











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






入门指南:ANN如何使用嵌入概念化新想法
2018年05月05日 由 浅浅 发表
133904
0
我们所感知到的一切都是大脑基于过去经历和从其他媒介获得的知识,经过概率运算得出的最好预测——这样的说法对你来说或许很新鲜,而且听起来好像是对直觉的否定,毕竟我们一直认为,大脑给出的都是确定的答案。
那么我们来做一个小实验解释这种逻辑,请看下面的图片:

问题1:你看出一个人了吗?
问题2:你能辨认出这个人吗?
问题3:你能辨认出这个人衣服的颜色吗?
将这些问题谨记在心,在读完文章内容后,你还会回到这些问题上来。
如果你把人工神经网络与人脑功能相比较,那么它就很好理解了。我们将探讨嵌入(embedding)的概念。首先,需要理解在人脑空间中嵌入的含义,然后再来看它的用途及使用案例。
内容目录:
- 一个简单的思维实验
- 人脑领域中的嵌入
- 人工神经网络领域中的嵌入
- 语义嵌入的应用
- 从数据中学习嵌入
- 文本嵌入形式
- 流行的词嵌入算法
- 图像和语音嵌入
- One shot learning
- 孪生网络
一个简单的思维实验
让我们回到刚才的实验中。回忆一下那个模糊的图片以及那三个问题。所有人都猜得出第一个问题的答案,大多数人也能回答第二个问题,只有一些人可能会猜出第三个问题。
为你对每一题的自信水平打分(满分为100分),并求出平均分。为什么你无法打出满分?原因很简单,我们的大脑没有足够的数据能够百分百识别这张图片。来看下面的图:

现在来回答那三个问题。这次你能得到100分了吗?你可能认为我们的大脑为这三个问题给出了确定的值。但事实上大脑做出预测只是无限接近于1.0的可能性,因为这次大脑得到了足够的信息。
现在让实验变得更有趣吧,再看一遍第一张图,然后估算自信分数。这次你的分数是不是比之前高了?如果答案是肯定的,那么理由很简单,你的大脑调出了过去的记忆,增加了那些图片中模糊掉的新信息,因此增加了自信分数。这个新信息就是大脑之前一定保存过一张非常相似的图片。
上述实验表明,我们的大脑试图预测周围的一切,并做出最好的猜测。这种说法在某种程度上是正确的,我们的大脑甚至需要通过经验来预测身体部位的位置。大脑甚至无法确定你的手、腿或胸部的位置。可以搜索身体转移错觉(body transfer illusion),阅读相关的实验。
人脑领域中的嵌入
思考一个问题:如果我们的大脑用过去经验或数据来预测一切,那么如果处于没有先验经验或常识的场合,我们怎么处理好事务?比如,如果我们去杂货店买一种叫做Alphaberry的全新水果,我们要如何处理它?
可能你会把它放在冰箱里,洗干净然后吃掉。虽然你完全没接触过这种水果,但你怎么会知道要这样处理?事实证明,我们的大脑试图创造对一切事物的语义理解,并通过经验进行调整。这种最初的语义理解开了个好头。
比如,大脑知道Alphaberry是一种水果,它会调出其他水果的大量信息。我们可以吃掉它,而不会有任何危险。一旦我们吃了这种水果,我们的大脑就会添加新的信息来完善Alphaberry的语义表征。
大脑可用这些语义表征发现概念或物体之间的相似性,或者进行类比或推理。Alphaberry只是我们记忆中的语义表征的名称。
当我问你,你尝过Alphaberry吗?这时你的大脑就会寻找Alphaberry的语义表征,并检索关于这种水果的所有经验和信息。然后大脑会评估此问题的所有答案,最后给出适当的回答——“这种水果很甜”。
下面再举一个例子。20*10是多少?显然答案是200。数字不像文字和图片,它们的语义本身就已被编码了。因此,我们的大脑把10和20看作语义本身,而非语义的名称。
大脑可以直接对这些数字进行操作,而不像alphaberry那样,在可以回答有关它的任何问题之前,必须检索语义表征。这是一个很重要的概念,我们将在后文中介绍这个概念。
上面的描述,只是对复杂的大脑处理事务过程的过度简化。在下一节中,我们将讨论人工神经网络(ANN)中使用的概念,它与人类的语义表征是类似的。
人工神经网络领域中的嵌入
过去十年间,计算机处理数字效率越来越高(甚至比人类更快)。计算机只能处理数字,因为它们是唯一具有语义编码的实体。我们怎样才能让计算机理解文字、图像、音频或视频这样的概念呢?
答案就在我们之前讨论的部分。我们需要这些概念的语义表征以数字或数组的形式呈现出来,因为计算机可以理解数字。重要的是,数组可以很好地表示实体的语义,否则这类模型就会出现无用输入无用输出的情况。
我们将对比表示语义的两个模型,以便更深入地理解这个概念。现在我们来讨论6个概念的表征:狮子,幼兽,猫,小猫,苹果,Alphaberry。每个概念都对应一张图片,你需要用数字形式来表示它们。
第一个模型是用独热编码向量来表征单词。表征如下:
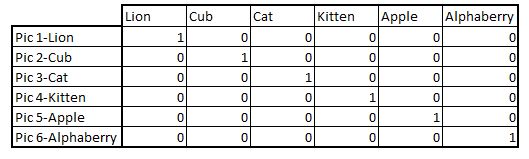
第一个模型是用独热编码向量来表征单词。表征如下:
第二个模型基于每个图片的属性,更符合图片的语义或含义。例如:
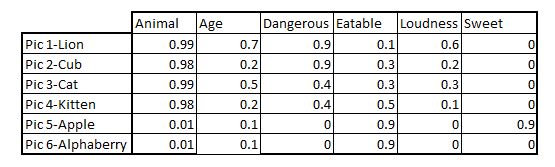
现在让我们对比一下。分别用两种表征回答下列问题。
- 如果你不知道什么是Alphaberry,哪一种方法会让你对这个事物至少有一些基本的了解?
- 如果问题是“小猫是指幼猫,那么幼狮应该叫什么”?哪一种表征可以得出合理的结论?
- 如果我想吃点甜的东西,以上六种应该选择哪个?想象一下,如果我们的大脑给出的答案是狮子,显然答案错误,然而我们从不质疑我们的大脑不是吗?
我相信你们看出来了,第二种表征在这三个问题上的表现都很好。语义表征不仅让我们适用于Alphaberry这样的新概念,还能帮我们做出逻辑推断。例如,如果你用数学方法做下面的任务,你会找到第二个问题的答案:

现在我们可以对文字、图片、音频这样的抽象概念进行数学运算。我们还知道,用于抽象概念的数字向量形式的语义表征对我们的ANN模型很有帮助。
不过文字、图像、音频如此之多,我们如何为所有这些创建语义表征呢?答案很简单,就是学习大量的数据。这种学习的特性更加抽象,而不像上面的演示示例中使用的那样具象。
语义嵌入的应用
正如大脑在所有的认知任务中使用语义一样,人工神经网络使用语义嵌入来完成各种任务。
我们将根据3种主要的嵌入类型来对这些应用进行分类。
- 词嵌入:在自然语言处理(NLP)中,经常使用到词嵌入。例如情绪分析、主题建模等等。
- 图像嵌入:图像嵌入也是研究的热门。重要应用包括面部识别、人脸识别等。例如,百度使用图像嵌入来匹配人的图像,雇员在员工数据库匹配人脸后才能进入办公室。
- 语音嵌入:这种方法可以为呼叫中心省很多经费。语音嵌入最强大的应用之一是语音生物识别技术(voice biometric)。呼叫中心可以使用这种方法捕捉声纹(非常类似于指纹),以识别认证客户身份。
下面现在让我们试着理解学习嵌入的一般概念。
从数据中学习嵌入
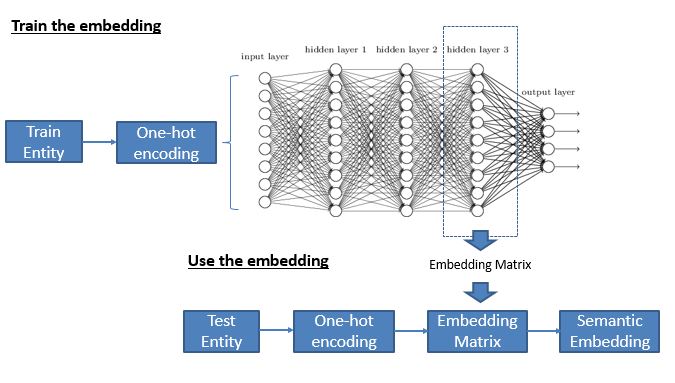
开发各种类型的嵌入的基本方法大致相同。我们用独热编码的实体(一个单词或图像或音频)准备训练数据,定义一些目标函数并开发神经网络。然后把神经网络的最后一层丢掉,将中间层的权值作为嵌入。下面是通用流程:
文本嵌入形式
大多用于训练文本嵌入的算法都运行在非常简单的框架上。下面举一个例子来理解这一点。我们将用下面的句子来说明这一逻辑:

- 我们会从这个句子中随机选择一个目标词,比如“playing”
- 现在我们选择一个超参数“range=2”。这意味着我们将选择单词“playing”的前后两个单词
- 的语境向量变成[“have”,”been”,”cricket”,”since”]
- 为语境和目标词创建独热编码向量
- 初始化嵌入矩阵的行数作为词汇表的大小,列数作为我们需要的特性数量
- 现在我们定义了神经网络体系结构来学习嵌入矩阵
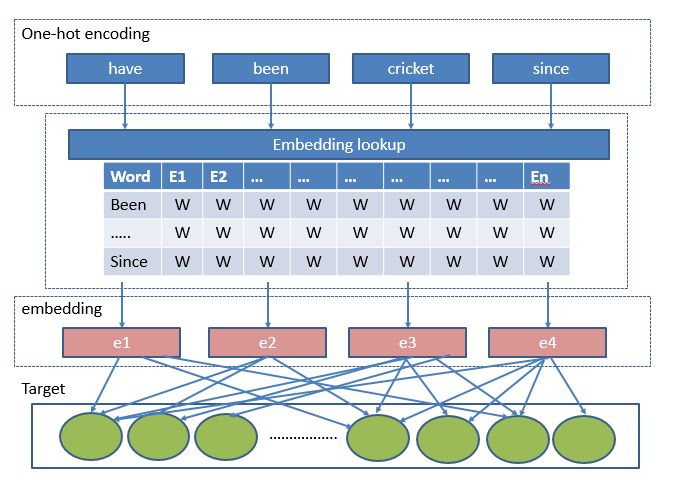
- 训练网络并在获得嵌入矩阵最终的权重
流行的词嵌入算法
Word2vecW是最流行的嵌入算法。它适用于通用算法的简单场景。我们随机选择一个目标词,然后从通用语境向量中选择一个词作为最终语境。例如,我们可以选择“playing”作为目标向量,“cricket”作为语境。现在运行上一节讨论的通用模型。
这种方法的唯一缺陷是,在最后的框架计算softmax函数成本很高。这是因为输出节点的大小与词汇表大小(通常超过10k)相同。你可以使用预训练的word2vec矩阵来处理商务案例以控制成本。
Negative Sampling是另一个强大的概念,它避免了word2vec的缺陷。我们将问题转换为二元分类,而无需多个输出节点。目标词也是随机选择的。我们最初选择一个适当的、类似的单词作为语境词,然后从字典中选择随机单词。接着对每一对进行单独的观察。
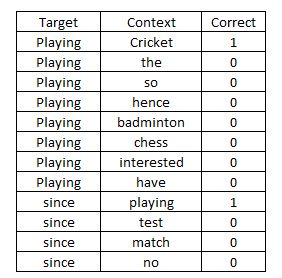
在上面的表格中,我们用“correct”作为输出节点,并将该模型视为二元分类器。因此,我们可以避免用word2vec算法计算softmax函数时成本高的缺陷。
其他算法:如GloVe词向量等其他算法也在业界广泛使用。所有的模型都在相同的通用架构上运行,只是细节不同。如果你有小的数据集,建议使用预训练嵌入。这些嵌入已经接受了数百万个文档训练,因此语义信息非常精确。
图像和语音嵌入
词嵌入的使用最为频繁,但涉及到实际应用时,图像和语音嵌入也毫不逊色。图像和语音嵌入的主要用途是身份验证。在我们分享私人信息之前,会对每个行业的客户进行认证。你可能遇到过嵌入的情况但完全没有意识到。
思考下面的例子:
- 你用指纹解锁手机
- 你让Google home或alexa告诉你当天的日程
- 你的Facebook账户在没有提示的情况下会自动识别你所有的朋友
- 你向银行打电话时需要语音验证
你应该接触过上面的例子。其中每一个都主要基于图像或语音嵌入。对语音和图像进行分析都是用几近相同的架构,多个声音或图像与相同的目标作比对找到相似之处。唯一的差异在于首先用滤镜库或mfcc将语音转换成图像,以便将人类感知声音的过程可视化。这与图像嵌入的形成过程相同。在语音和图像领域中,有两个用途广泛的例子:
- 验证:用已知的一对图像或声音进行验证,验证是否相似。比如,当你用指纹解锁手机时,手机已知哪个是机主的指纹,于是将指纹进行一对一匹配。这种应用方式就是验证,是计算成本较低的用例。另一个类似的语音用例是询问Google Home个人信息。Google Home会首先验证你的声音,然后再给你这些私人信息。
- 识别:这个任务复杂得多。算法试图从多种可能性将人识别出来。例如,在Facebook上发布一张你和朋友的合影时,Facebook的算法会试图将你的朋友的脸与你所有的朋友进行匹配。如果找到匹配,就会提出建议。如果我们将识别同时用于辨别和验证,那么情况就更加复杂了。百度已经设立了这样的系统来识别进入公司的员工。这一情况更为复杂的原因是,算法必须进行大量的匹配,只有当它非常确信匹配正确时才会返回真值。百度的系统也区分了出现的人脸是真人还是静态图片。这一功能使得面部识别系统非常实用。
One shot learning
为什么在验证或识别任务中我们需要嵌入?为什么我们不能分别为每个面孔或声音训练一个模型呢?我们已经知道神经网络需要大量的数据提高精准度。然而,我们大多数的验证或识别任务都是one shot learning。One shot learning只需学习一个或少数几个例子。例如,百度的系统可能只有每个员工的一到两张照片。如果每个类只有几个数据点,我们如何创建模型呢?这就是为什么我们为每个图像创建嵌入并尝试在嵌入之间找到相似之处。一旦图像或语音嵌入的神经网络结构训练完成,这个概念就更好理解了。
孪生网络
训练图像嵌入的神经网络结构通常被称为孪生网络(Siamese Network)。这里只列出用于创建图像嵌入的其中一个算法。我们用这个方法在总体中随机选择两张图片,然后通过共享的CNN堆栈层发送出去。我们得到的输出向量是图像嵌入。然后我们比较两个嵌入之间的差异。将这一差异导入激活函数来检查图像是否属于同一个人。
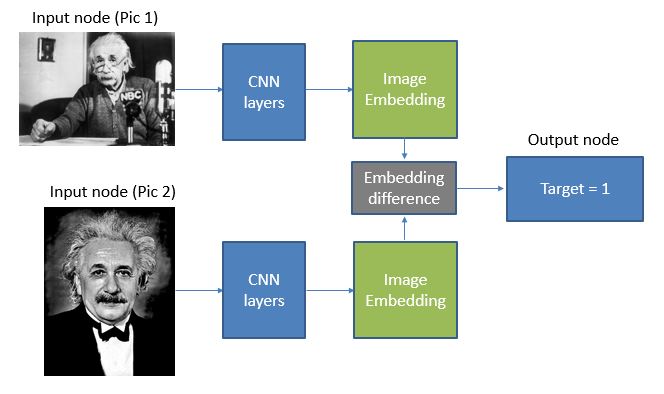
注意,我们在这个过程中所得到的嵌入矩阵不是针对一个特定的人,而是找出一种特征,能告诉我们“这两个面孔看起来有多相似”。
总结
希望读完这篇文章,你已经基本理解了嵌入的概念,并了解在分析非结构化数据时它的重要性。简而言之,我们试图用嵌入非结构化潜在数据来创建结构化的数据。这种结构化数据具有潜在数据嵌入到向量形式的含义,因此叫做嵌入。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消