











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI:通过人工智能之间的辩论实现安全的人工智能系统
2018年05月09日 由 yuxiangyu 发表
183823
0
我们(OpenAI)提出了一种人工智能安全技术,它可以训练智能体相互辩论话题,用人做法官来判断谁赢了。我们相信,这种或类似的方法最终可以帮助我们训练AI系统执行比人类能力更高的高级认知任务,同时保持与人类的偏好一致。我们将概述这种方法以及初步的概念验证实验,并发布了一个Web界面,以便大家可以尝试这种技术。
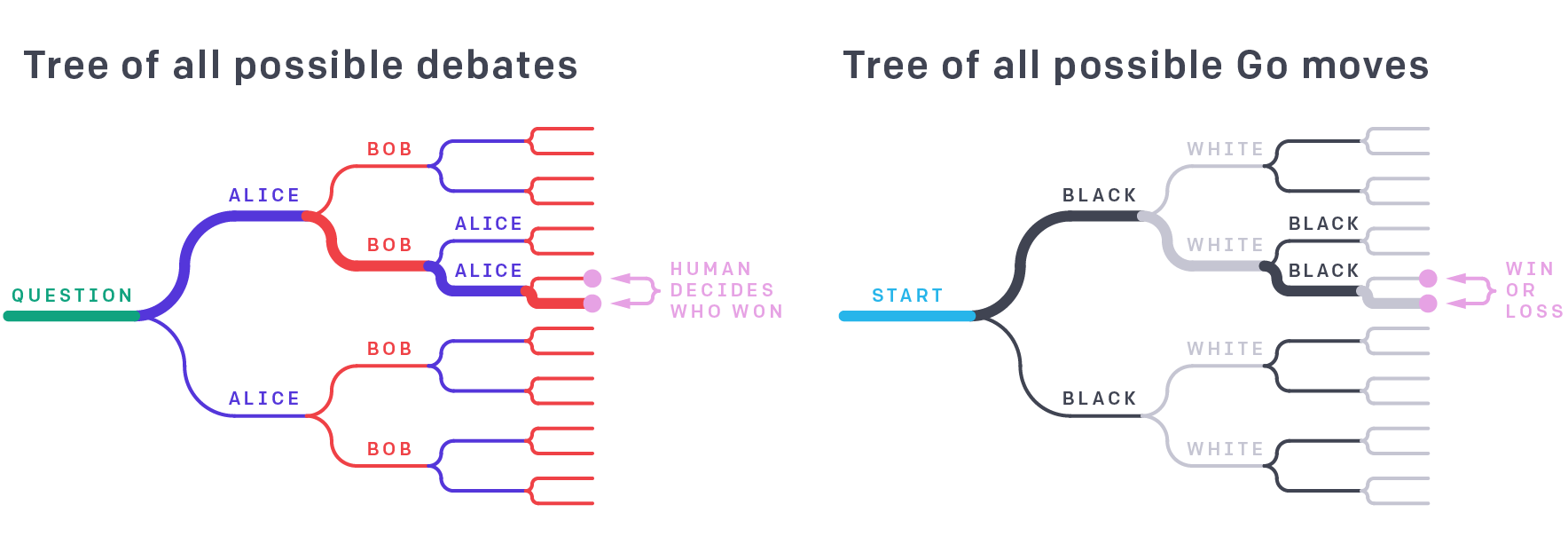
这种辩论方法可视化为一个游戏树,类似于围棋这样的游戏,只是针对的对象变成了在叶节点上辩手举措和人类判断之间的句子。在辩论和围棋中,真解取决于整个树,但是强大的智能体选择的树的单一路径是整体的证明。例如,虽然业余围棋玩家不能直接评估职业移动的强度,但他们可以通过评估游戏结果来判断专家级玩家的技能。
论文:https://arxiv.org/abs/1805.00899
网站:https://debate-game.openai.com/
将AI智能体与人类目标和偏好一致的一种方法是在训练时询问人类哪些行为是可靠和有用的。虽然这种方法看起来很有前景,但它要求人类识别出好的或不好的行为;在很多情况下,智能体的行为可能太复杂到人们无法理解,或者任务本身难以判断或证明。比如,具有非常大的、无法可视化观察空间的环境 - 在计算机安全相关环境中运行的智能体程序,或者协调大量工业机器人的智能体程序。
我们怎样才能增强人类的能力,使他们能够有效地监督先进的AI系统?一种方法是利用AI本身来帮助监督,要求AI(或使用某个独立的AI)指出任何提议的行动中的缺陷。为了达到这个目的,我们将学习问题重新定义为两个智能体之间的博弈,智能体之间有争论,人们对其交流进行评判。即使智能体比人类对问题的了解更深入,人类也可能判断哪个智能体有更好的论点(这类似于专家证人争辩以说服陪审团)。
我们的方法是为两个决斗AI智能体之间的这种博弈提出了一个特定的辩论形式。这两种智能体可以通过自我训练来训练,类似于AlphaGo Zero或Dota 2。我们希望,经过适当训练的智能体可以产生远超人类法官能力的价值对齐(value-aligned)的行为。如果两位智能体对真相持不同意见,但完整的理由太大无法向人们展示,那么辩论可以集中在更简单的事实争议上,最终得出一个简单到可以直接判断的结论。
举个例子,“什么是去度假的最佳去处?”这个问题。如果一个智能体爱丽丝声称代表我们进行研究并给出答案说:“阿拉斯加”,那么很难判断这是否是最好的选择。如果第二位智能体鲍勃说:“不,最好是巴厘岛”,这也许听起来更令人信服,因为巴厘岛更为暖和。爱丽丝回复说:“你不能去巴厘岛,因为你的护照不能及时到达”,这表明巴厘岛存在我们尚未发现的缺陷。但接着,鲍勃反驳:“加急护照服务只需两周”。辩论一直持续到我们达成一个结论,也就是人类可以正确判断为止,因为另一个智能体认为它已经无法改变人的意见了。
说服一个稀疏MNIST分类器
虽然我们预计,在智能体之间使用自然语言交谈时,这种方法从长远来看最为有效,但我们需要在更简单的领域进行测试,而且今天的自然语言建模也不足以完成这个任务。测试一项不超出人类的能力范围的任务更为容易。我们可以通过转向视觉领域来做到这一点,并且通过用“辩手知道而法官缺乏的知识”替换“辩手拥有法官缺乏的能力”。法官的目标是猜测图像的内容,但它只能看到由辩手挑选出的像素。辩手们看到完整的图像,并进行比赛,他们轮流向法官展示单个像素。在这里完整的图像是超越人类尺度信息的替代品。
我们在最简单的视觉任务MNIST上尝试了这个方法。法官不是人类,而是经过预训练的分类器,用于预测来自6个非黑色像素的MNIST数字,在预训练法官时随机采样每个图像表示。然后有两个智能体在辩论中交替显示像素,总共6个显示像素时停止(所以法官总共只看到一点点信息)。一名辩手是诚实的,并试图让法官猜对,另一名辩手试图让法官猜错。如果两个智能体必须事先声明他们争论的数字,则辩论会将59.4%准确率的稀疏分类器变成88.9%准确率。也就是说,诚实的玩家在MNIST测试集中胜率为88.9%,在这个过程中,使法官高于独立判断的准确率。
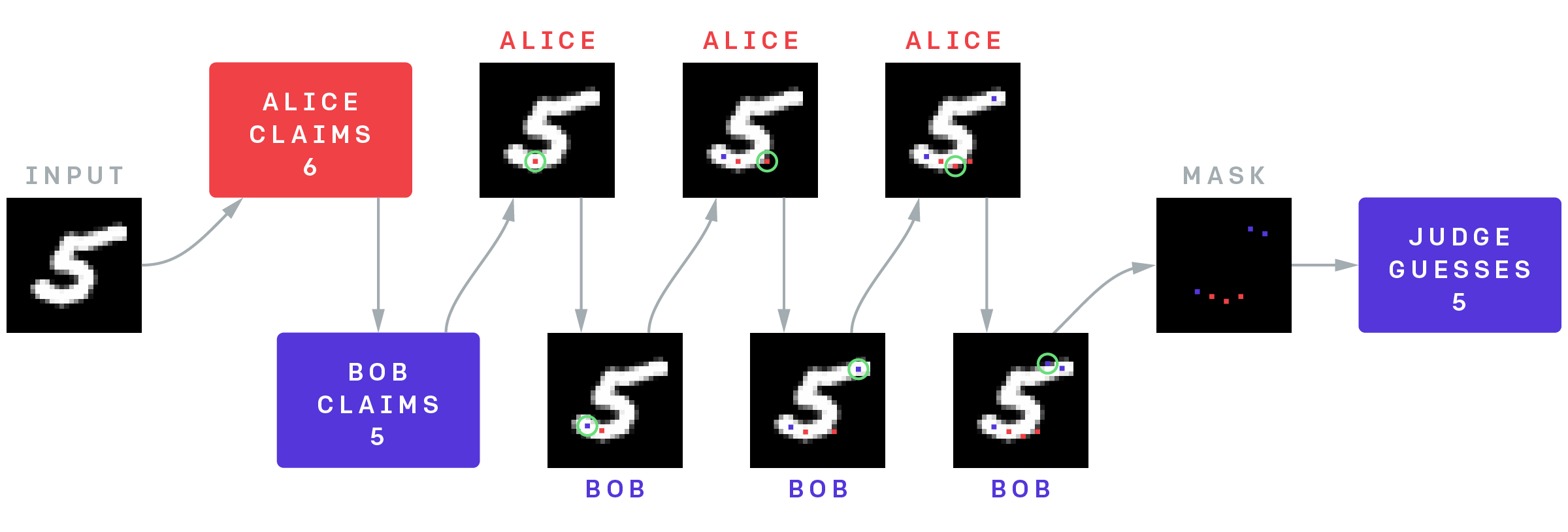
MNIST辩论游戏的结构。辩论者爱丽丝和鲍勃看到一张图片,爱丽丝试图欺骗法官认为它是一个6,鲍勃试图正确说服法官是一个5.他们交替向法官透露非黑色像素,在看到6个像素后,法官正确地将其识别为5。Alice在底部追踪曲线使其看起来像一个6 (红色像素),但是鲍勃通过揭示右上角的像素(蓝色像素)来有效地应对该策略,因为这个点是大多数MNIST中的6所不具备的。
换句话说,图像更可能包含更能证明真相的像素,而不是包含更能证明谎言的像素,而6个像素选择一半是真诚的、一半是恶意比6个随机像素要好。如果法官是一个能够一次推理几个论证的人,但无法筛选所有可能的论点,那么辩论中的最佳发挥可以(我们希望)奖励辩论智能体为我们做筛选,即使我们缺乏一个区分好的论点和坏的先验机制。
下面的面板显示了几个示例游戏。骗子的胜利比诚实的胜利更有趣,所以我们挑选样本,使骗子在下面显示的50%的游戏中胜出(实际上骗子只赢得了11.1%)。将鼠标悬停在其中一位数字上以查看游戏(需访问openAI博客),包括显示哪些像素以及每次移动时法官可能的假设:
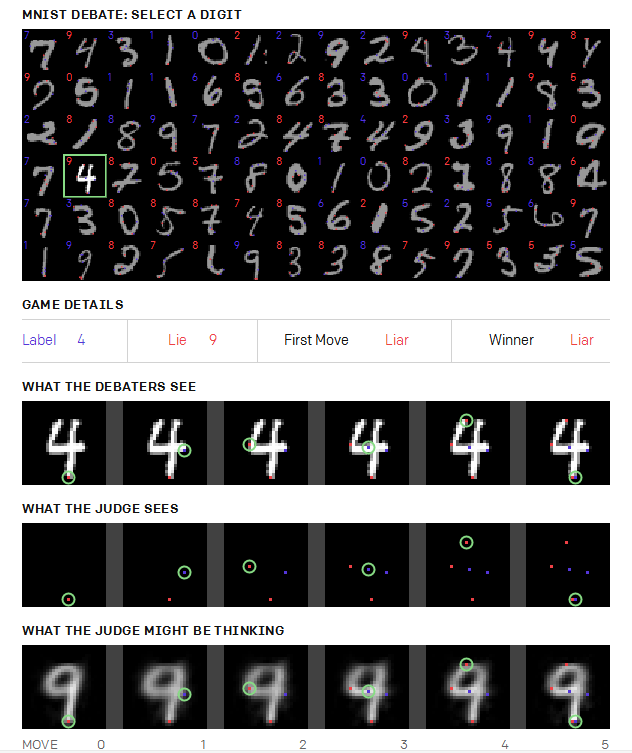
有些数字比其他数字更好骗。比如,说服法官数字是8或9特别的容易:
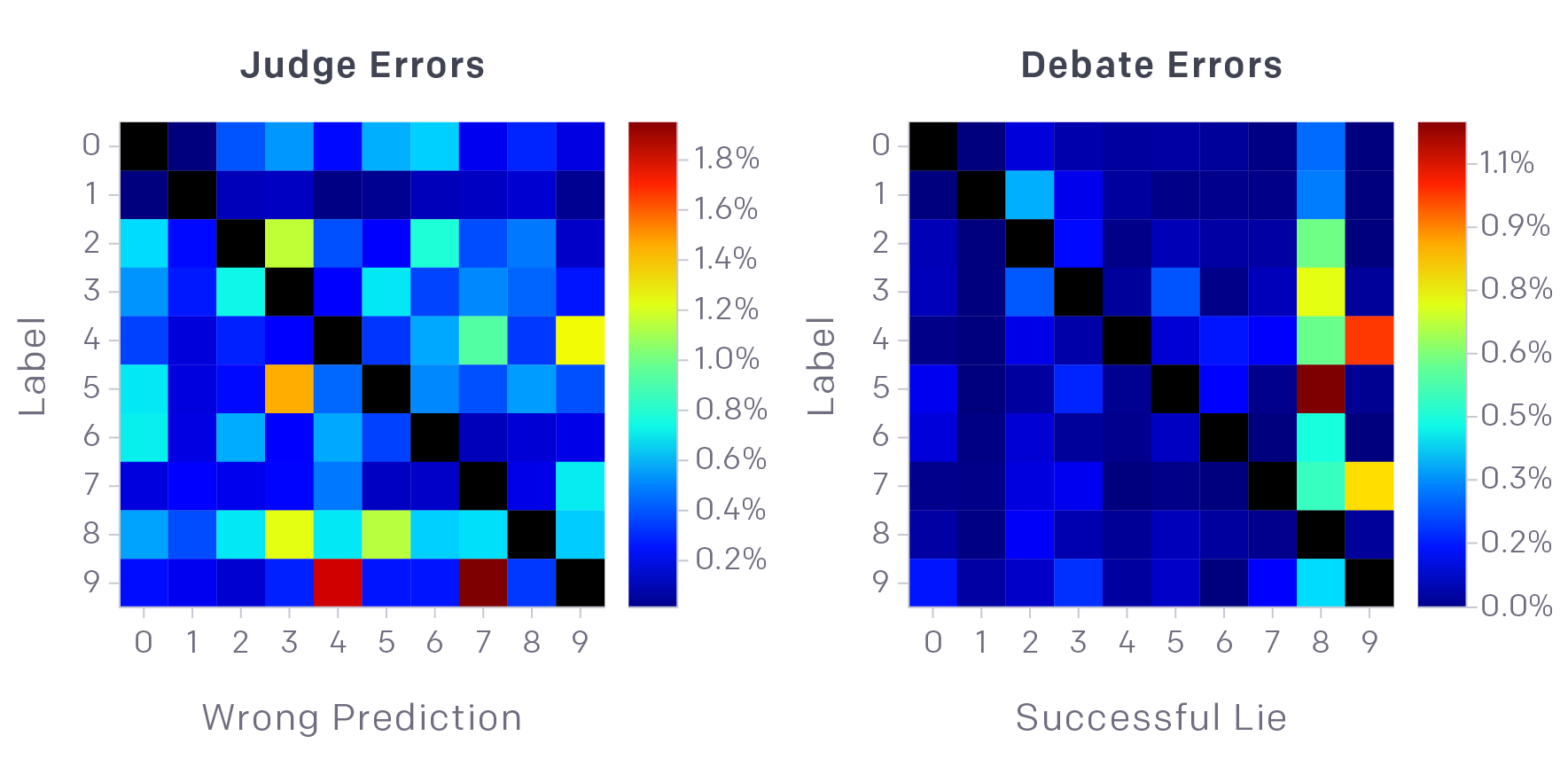
对于随机像素上取6个像素MNIST判断(左侧)和辩论后的判断(右侧)的混淆矩阵(对角线设置为零)。具有6个随机像素的错误没有明显的模式,而成功的辩论则集中在数字8和9上。特别容易让法官把5当成8,或把4当成9。这可能是由于人为将比赛限制为使用非黑色像素导致的:如果你可以显示白色数字8中的黑点,那么证明这个数字实际上不是8会更容易。
猫vs狗的辩论网站
下一个复杂的辩论实验仍然使用图像,但是复杂度提升很大,比如猫和狗。更复杂的图像可能需要一些自然语言或常识推理,然而我们还没有为机器学习法官或智能体做这些。所以,我们已经为人类建立了一个这样的网站来尝试这种实验,扮演法官和辩手的角色。 这里智能体可以用自然语言与法官交谈(网站假设人类有办法沟通或本身就在同一个房间内),但他们的所有陈述都可能是谎言。每个智能体可以在辩论过程中显示一个像素,并且该像素保证是真实的。
辩论网址:https://debate-game.openai.com/

两位人类辩手和一位人类法官进行的辩论,只有辩手才能看到图像。红色争辩说它是一只狗,蓝色争辩说它是猫。
在一场典型的辩论中,爱丽丝可能会诚实地声称这张图片是一只猫,而鲍勃却说谎并宣称它是一只狗。爱丽丝可以说:“这个小矩形的中心是猫的绿眼睛。”鲍勃不能承认这个中心是一只眼睛,所以他编造了另一个谎言:“这是一只在草地上玩的狗,绿色的是草地。”但是这个谎言很难与周围的事实保持一致,比如爱丽丝的回答是:“如果是草,那么在这个细长的矩形的顶部或底部会出现绿色”。辩论一直持续到辩手专注于一个他们意见不同并且鲍勃无法捏造出合理解释的像素为止,此时爱丽丝获胜。我们在OpenAI上随意的玩过几次这款游戏,诚实的智能体确实更容易赢(尽管我们为了公平对待,限制了法官获取信息的比率)

与两个人类辩手和一个人类法官玩猫与狗。
局限性和未来工作方向
我们的大部分论文分析都是辩论的概念,上面的实验比较初级。将来,我们希望做更多困难的视觉实验并最终以自然语言进行实验。法官最终应该是人类(或者是从少数人类判断中训练出来的模型),而不是那些隐喻地代表人类的ML模型。智能体最终应该是功能强大的ML系统,它可以做人类无法直接理解的事情。在人类偏见发挥作用的情况下,对于价值负载(value-laden)的问题进行辩论也很重要,测试是否有可能从有偏见的人类法官那里获得无偏的态度。
即使有了这些改进,辩论模型也存在一些根本的局限性,可能需要用其他方法来改进或增强。比如,辩论不会试图解决对抗性样本或分布转换等问题,它是一种获得复杂目标训练表示的方法,而不是一种保证这些目标的鲁棒性的方法(需要通过附加技术来实现)。也无法保证辩论会得到最佳表现或正确的表述,自我游戏在围棋和其他游戏的实践中运行良好,但我们没有理论保证它的表现。接受辩论训练的智能体比被训练直接回答问题的(即使答案是糟糕的并且不稳定)耗费更多的计算能力,所以有可能它可能无法与更小、更便宜的方法竞争。最后,人类可能不是合适的法官,因为他们不够聪明,即使在智能体放大最简单可能有争议事实也无法理解,或者因为人类的偏见,他会相信任何他们想相信的事情,而不是去做出好的判断。这些问题大多是我们希望调查的实证的问题。
如果辩论或类似的方法奏效,它会通过将人工智能与人类的目标和价值观保持一致的办法,让未来的人工智能系统更安全,即使这个人工智能强大到无法直接进行人类监督。而对于人类可以监督的较弱的系统,通过削减所需的样本复杂度,捕获目标下为任务中强性能所需的样本复杂度,辩论也可以使校正任务更加容易。
openai:blog.openai.com/debate/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消