











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






利用统计方法,辨别和处理数据中的异常值
2018年04月27日 由 浅浅 发表
231524
0

在建模时,清理数据样本非常重要,这样做可以确保观察结果充分代表问题。有时,数据集可能包含超出预期范围之外的极端值。这通常被称为异常值,通过理解甚至去除这些异常值,能够改进机器学习建模和模型技能。
在本教程中,你将会发现更多关于异常值的信息,以及识别和过滤来自数据集的异常值的两种统计方法。
学完本教程,你将会明白:
- 数据集中出现的不太可能的观察值往往就是异常值,异常值的出现有很多种原因。
- 标准差可用于识别符合高斯或类高斯分布的数据中的异常值。
- 用四分位距可以识别数据中的异常值而无需考虑分布。
教程概述
本教程分为4部分,分别是:
- 什么是异常值
- 测试数据集
- 标准差方法
- 四分位距方法
什么是异常值
异常值是一个与其他观察结果明显不同的观察结果。它稀有而明显,看上去就与其他结果格格不入。很多因素都可能会导致异常值的出现,比如:
- 测量或输入误差
- 数据污染
- 真正的异常值(比如篮球运动员Michael Jordan)
由于数据集各不相同,没有定义和识别异常值的统一方法。你或领域专家需要对观察结果进行解释,从而决定这一数值到底算不算异常值。不过,我们可以用统计方法来辨别那些与既定数据不同的观察结果。
这并不意味着辨别出的值一定是异常值,必须要去除。不过这篇教程里出现的工具会帮你分离出需要再次查看的稀少事件。
一个实用的方法是,鉴定标识出的异常值,判断在正常值环境下,与异常值是否存在系统的关联。如果有,那么它们就不是异常值,而是可被解释的数值,抑或异常值本身可以被系统地辨别出来。
测试数据集
在我们研究异常值识别方法之前,让我们定义一个数据集,可以用它来测试这些方法。我们将从高斯分布中抽出1万个随机数字作总体,平均数为50,标准差为5。从高斯分布中抽出的数字会存在异常值,也就是说,由于分布本身,将会有一些值与平均数相差甚远,这些稀有的值就可以视为异常值。
我们调用randn()函数来生成随机高斯值,平均数为0,标准差为1,然后将结果乘以我们自己设定的标准差,然后加上平均数,让这些值成为首选。
建立伪随机数生成器以确保在每次运行代码,以保证得到的都是相同的数字样本。
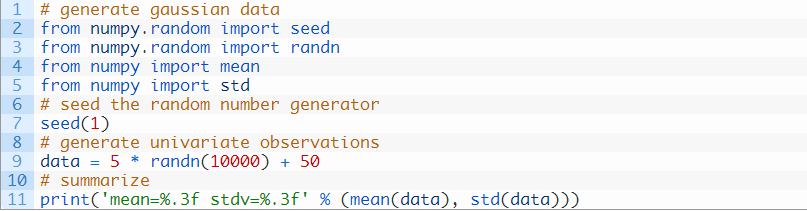
运行这个示例会生成样本,然后打印出平均数和标准差。
正如预想的那样,这些值非常接近预期值。
标准差方法
如果已知样本中的值是高斯分布或者近似高斯分布,那么我们可以用样本的标准差来确定异常值。高斯分布的性质是,平均数到标准差的距离可以用来总结样本中的值所占的百分比。例如,在平均数的一个标准差范围内中包含68%的数据。
如上所示的测试数据集,平均数为50而标准差为5,因此所有在45-55之间的数据占样本的68%。如果我们扩展范围,我们可以覆盖更多的数据样本:
- 距离平均数1个标准差范围占比68%
- 距离平均数2个标准差范围占比95%
- 距离平均数3个标准差范围占比99.7%
落在3个标准差范围之外的值也在分布中,但这个值不太可能是370个样本中的一个。实际上,在高斯分布或者近似高斯分布中,距离平均数3个标准差范围一般是判断异常值的临界点。对于更小的样本,也许会采用2个标准差范围,而更大的样本就用4个标准差范围。
下面举一个实例来进行说明。
有时,首先要标准化数据(例如,转化为平均数为0,单位是方差的z分数),这样就可以使用标准z分数的临界点来检测异常值。这是一种方便但并不必要的方法,我们将在原始数据的范围内进行计算,以使问题更为清晰。
我们可以计算给定样本的平均数和标准差,然后确定辨别异常值的临界点,即距离平均数的3个标准差范围。

然后,我们可以将超出定义的下限和上限的值,确定为异常值。
我们可以过滤出样本中那些超出定义界限的值。
我们可以将这些与在前一节中准备的样本数据集放在一起。
下面列出了完整的示例。
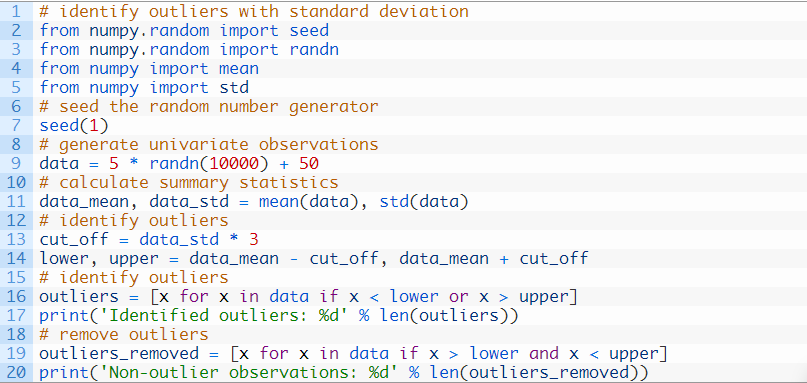
运行这个示例将首先打印识别出的异常值,然后是那些正常的观察结果的数量,来显示如何辨别并过滤出异常值。
到目前为止,我们只讨论了符合高斯分布的单变量数据,例如单个变量。如果你有多变量数据,例如每个多变量数据都符合不同的高斯分布,那么你也可以使用相同的方法。如果你有两个变量,你可以想象把两个维度的界限定义为一个椭圆。三个维度可能会形成椭圆体,以此类推。
另外,如果你对域有更多的了解,也可以观察数值是否超出一个数据集或数据维度的子集的界限,以此来判断异常值。
四分位距方法
并不是说从高斯分布中抽出的所有数据都符合正态分布。适用于对非高斯分布的数据样本进行总结的统计方法是四分位距,简称IQR。IQR计算数据的75和25百分位数间的差异,可用于构建箱形图中的矩形盒。注意百分位数可以通过对观察结果进行排序,或选择特定指标的值来进行计算。第50个百分位数是中间值,或者是偶数样本的平均中值。如果我们有1万个样本,那么第50个百分位数就是第5000和第5001个值的平均数。
我们把百分位数称为四分位数是因为数据被位于第25,50和75的数值分成了四组。IQR定义了位于中间即50%的数据。IQR可以通过定义样本值的界限来识别异常值,这个值是IQR的一个因子k,低于第25个百分位数,或者高于第75个百分位数。常见的因子k的值是1.5。如果因子k的值是3或更高,就可以用于辨别异常值,或分辨出箱形图中的异常值。在箱形图中,这些界限组成了矩形盒的边线,而将那些落在边线外的值画作点。
我们可以使用percentile() NumPy函数来计算数据集的百分位数,需要数据集和所需百分比的规格。之后可以通过第75个百分位数和第25个百分位数计算IQR。

然后我们可以计算出异常值的界限为1.5倍的IQR值,然后从第25个百分位减去这个临界点,再把它加到第75个百分位中,以得出数据的实际界限。

我们可以用这些界限辨别异常值。
我们也可以利用界限对数据集中的异常值进行过滤。
我们可以将这些结合起来,并在测试数据集上演示该过程。
下面举出了完整的示例。
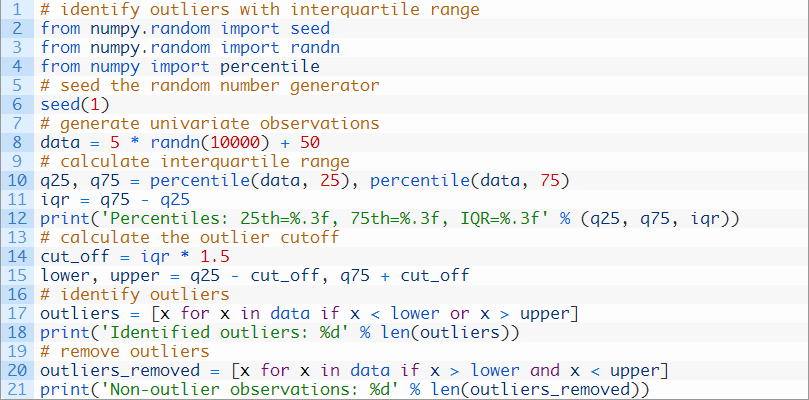
运行这个示例,首先打印出确定的第25个和第75个百分位数,以及计算出来的IQR。然后打印出非异常值观察结果的数量,之后才是识别出的异常值。

这一方法可以通过依次计算数据集中的每个变量的界限,来处理多变量数据,而且观察结果中的异常值即为落在矩形或超矩形范围外的数值。
扩展
这节列出了一些你可能会想要探索的扩展问题。
- 开发你自己的高斯测试数据集,并在直方图上绘制异常值和正常值。
- 在非高斯分布的单变量数据集上测试基于IQR的方法。
- 选择一种方法,创建一个函数,与任意维度共同过滤出给定数据集的异常值。
总结
在本教程中,你学习到了更多关于异常值的信息,以及识别和过滤来自数据集的异常值的两个统计方法。
具体来说,你学到了:
- 数据集中出现的不太可能的观察值往往就是异常值,异常值的出现有很多种原因。
- 标准差可用于识别符合高斯或类高斯分布的数据中的异常值。
- 用四分位距可以识别数据中的异常值而无需考虑分布。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消