











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌发布深度学习模型DeepVariant新版本:旨在提高基因组数据精确度
2018年04月21日 由 浅浅 发表
468468
0

去年12月,谷歌发布了DeepVariant。这是一种深度学习模型,研究者训练它分析基因序列,使其准确地识别其中的差异,这种差异就是所谓的变体,它让我们每个人都作为独一无二的个体存在着。我们在最初的文章里主要关注的问题是,DeepVariant如何将识别变体(variant calling)作为图像分类问题来解决,并且得到结果能够比以前的方法更精确。
今天,谷歌宣布推出DeepVariant v0.6,重点在于提高精确度。在这篇文章中,主要阐述了研究者如何训练DeepVariant,如何通过将代表性数据添加到DeepVariant的训练进程中,以提高DeepVariant的精确度,并将其应用于两个常见的测序中——完整的外显子组测序和聚合酶链式反应测序。
测序数据的多种类型
基因组测序方法取决于以下几种因素:DNA样本的类型(如血液或唾液),DNA的处理技术(如放大技术),用来进行数据测序的技术(例如,使用的仪器甚至可以是同一个制造商的不同设备),使用哪一部分基因组,使用多少基因组序列……这些差异导致测序数据类型繁多。
通常,识别变体工具已经调整了特定的数据类型,但在其他类型上表现较差。考虑到为新的数据类型调整识别变体,可能会花费大量时间,也会涉及到专门知识,为每个人定制不同的工具似乎并不可行。相对地,利用DeepVariant,我们可以提高新的数据类型的精确度,方法是在训练过程中加入代表性数据,这样也不会对整体表现造成负面影响。
识别变体的真值
深度学习模型依赖用于培训和评估的高质量数据。在基因组学领域,由NIST发起的Genome in a Bottle (GIAB)财团生产的人类基因组,用于技术开发、评估和优化。使用GIAB标准基因组的好处是,它们的真实序列是已知的(至少在目前可能的范围内)。为了实现这一目标,GIAB采用了单人的DNA,多次使用各种实验室方法和测序技术(涉及很多数据类型)对其进行测序,并使用各种不同的识别变体工具分析数据结果。此外,为评估和判定差异进行大量研究,从而使每个基因组产生一个具有高信度的“真值集”。
DeepVariant的大多数训练数据都出自GIAB HG001投放的第一批标准基因组。样本来源于一个有北欧血统的女性,可从International HapMap Project获得,对于识别常见的人类基因变异模式,这一项目是目前人类做出的规模最大的尝试。因为从HG001获取的DNA可商用而且特征明显,所以常被用作首批样本,以测试新的测序技术和识别变体工具。通过使用HG001中的复制品和不同的数据类型,我们可以得到无数训练实例,可用于帮助DeepVariant学习如何精确将不同的数据类型进行分类,甚至是推广到前所未有的数据类型中。
v0.5版本中经过改良的外显子组模型
在发布的v0.5版本中,制定了与标准兼容的训练策略,暂时回避了完备样本HG002,以及任何来自染色体20的数据。HG002是GIAB投放的第二批标准基因组,提取自一个德系犹太种族的男性。这一样本的性别和种族都与HG001不同,确保了DeepVariant在多样化种群方面表现良好。此外,为测试准备的染色体20,使得对于任何包含真值的数据类型,用DeepVariant评估的精确度都可以得到保证。
v0.5版本中,我们还关注了外显子组数据,它是直接为蛋白质合成指定遗传密码的基因组子集。外显子组在整个人类基因组占比不到1%,所以整个外显子组测序(WES)的成本远低于完整基因组测序(WGS)。外显子组包含许多临床意义上的变体,因此它对研究人员和临床医生都很有用。为了提高外显子组的结果精确度,我们在DeepVariant的训练数据中,加入了DNAnexus提供的各种WES数据类型。v0.5版本中的WES模型显示,减少了43%的indel(插入-缺失)错误,同时减少了22%的单核苷酸多态性(SNP)错误。
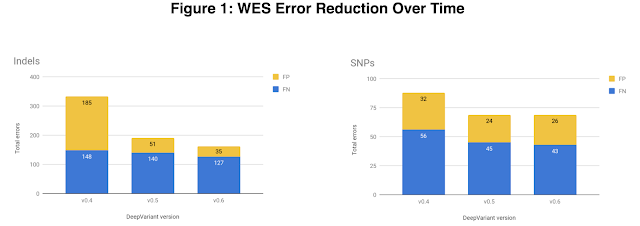
DeepVariant所有版本的HG002外显子组的错误总数,分别为indel错误(左)和SNP错误(右)。
错误可能是假阳性(FP),用黄色代表,抑或是假阴性(FN),用蓝色代表。
精度最显著的提高在v0.4和v0.5版本之间,可能是由于indel FPs的减少。
v0.6版本中,用PCR+数据改进完整基因组测序模型
DeepVariant最新的v0.6版本,致力于改进数据的精确度,并在测序前,通过聚合酶链式反应(PCR)放大DNA。PCR用来放大非常微小的DNA,既简单、成本又低,毕竟在以前测序结果也被称为阳性PCR(PCR+)测序数据。然而PCR可能会带来偏差和错误,而不基于PCR(或PCR-free)的DNA制备方法也越来越普遍。在v0.6版本发布之前,DeepVariant的训练数据都是清一色的PCR-free数据,而DeepVariant进行外部评估表现不佳时,PCR+是为数不多表现良好的数据类型。因此,在DeepVariant训练数据中加入DNAnexus提供的PCR+实例,我们也能看出这一数据类型的精确度显著提高,indel错误减少了60%。
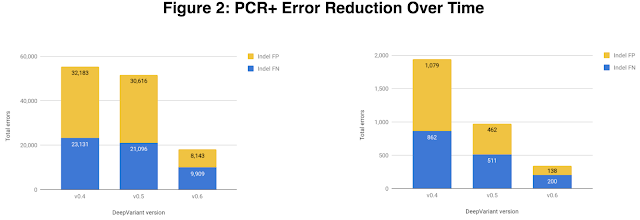
DeepVariant v0.6版本显示了PCR+数据的精确度提高,主要归由于indel错误的减少。我们重新分析了两个之前用在外部评估的PCR+样本,包括左边的DNAnexus和右边的bcbio,两图显示了indel精确度是如何随着DeepVariant版本升级而提高的。
DeepVariant v0.6中,来自DNAnexus和bcbio的独立评价仍然可用。他们的分析支持我们提高indel的精确度,还包括与其他识别变体工具进行比较。
总结
谷歌开源了DeepVariant,鼓励合作,期望利用这项技术来解决现实世界的问题。随着测序技术的发展创新,越来越多的临床应用不断涌现,DeepVariant也有更广阔的发展空间,期待这一技术在未来能够提供更为精确的结果。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消