











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






google图片识别模型在Android平台小案例
2017年07月03日 由 Neo 发表
708768
0
前两天做了一个在安卓设备上识别物体并分类的小案例,用到的是一个训练好的模型,把图片进行分类,分类的种类比较少,只有在生活中常见的那些物件,并且是按照大类型分的,例如:动物、建筑等这种的分成一类。今天我们用Google官方提供的一个视觉训练模型,来进行识别,并且做成摄像头拍摄模式。
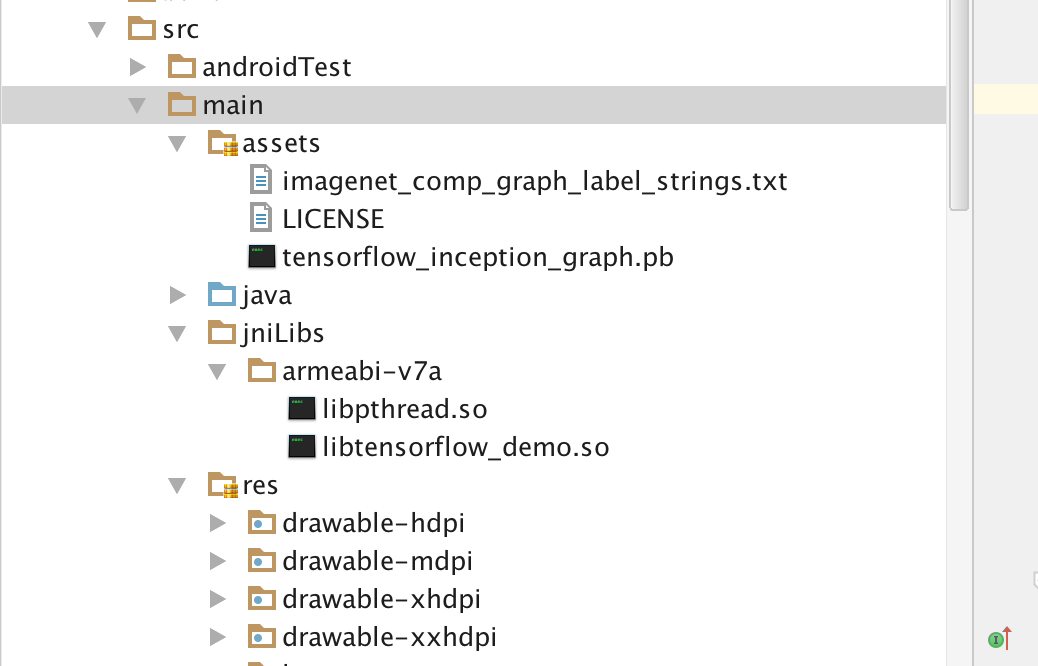
首先在AndroidStudio 2.0+版本,Android SDK 23+的编译环境下创建工程并且导入pb模型文件和labei_string到assets目录下,导入so包到jniLibs文件夹,目录结构如下图:
在清单文件里面申明相机相关权限、对焦权限、以及拍照后文件存储的读写权限:
接着是相机初始化以及自动对焦,在页面上用SurfaceTexture显示图像流。SurfaceTexture是从Android3.0(API 11)加入的一个新类。这个类跟SurfaceView很像,可以从camera preview或者video decode里面获取图像流(image stream)。和SurfaceView不同的是,它对图像流的处理并不直接显示,而是转为GL外部纹理,因此可用于图像流数据的二次处理(如Camera滤镜,桌面特效等)。比如Camera的预览数据,变成纹理后可以交给GLSurfaceView直接显示,也可以通过SurfaceTexture交给TextureView作为View heirachy中的一个硬件加速层来显示。相机初始化主要代码如下图:

获取CameraManager,调取后置摄像头获取图像流,然后将后置摄像头的图像流传输到上述SurfaceTexture中,主要代码如下:

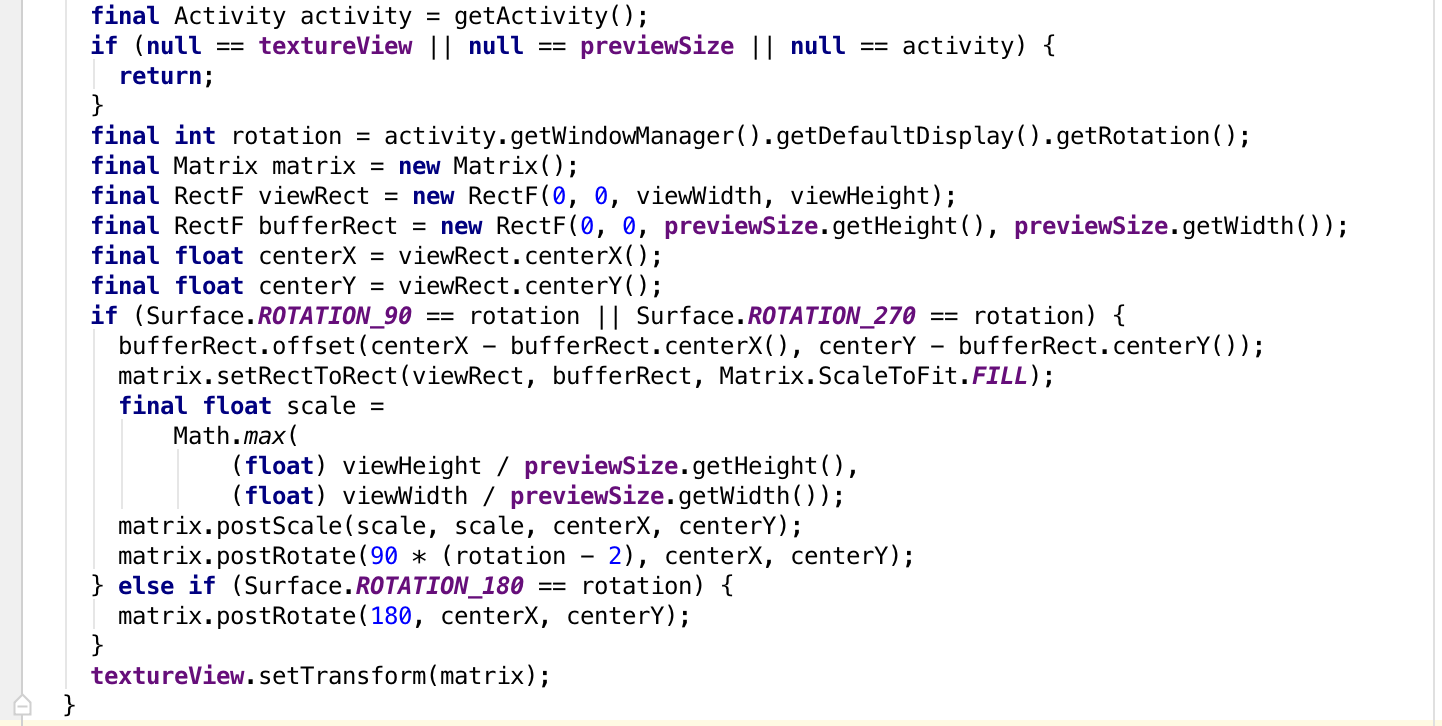
在显示图像流时对SurfaceTexture frame进行设置,确保其完整并合理的显示在屏幕上,如果不设置的话取景区域显示在屏幕上会不完整
接下来要做的就是使用OnImageAvailableListener监听SurfaceTexture内容,并且在onImageAvailable接口里面获取到当前帧数的ImageReader,获取到图片以后确定分辨率,然后将之存储为Bitmap

最后调用tensorflow的图像识别方法,识别图片,获取识别结果List将之显示在屏幕上,这样就基本完成了今天的示例,我们看一下最后的演示成果

识别结果是斑猫、虎斑猫、埃及猫

键盘

电风扇
识别效果总体还是令人满意的,这个识别模型较前阵子图片分类的例子要全面得多,总共有1000多种的物品分类,而图片分类那个只有10多个,经测试,识别的效率是相差无几的,都可以达到基本没有延时
[download id="3"]
首先在AndroidStudio 2.0+版本,Android SDK 23+的编译环境下创建工程并且导入pb模型文件和labei_string到assets目录下,导入so包到jniLibs文件夹,目录结构如下图:
在清单文件里面申明相机相关权限、对焦权限、以及拍照后文件存储的读写权限:
接着是相机初始化以及自动对焦,在页面上用SurfaceTexture显示图像流。SurfaceTexture是从Android3.0(API 11)加入的一个新类。这个类跟SurfaceView很像,可以从camera preview或者video decode里面获取图像流(image stream)。和SurfaceView不同的是,它对图像流的处理并不直接显示,而是转为GL外部纹理,因此可用于图像流数据的二次处理(如Camera滤镜,桌面特效等)。比如Camera的预览数据,变成纹理后可以交给GLSurfaceView直接显示,也可以通过SurfaceTexture交给TextureView作为View heirachy中的一个硬件加速层来显示。相机初始化主要代码如下图:
获取CameraManager,调取后置摄像头获取图像流,然后将后置摄像头的图像流传输到上述SurfaceTexture中,主要代码如下:
在显示图像流时对SurfaceTexture frame进行设置,确保其完整并合理的显示在屏幕上,如果不设置的话取景区域显示在屏幕上会不完整
接下来要做的就是使用OnImageAvailableListener监听SurfaceTexture内容,并且在onImageAvailable接口里面获取到当前帧数的ImageReader,获取到图片以后确定分辨率,然后将之存储为Bitmap
最后调用tensorflow的图像识别方法,识别图片,获取识别结果List
识别结果是斑猫、虎斑猫、埃及猫
键盘
电风扇
识别效果总体还是令人满意的,这个识别模型较前阵子图片分类的例子要全面得多,总共有1000多种的物品分类,而图片分类那个只有10多个,经测试,识别的效率是相差无几的,都可以达到基本没有延时
[download id="3"]

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消