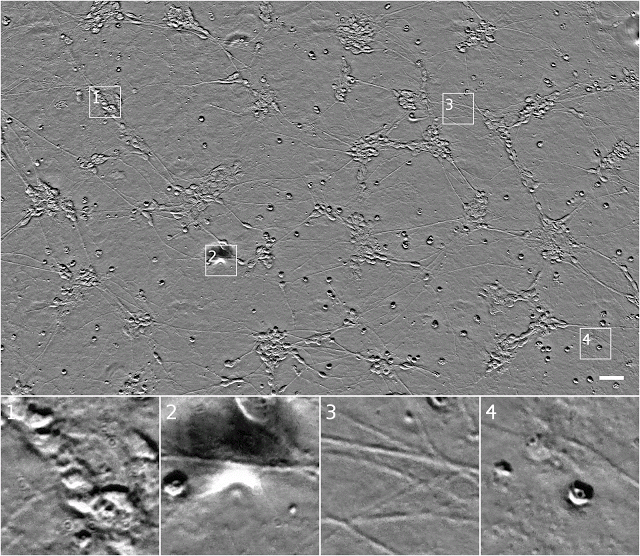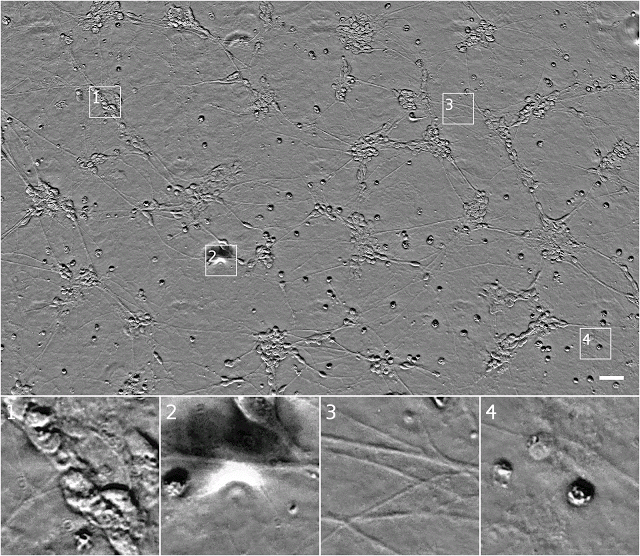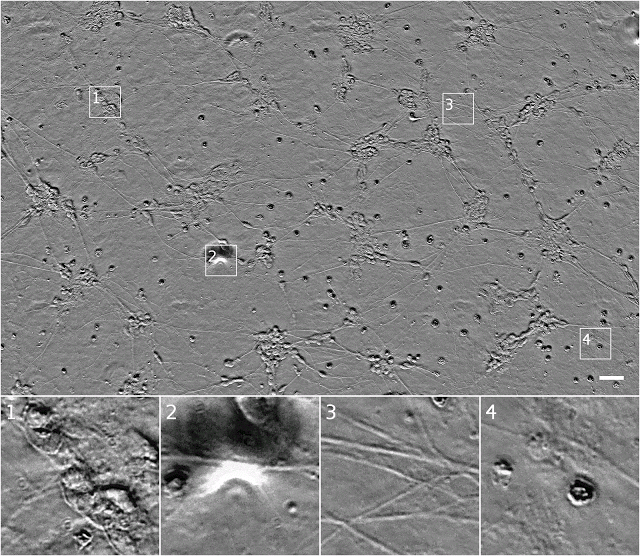
透射光显微镜技术便于使用,但对产生的图像很难进行评估。例如下图,来源于相衬显微镜,当光线穿过样品时,其发生移相的程度用一个像素的强度代表。
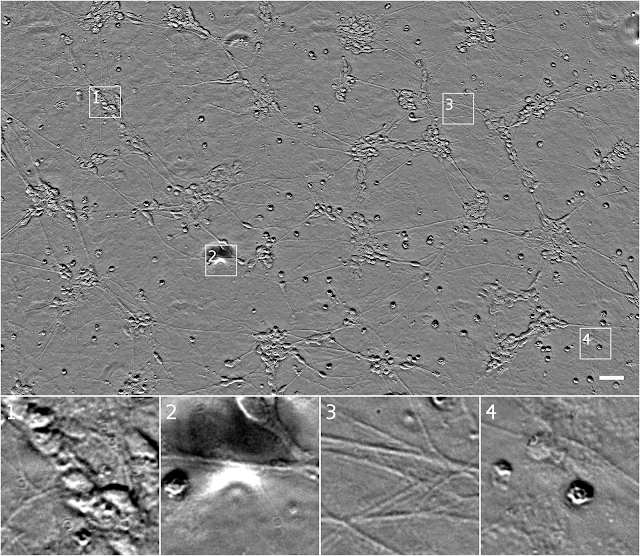
利用诱导多能干细胞培养的人类运动神经元透射光图像(相衬显微镜)。图样1显示了一组细胞,可能是神经元。图样2显示了模糊的底层细胞,图像有缺损。图样3显示了神经突。图样4开始显示的可能是死细胞。
比例尺:40μm
这一组图和以下图片均来源于Gladston研究所的Finkbeiner实验室
如上图,很难从图样1表明到底有多少细胞,也无法看出图样4中的细胞位置和状态。
*提示:在中上部有一个非常不明显的扁平细胞
另外,如图样3,在聚焦点上也很难得到连贯的结构。
我们可以通过在z堆栈(z-stacks)中获取图像,从而用透射光显微镜获得更多的信息,在(x,y)中记录图像,而z(与相机的距离)系统地变化。这就导致了不同部分的细胞聚集或离开焦点,最终提供了样本的3D结构信息。问题是,通常需要训练有素的眼睛来寻找z堆栈,也就是说对这种z堆栈的分析在很大程度上背离了自动化原则。
下面是一个z堆栈示例:
相同的细胞在相衬显微镜z堆栈中的显示。注意,当焦点移动时,其表象的变化。可以看到,图样1右下方的模糊形状是单一的椭圆形细胞,图样4中最右边的细胞在比最上面的细胞还要高,这可能表明它已经历了程序性细胞死亡。
相比之下,荧光显微镜图像更容易分析,因为样本都用到了精心设计的荧光标记,这些荧光能让研究人员看到想要观察的特性。例如,大多数人类细胞都有一个细胞核,所以一个细胞核标记(如下面的蓝色)加上简单的工具,就能够在图像中定位细胞并计算其数量。
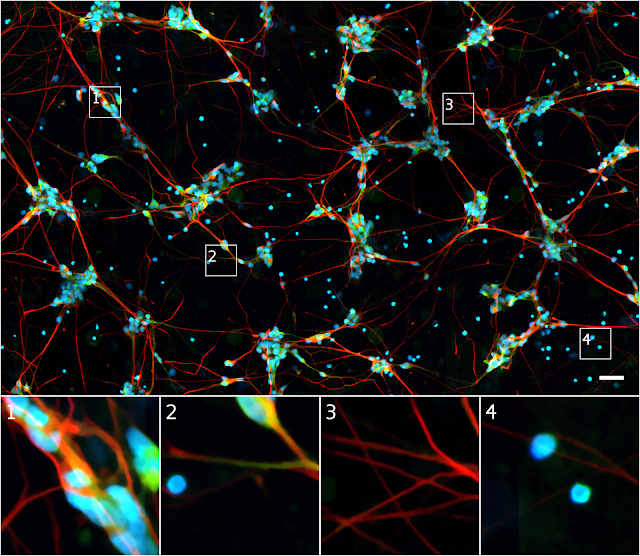
相同细胞的荧光显微图像。
蓝色荧光标记集中于DNA,突出了细胞核;绿色荧光标记集中于仅在树突上的蛋白质,即神经结构;红色荧光标记集中于仅在轴突中的蛋白质,是另一种神经结构。
有了这些标记,就更容易理解样本的情况,例如,图样1中绿色和红色标记确认了这是神经元簇;图样3,红色标记显示出那些神经突是轴突,而非树突;图样4,左上方的蓝点显示了一个之前难以察觉到的细胞核,左边细胞缺失的蓝点,表明它是无DNA的细胞碎片。
然而,荧光显微镜有严重的缺陷。首先,样本准备和荧光标记较为复杂且变数大。其次,当样品中存在许多不同的荧光标记时,光谱重叠会使人很难分辨出哪一种颜色属于哪个标记,一般研究人员只能在一个样本中同时控制3到4个标记。
另外,荧光标记可能对细胞有害,有时还可能直接杀死细胞,这使得在需要随着时间推移跟踪细胞的纵向研究中很难使用标记。
利用深度学习进行更多的研究
研究表明深层神经网络能够通过透射光z堆栈预测荧光图像。为了证实这一点,研究者建立了透射光z堆栈,与荧光图像匹配,并训练神经网络通过z堆栈预测荧光图像。下表描述了这一过程:
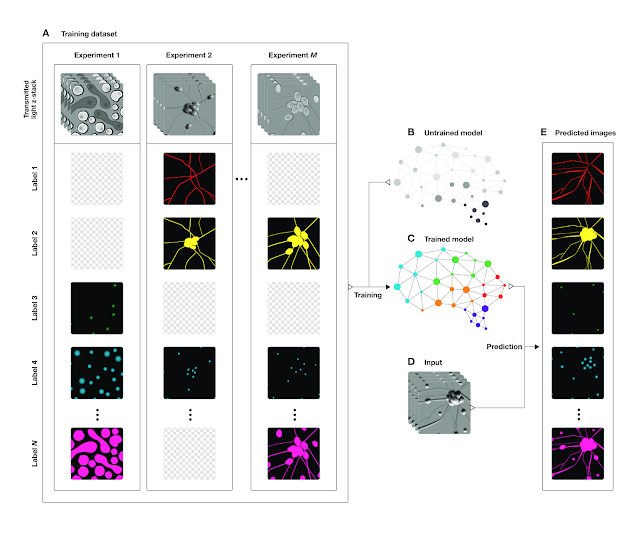
系统的概述
(A)训练范例的数据集:来源于z堆栈透射光图像与同一场景的荧光图像像素组。使用几种不同的荧光标记生成荧光图像,并在训练中表现有所不同;网格图像显示出没有为给定的例子获得的荧光标记。(B)未经训练的深层网络。(C)用数据A训练。(D)Z堆栈图像的新场景。(E)经过训练的网络C,通过从A学习到的荧光标记,用来预测新图像D中每一个像素。
在这项工作的过程中,研究者受到模块化设计的启发,开发了一种新的神经网络,组成了三种基本构建模块:in-scale结构不会改变特性的空间规模,down-scale结构将空间规模加倍,还有一个up-scale结构将其减半。这种建构将神经网络结构设计的疑难问题分解成两个简单问题:其一,构建模块的安排设计(宏观架构);其二,构建模块本身的设计(微架构)。研究者利用论文中讨论的设计原则解决了第一个问题,第二个问题是由Google Hypertune提供的自动搜索解决的。
为了确保方法合理,研究者使用来自Alphabet实验室和两个外部合作伙伴的数据来验证模型:即Gladstone研究所的Steve Finkbeiner实验室,以及哈佛的Rubin实验室。
这些数据包含了三种透射光图像模式(亮场、相衬和微分干涉对比),三种文化类型(人类运动神经元分别从诱导多能干细胞、老鼠大脑皮层培养和人类乳腺癌细胞中获得)。结果发现,此方法可以准确地预测几个标记,包括细胞核、细胞类型(如神经系统的细胞)以及细胞状态(如细胞死亡)。
下图显示了模型对于透射光输入的预测,以及运动神经元荧光实况的例子。
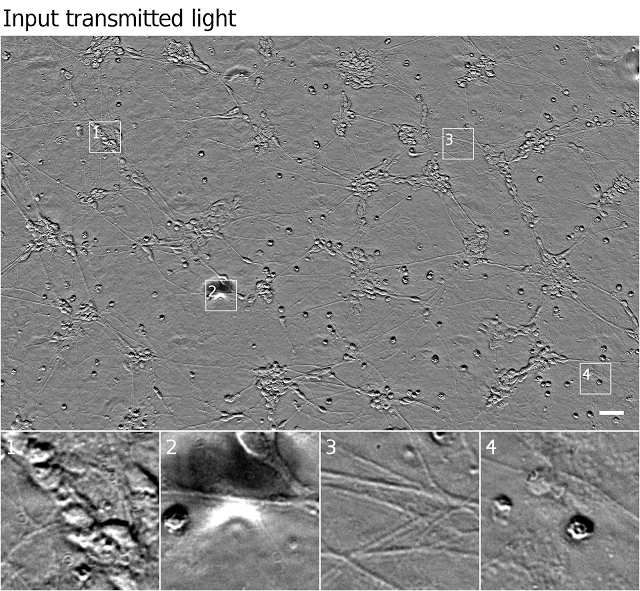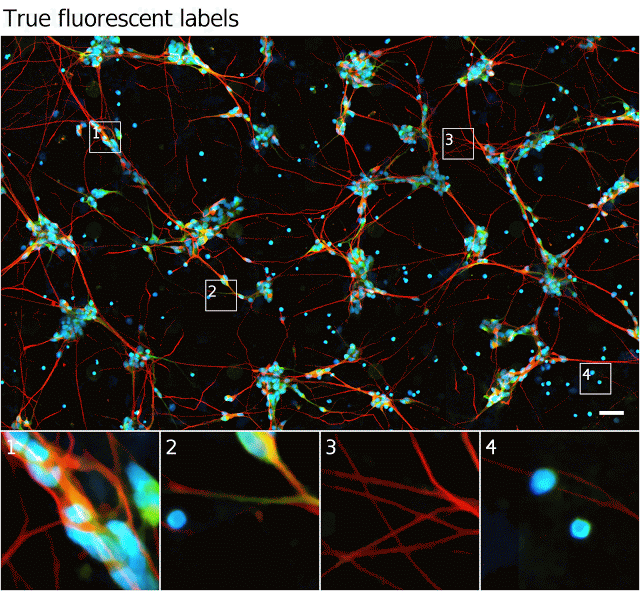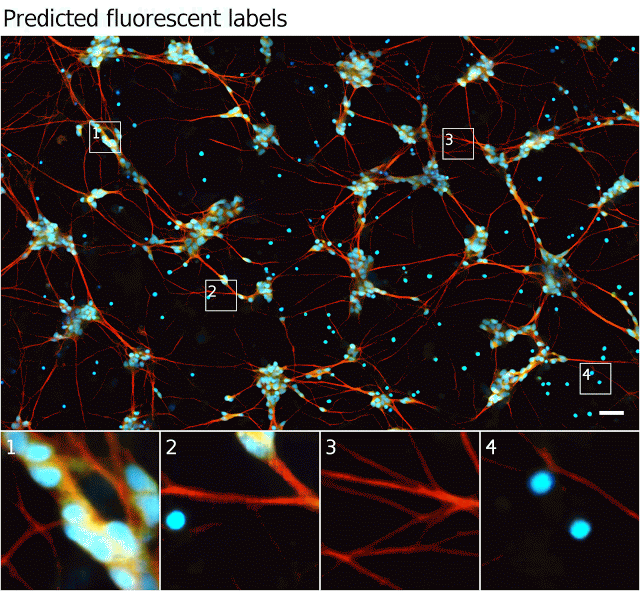
图中显示出在透射光和荧光图像中相同的细胞,以及模型预测的荧光标记;图样2显示模型预测了正确的标记,尽管输入图像中存在伪像;图样3中,模型推断出这些过程是轴突,可能由于它们与最近的细胞之间的距离;图样4,模型在顶部显示了难以察觉的细胞,并正确地识别了左边的物体——没有DNA的细胞碎片。
自己动手尝试一下吧
谷歌开源了模型、全部的数据集、训练和推断的代码,以及一个实例。新的标记可通过最少的额外训练数据来学习:在论文和示例代码中,展示了一个新的标记可以从单个图像中学习。这是一种叫做“转移学习”的现象,其中,一个模型可以更快地学习新任务,并且如果模型已经掌握了类似的任务,就可以使用更少的训练数据。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消