











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌研究利用AI合成图片,使静态图片动起来
2018年05月28日 由 浅浅 发表
848822
0

谷歌的研究人员开发了一个基于深度学习的系统,可以将立体相机,VR相机和双镜头相机(如iPhone 7或X)拍摄的静态图像转换为短视频。
“给出两个图像与已知的相机参数,我们的目标是让深层神经网络来推断适合于合成同一场景的视角,特别是在输入视图之外进行推断。”研究人员在研究中写道。
研究者使用NVIDIA的Tesla GPU的P100和cuDNN -accelerated TensorFlow深度学习框架,基于7000多个房地产类视频训练系统。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2018/05/SIGGRAPH-2018-Stereo-Magnification-Learning-view-synthesis-using-multiplane-images.mp4"][/video]
“我们基于多平面图像(MPI)的视点合成系统可以处理室内和室外场景,”研究人员提出,“我们成功地将它应用于与我们训练数据集中场景截然不同的场景。学习过的MPI可以有效地表现出部分反射或透明的表面。”
该团队表示,他们的系统比以前的方法性能更好,并且可以有效地放大手机和立体相机拍摄的立体图像的狭窄基线。
“我们的方法在保留测试中表现出更好的数字性能,并且还生成了更多空间稳定的输出图像,因为我们推断的场景视图综合了所有合成的目标视图。”
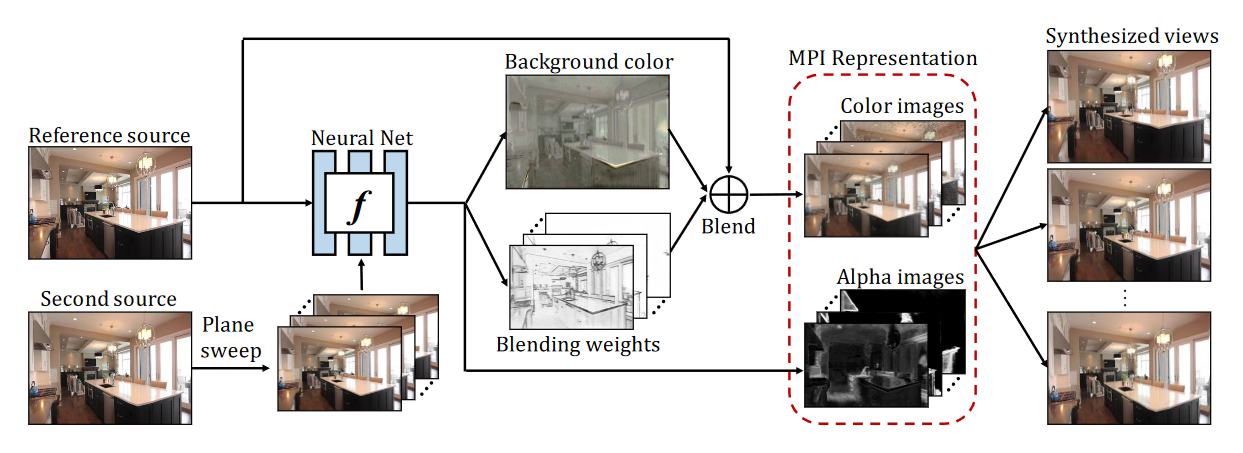
端到端学习管道概述。给定输入立体图像对,团队使用全卷积深度网络来推断多平面图像表示。对于每个平面,网络直接预测alpha图像,并且通过使用参考源和预测背景图像混合彩色图像,其中混合权重也是用网络输出。在训练期间,网络被优化,以预测使用可微分渲染模块重建目标视图的MPI。在测试过程中,MPI视图表示仅针对每个场景推断一次,然后可以用最少量的计算(单应性和alpha合成)来合成新视图。
该团队承认他们的模型还有待改善,但他们相信该方法可用于从两个输入图像中推断数据,生成允许多维视图移动的光场。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消