在与谷歌创意实验室的合作,我很高兴地宣布的发行TensorFlow.js版本PoseNet 机器学习模型,它允许在浏览器中实时进行人体识别。


PoseNet可以在图像和视频中使用单姿态或多姿态的算法来检测人体数据——并且都在浏览器内。
那么,姿态估计是什么?姿态估计是指在图像和视频中检测人物的计算机视觉技术,以便人们可以确定某个人的肘关节在图像中出现的位置。要清楚的是,这项技术并不能识别谁在图像中 - 即没有识别个人身份信息。该算法简单地估计关键身体关节的位置。
那么,这有什么可兴奋的呢?姿态估计有很多用途,从对身体反应的互动装置到增强现实、动画、健身用途等。我们希望此模型的可访问性能够激励更多的开发人员和制造商尝试将姿态检测应用到他们自己的独特项目中。虽然许多替代姿态检测系统都是开源的,但都需要专门的硬件或相机,以及繁琐的系统设置。PoseNet运行在TensorFlow.js上任何拥有普通摄像头的桌面或手机的人都可以在网络浏览器中体验这项技术。而且由于我们已经开源了这个模型,JavaScript开发人员可以用几行代码来修改和使用这个技术。更重要的是,这实际上可以帮助保护用户隐私。由于TensorFlow.js上的PoseNet在浏览器中运行,因此任何姿态数据都不会离开用户的计算机。
PoseNet入门
PoseNet可以被用来估计任何一个单个姿态或多个姿态,这意味着它分为检测只有一个人的图像/视频和检测有多个人的图像/视频两个版本。为什么有两个版本?单人姿势检测器更快,更简单,但图像中只显示一个主体。我们先讲它,因为它更容易懂。
在高级姿态估计发生在两个阶段:
- 一个输入的RGB图像通过卷积神经网络馈送。
- 使用单姿态或多姿态解码算法来解码姿势,构建置信度得分,关键点位置和来自模型输出的关键点置信度得分。
让我们回顾一下最重要的:
- 姿势 - 在最高级别,PoseNet将返回一个姿势对象,其中包含每个检测到的人物的关键点列表和实例级别的置信度分数。

PoseNet返回检测到的每个人的置信度值以及检测到的每个姿势关键点。
- 姿势置信度 - 这决定了对姿态估计的整体置信度。它介于0.0和1.0之间。它可以用来隐藏不够强的姿势。
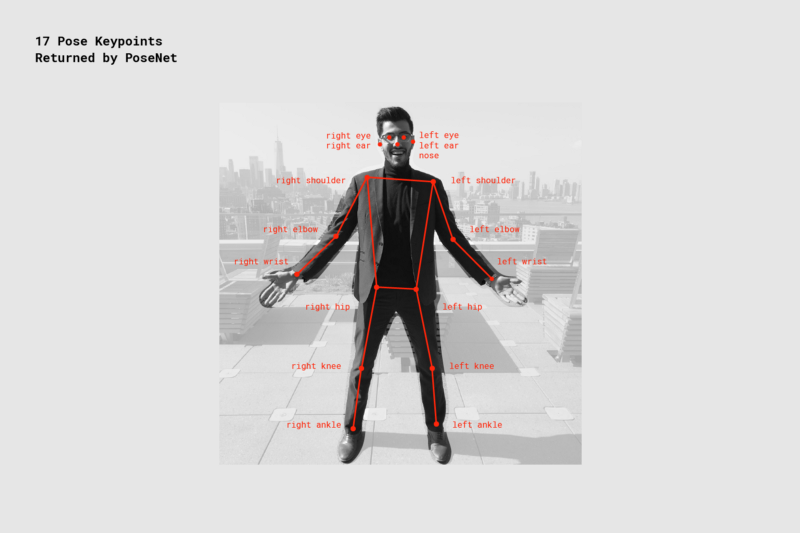
- 关键点 - 估计的人体姿势的一部分,例如鼻子,右耳,左膝,右脚等。它包含位置和关键点置信度分数。PoseNet目前检测到下图所示的17个关键点:
第1部分:导入TensorFlow.js和PoseNet库
很多工作都是将模型的复杂性抽象化并将功能封装为易于使用的方法。让我们回顾一下如何设置PoseNet项目的基础知识。
该库可以用npm安装:
npm install @ tensorflow-models / posnet
并使用es6模块导入:
import * as posenet from '@tensorflow-models/posenet';
const net = await posenet.load();
或通过页面中的一个包:
第2a部分:单人姿态估计

示例单人姿态估计算法应用于图像。图像信用:“Microsoft Coco:环境数据集中的通用对象”
如前所述,单姿态估计算法更简单,速度更快。它的理想用例是当输入图像或视频中只有一个人为中心时。缺点是,如果图像中有多个人,那么来自两个人的关键点可能会被估计为是同一个单一姿势的一部分 。如果输入图像可能包含多人,则应该使用多姿态估计算法。
我们来回顾单姿态估计算法的输入:
- 输入图像元素 - 包含要预测图像的html元素,例如视频或图像标记。重要的是,馈入的图像或视频元素应该是方形的。
- 图像比例尺 - 在0.2和1之间的数字。默认为0.50。在通过网络馈送之前如何缩放图像?将此数字设置得较低以缩小图像,并以精度为代价增加通过网络传输时的速度。
- 水平翻转 - 默认为false。如果姿势应该水平翻转/镜像。对于视频默认水平翻转(即网络摄像头)的视频,这应该设置为true,并且你希望姿势以正确的方向返回。
- 输出步幅 - 必须为32,16或8.默认为16.在内部,此参数会影响神经网络中图层的高度和宽度。在高层次上,它会影响姿态估计的准确性和速度。的下部的输出的值大步精度越高,但速度慢的速度,更高的值更快的速度却降低了精度。查看输出步幅对输出质量的影响的最好方法是使用单姿态估计演示。
现在让我们回顾一下单姿态估计算法的输出:
- 包含姿势置信度得分和17个关键点数组的姿势。
- 每个关键点都包含关键点位置和关键点置信度分数。同样,所有关键点位置在输入图像空间中都有x和y坐标,并且可以直接映射到图像上。
下面的代码块显示了如何使用单姿态估计算法:
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
const imageElement = document.getElementById('cat');
// load the posenet model
const net = await posenet.load();
const pose = await net.estimateSinglePose(imageElement, scaleFactor, flipHorizontal, outputStride);
示例输出姿势如下所示:
{
"score": 0.32371445304906,
"keypoints": [
{ // nose
"position": {
"x": 301.42237830162,
"y": 177.69162777066
},
"score": 0.99799561500549
},
{ // left eye
"position": {
"x": 326.05302262306,
"y": 122.9596464932
},
"score": 0.99766051769257
},
{ // right eye
"position": {
"x": 258.72196650505,
"y": 127.51624706388
},
"score": 0.99926537275314
},
...
]
}
第2b部分:多人姿态估计

示例应用于图像的多人姿态估计算法。图片来源:“Microsoft Coco:上下文数据集中的通用对象”
多人姿态估计算法可以估计图像中的许多姿势/人物。它比单姿态算法更复杂并且稍慢,但它的优点是,如果图片中出现多个人,他们检测到的关键点不太可能与错误的姿势相关联。出于这个原因,即使使用例检测到单个人的姿势,该算法也可能更合乎需要。
此外,该算法的吸引人的特性是性能不受输入图像中人数的影响。无论是15人还是5人,计算时间都是一样的。
让我们回顾一下输入:
- 输入图像元素 - 与单姿态估计相同
- 图像比例因子 - 与单姿态估计相同
- 水平翻转 - 与单姿态估计相同
- 输出步幅 - 与单姿态估计相同
- 最大姿势检测 - 一个整数。默认为5.要检测的姿态的最大数量。
- 姿势信心评分阈值 - 0.0至1.0。默认为0.5。在较高的水平上,这将控制返回姿势的最低置信度分数。
- 非最大抑制(NMS)半径 - 以像素为单位的数字。在较高的水平上,这控制了返回姿势之间的最小距离。这个值默认为20,这在大多数情况下可能是好的。它应该增加/减少,以滤除不太准确的姿势,但只有在调整姿势置信度分数不够好时。
查看这些参数有什么影响的最好方法是使用多姿态估计演示。
让我们回顾一下输出结果:
- 希望以序列姿势解决。
- 每个姿势包含与单人估计算法中描述的信息相同的信息。
下面短代码块显示了如何使用多姿态估计算法:
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
// get up to 5 poses
const maxPoseDetections = 5;
// minimum confidence of the root part of a pose
const scoreThreshold = 0.5;
// minimum distance in pixels between the root parts of poses
const nmsRadius = 20;
const imageElement = document.getElementById('cat');
// load posenet
const net = await posenet.load();
const poses = await net.estimateMultiplePoses(
imageElement, imageScaleFactor, flipHorizontal, outputStride,
maxPoseDetections, scoreThreshold, nmsRadius);
示例输出数组的示例如下所示:
// array of poses/persons
[
{ // pose #1
"score": 0.42985695206067,
"keypoints": [
{ // nose
"position": {
"x": 126.09371757507,
"y": 97.861720561981
},
"score": 0.99710708856583
},
...
]
},
{ // pose #2
"score": 0.13461434583673,
"keypositions": [
{ // nose
"position": {
"x": 116.58444058895,
"y": 99.772533416748
},
"score": 0.9978438615799
},
...
]
},
...
]
如果您已经阅读了这篇文章,那么你就已经知道了可以从PoseNet演示开始。这可能是一个很好的截止点。如果你想知道更多关于模型和实现的技术细节,我们邀请您继续阅读下面的内容。
好奇心:技术深潜
在本节中,我们将介绍关于单姿态估计算法的更多技术细节。在高层次上,这个过程如下所示:
使用PoseNet的单人姿势检测器管道
需要注意的一个重要细节是研究人员训练了ResNet和PoseNet的MobileNet模型。虽然ResNet模型具有更高的准确性,但其大尺寸和多层会使页面加载时间和推理时间对于任何实时应用程序都不理想。我们使用MobileNet模型,因为它设计用于在移动设备上运行。
重新审视单姿态估计算法
处理模型输入:输出步幅的解释
首先,我们将讨论如何通过讨论输出步幅来获得PoseNet模型输出(主要是热点图和偏移矢量)。
方便地,PoseNet模型是图像大小不变的,这意味着它可以以与原始图像相同的比例预测姿势位置,而不管图像是否缩小。这意味着PoseNet可以通过设置上面我们在运行时提到的输出步幅来牺牲性能来配置更高的精度。
输出步幅决定了我们相对于输入图像大小缩小输出的程度。它会影响图层和模型输出的大小。更高的输出步幅,较小网络和输出层中的分辨率,并且相应地其准确性。在此实现中,输出步幅可以为8,16或32的值。换句话说,32的输出步幅将导致最快的性能但最低的精度,而8将导致最高的精度但性能最慢。我们建议从16开始。
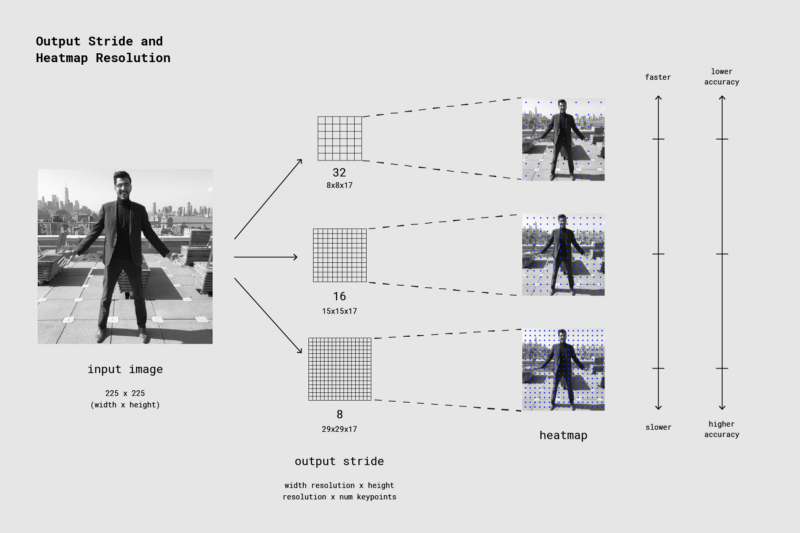
输出步幅决定了我们相对于输入图像大小缩小输出的程度。较高的输出步幅会更快,但会导致精度较低。
当输出步幅被设置为8或16时,层中的输入帧数减少,从而产生更大的输出分辨率。在随后的层中,使用at劳卷积使卷积滤波器具有更宽的视场(当输出步幅为32时,不应用atrous convolution)。虽然Tensorflow支持atrous convolution,但TensorFlow.js没有,所以我们添加了一个PR来包含这个。
模型输出:热图和偏移矢量
当PoseNet处理图像时,事实上返回的是热图以及偏移矢量,可以解码以找到图像中与姿势关键点对应的高置信度区域。我们将在一分钟内讨论它们各自的含义,但现在下面的插图以高级方式捕获每个姿态关键点与一个热图张量和一个偏移矢量张量的关联。
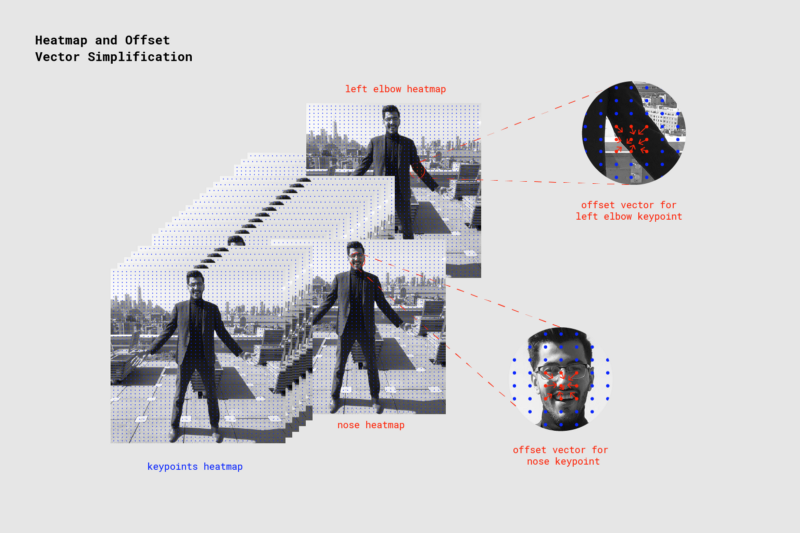
PoseNet返回的17个姿态关键点中的每一个都与一个热图张量和一个偏移矢量张量相关联,用于确定关键点的确切位置。
这两个输出都是具有高度和宽度的3D张量,我们将其称为分辨率。分辨率由输入图像大小和输出步幅根据以下公式确定:
Resolution = ((InputImageSize - 1) / OutputStride) + 1
// Example: an input image with a width of 225 pixels and an output
// stride of 16 results in an output resolution of 15
// 15 = ((225 - 1) / 16) + 1
热图
每个热图是尺寸分辨率x分辨率x 17的3D张量,因为17是PoseNet检测到的关键点的数量。例如,图像大小为225,输出步幅为16,这将是15x15x17。第三维(17)中的每个切片对应于特定关键点的热图。该热图中的每个位置都有一个置信度分数,这是该关键点类型的一部分存在于该位置的概率。它可以被认为是原始图像被分解成15x15网格,其中热图分数提供了每个网格广场中每个关键点存在可能性的分类。
偏移矢量
每个偏移向量都是尺寸分辨率x分辨率x 34的三维张量,其中34是关键点数* 2.图像大小为225,输出步幅为16时,这将是15x15x34。由于热图是关键点位置的近似值,所以偏移矢量在位置上对应于热图表点,并且用于通过沿相应热图点的矢量行进来预测关键点的确切位置。偏移矢量的前17个切片包含矢量的x和最后17个y。偏移矢量大小与原始图像具有相同的比例。
根据模型的输出估计姿势
图像通过模型馈送后,我们执行一些计算来估计输出的姿态。例如,单姿态估计算法返回姿势置信度分数,其自身包含关键点阵列(通过部分D索引),每个关键点具有置信度分数和x,y位置。
为了获得姿势的关键点:
- 在热图上进行sigmoid激活以获得分数。
scores = heatmap.sigmoid()
- argmax2d是根据关键点置信度得分来获得热图中x和y指数,每个部分的得分最高,这基本上是该部分最有可能存在的地方。这会产生一个尺寸为17x2的张量,每一行都是热图中的y和x索引,每个部分的得分最高。
heatmapPositions = scores.argmax(y, x)
- 每个零件的偏移矢量通过从该零件的热图中对应于x和y索引的偏移量中获取x和y来检索。这会产生17x2的张量,每行都是相应关键点的偏移向量。例如,对于索引为k的部分,当热图位置为y和d时,偏移矢量为:
offsetVector = [offsets.get(y, x, k), offsets.get(y, x, 17 + k)]
- 为了获得关键点,将每个零件的热图x和y乘以输出步幅,然后将其添加到它们对应的偏移向量中,该向量与原始图像具有相同的比例。
keypointPositions = heatmapPositions * outputStride + offsetVectors
- 最后,每个关键点置信度分数是其热图表位置的置信度分数。该姿势的置信度得分是关键点的评分的平均值。
多人姿态估计
多姿态估计算法的细节超出了本文的范围。主要地,该算法的不同之处在于它使用贪婪过程通过沿着基于零件的图形的位移矢量将关键点分组为姿态。具体来说,它使用研究论文PersonLab中的快速贪婪解码 算法:人体姿态估计和具有自下而上,基于部分的几何嵌入模型的实例分割。有关多姿态算法的更多信息,请阅读完整的研究论文或查看代码。
论文:https://arxiv.org/pdf/1803.08225.pdf
代码:https://github.com/tensorflow/tfjs-models/tree/master/posenet/src
演示:https://storage.googleapis.com/tfjs-models/demos/posenet/camera.html
我们希望随着越来越多的模型被移植到TensorFlow.js,机器学习的世界变得对新的编码者更友善也更乐趣。TensorFlow.js上的PoseNet是实现这一目标的一个小小尝试。我们很乐意看到你做出了什么,不要忘记使用分享你的精彩项目!




























