











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Uber开源Atari,让个人计算机也可以快速进行深度神经进化研究
2018年04月24日 由 浅浅 发表
696380
0

Uber近期发布了一篇文章,公开了五篇关于深度神经进化的论文,其中包括发现了遗传算法可以解决深层强化学习问题,而一些流行的方法也可替代遗传算法,如深度Q-learning和策略梯度。这项研究是Salimans等人在2017年进行的,另一种神经进化算法,即进化策略(ES)同样可以解决问题。Uber进一步阐述了以下问题:如何通过更多地探索更新智能体所带来的压力形式来改进ES;ES是如何与梯度下降联系起来的。这些研究花费巨大,通常需要720到3000个CPU,并分布在巨大,高性能的计算集群中,因此对于大多数研究人员、学生、公司和业余爱好者来说,深度神经进化研究似乎遥不可及。
好消息是,Uber开源了代码,使得进行这样的研究既快捷,成本又低。用这些代码训练深度神经网络操作Atari,由之前用720个CPU、花费1小时,到现在用新式个人计算机、花费少于4小时就可以实现。这一进展至关重要,因为它极大地影响了对开展此类研究所需资源的认识,使更多的研究人员得以开展这一研究。
[video width="160" height="210" mp4="https://www.atyun.com/uploadfile/2018/04/frostbite_ga_noframeskip.mp4"][/video]
[video width="1000" height="1000" mp4="https://www.atyun.com/uploadfile/2018/04/solution1.mp4"][/video]
神经进化技术是解决深度强化学习问题(如Atari或人形运动)的极具竞争力的替代方案。视频里的示范是用简单遗传算法进行的深度神经网络训练。
是什么让研究进展加快,而且只用一台电脑就能解决问题?
新式高端计算机中有许多虚拟核心,表现与新式计算集群类似。如果进行适当的并行评估,在720核上需运行1小时,那么在48核的个人电脑的CPU上运行,就要花费16小时,这是相当缓慢的过程,但也不算慢得离谱。新式计算机也带有GPU,然而运行深度神经网络就很迅捷。研究者使用的代码在并行方面最大化了CPU和GPU的使用。在GPU上运行深度神经网络,而在CPU上运行域(如视频游戏或物理模拟器),在同一批中执行并行多重评估,使所有可用的硬件都可充分利用。正如下方所描述的那样,这也包括自定义TensorFlow操作,同样可以显著提高训练速度。
在GPU上进行训练,需要对神经网络操作的计算方式进行一些修改。在Uber的设置中,运行单个神经网络,用单独的CPU比GPU速度更快,不过在并行相似的计算指令时(比如神经网络forward pass),GPU效果更明显。为了更好利用GPU,Uber聚合了多重神经网络forward pass并将其分批处理。在神经网络研究中,这样的做法是非常普遍的,不过通常会涉及到相同的神经网络处理一批不同的输入。
然而进化算法是在不同的神经网络总体中运行的,但即使神经网络不同(对内存需求也增加了),依然可以加速。Uber使用基本的TensorFlow操作来执行这个总体的批处理,速度提升了近两倍,节省了大约8小时的训练时间。不过Uber可以做到更好。TensorFlow提供了所有必需的操作,这些操作不会因为计算类型改变。因此,Uber添加了两类常规TensorFlow操作,结合这种操作可以再将速度加快两倍,从而将每台机器的训练时间减少到4小时,即本文开篇所提到的时间长度。
第一个自定义的TensorFlow操作显著加快了GPU的处理速度。它是专门为RL领域的异构神经网络计算而构建的,在这一领域中每一个处理的长度不尽相同,在Atari和许多模拟机器人学习任务中也是如此。因此GPU只运行需要的神经网络数量就够了,而不需要在运行每次迭代中,都配备一组固定的(大型)神经网络。
到目前为止所描述的方法改进,使得GPU比CPU更具成本效益。事实上,GPU速度相当快,以至于Atari模拟(CPU)无法跟上,即使是用多重处理库进行并行化计算也一样。为了提高模拟性能,Uber添加了第二组自定义的TensorFlow操作。
这些操作改变了Atari模拟的封装器——从Python变为自定义的TensorFlow命令(重置、步骤、观察),这些命令利用了TensorFlow提供的快速多线程功能,从而避免了Python和TensorFlow交互时出现的减速现象。总的来说这些变化使Atari模拟器加快3倍。对于多重领域的实例并行运行之类的强化学习研究来说,这些创新可以使其加速,而并行运行技术在强化学习中也越来越常见,比如分布式深度Q-learning(DQN),分布式策略梯度。
一旦Uber有能力在GPU上快速运行网络总体,并在CPU上运行更快的域模拟器,那么使计算机上的资源尽可能多地运行就成了新的挑战。如果在每个神经网络上执行forward pass,并询问在当前的状态下应该采取怎样的行动,当每个处理都在计算答案时,运行游戏模拟器的CPU会停止运行。同理,如果Uber之后采取行动并询问域模拟器:这些行动会导致怎样的状态?那么在模拟问题情境时,运行神经网络的GPU将会停止运行。下面展示了多线程CPU+GPU选择过程。而即使改进单线程计算,效率仍然低下。
最好的解决方案就是将两个或多个神经网络子集合与模拟器配对,让GPU和CPU同时运行,以更新神经网络,或根据准备好要进行的步骤(神经网络或模拟),更新来自不同集合的模拟。这种方法如下图最右所示的“pipelined CPU+GPU”。用这种方法,以及其他上文提到的改进方法,Uber能够将单一计算机的神经网络训练时间减少到4小时以内。
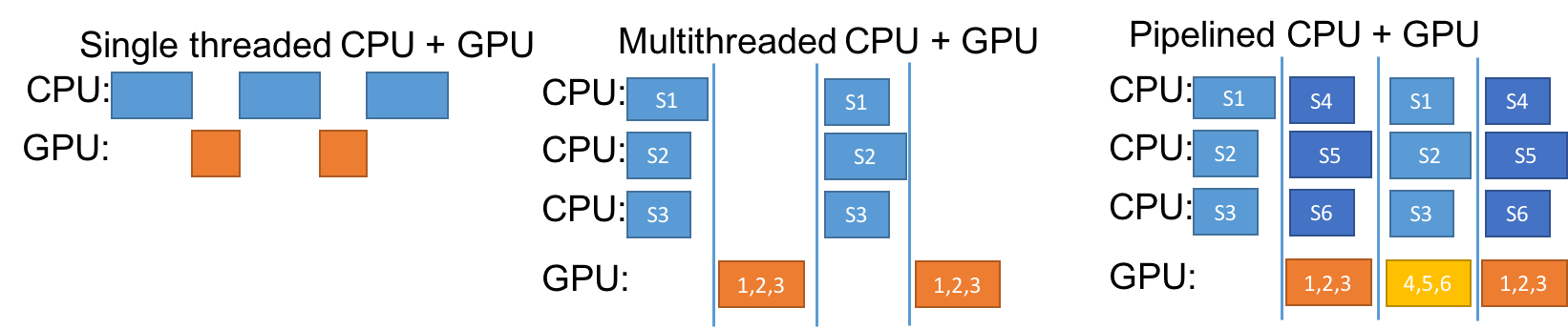
优化RL中异构神经网络总体的安排。蓝色的盒子是域模拟器,如Atari游戏模拟器或者MuJoCo的物理引擎,每一处理长度不同。使用GPU(左)会导致性能低下,原因有两个:1)无法利用GPU批处理大小的并行计算能力,2)GPU等待CPU处理完成的空闲时间,反之亦然。多线程的方法(中)通过允许多个CPU并行处理模拟器,从而更有效地使用GPU,但是当cpu在工作时,GPU就会处于空闲状态,反之亦然。Pipelined执行方法(右)使GPU和CPU高效运行,这种方法也适用于多个GPU和CPU同时运行,正如研究者在实践中所做的那样。
更快,成本更低的实验带来的影响
Uber的代码可以让这一领域的所有研究者(包括学生和自学者),在训练神经网络挑战Atari这样问题时,能够快速进行实验迭代。而这在之前,这种实验通常只有资金充足的产业或学术实验室才能负担得起。
运行速度快的代码推进研究的进步。比如,Uber的新代码让Uber能够建立广泛的用于搜索遗传算法的超参数,成本很低,比起Uber最先的报道中的结果,在大部分Atari游戏中的表现显著提升。运行速度快的代码也促进了Uber目前的研究,例如通过节省迭代时间来改进深度神经进化,而且Uber能够在更多领域上尝试新想法,更持久地运行算法。
Uber的新软件资源库包括深层遗传算法的执行程序,Salimans等人提供的进化策略算法,以及Uber的(相当有竞争力)随机搜索控制套件。Uber希望其他人使用Uber的代码来加快他们的研究活动。Uber也邀请了专家群体建立代码以便进行改进。比如,对于分布式GPU训练和为这种类型的计算自定义其他的TensorFlow操作,还可以进一步加速。
在深度神经进化发展前景广阔,除了Uber,OpenAI,使用DeepMind、Google Brain和Sentient的进化算法,也加快了深度学习的研究进展。Uber希望开源代码这一举措,能够使更多人走进这个领域。
总之,Uber的目标是降低这项研究的成本,让各个背景的研究人员都可以尝试自己的想法,以改进深层神经进化,并利用这一方法完成他们的目标。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消