











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何使用Keras在Python中开发用于序列分类的双向LSTM
2017年07月03日 由 yuxiangyu 发表
137622
0
双向LSTM是传统LSTM的扩展,可以提高序列分类问题的模型性能。
在输入序列的所有时间步长可用的问题中,双向LSTM在输入序列上训练两个而不是一个LSTM。输入序列中的第一个是原样的,第二个是输入序列的反转副本。这可以为网络提供额外的上下文,并导致更快,甚至更充分的学习问题。
在本教程中,您将发现如何使用Keras深度学习库在Python中开发用于序列分类的双向LSTM。
完成本教程后,您将知道:
如何开发一个小的、可设计的、可配置的序列分类问题。
如何为序列分类开发LSTM和双向LSTM。
如何在双向LSTM中应用中比较合并模式的性能。
让我们开始吧

如何开发带有Keras的Python序列分类的双向LSTM(照片版权所有Cristiano Medeiros Dalbem)
概观
本教程分为6部分; 他们是:
- 双向LSTM
- 序列分类问题
- LSTM序列分类
- 双向LSTM序列分类
- 将LSTM和双向LSTM作比较
- 比较双向LSTM不同的合并模式
环境
本教程假定您已安装Python SciPy环境。您可以使用Python 2或3与此示例。
本教程假定您使用了TensorFlow(v1.1.0 +)或Theano(v0.9 +)后台,安装了Keras(v2.0.4 +)。
本教程还假定您已经安装了scikit-learn,Pandas,NumPy和Matplotlib。
如果您需要帮助设置您的Python环境,请参阅这篇文章:
双向LSTM
双向循环神经网络(RNNs)的概念很简单。
它涉及复制网络中的第一个循环层,使得现在有两层并排,然后将输入序列原样提供给第一层的输入,并将输入序列的反向副本提供给第二层。
为了克服常规RNN的局限[...],我们提出了可以使用特定时间框架的过去和未来的所有可用输入信息进行训练的双向循环神经网络(BRNN)。
...
这个想法是将负责正时间方向(正向状态)的部分和负时间方向的一部分(后向状态)分割成正常RNN的状态神经元,
- Mike Schuster和Kuldip K. Paliwal,Bidirectional Recurrent Neural Networks,1997
这种方法对于LSTM的递归神经网络有重大影响。
双向提供序列的使用最初在语音识别领域是合理的,因为有证据表明整个话语的上下文用于解释所说的内容而不是线性解释。
依靠未来的知识视乎违背了因果关系。我们怎么能把我们对所听到的事情的理解建立在还没有听到的事情上呢?然而,人类就是这样做的。从未来的角度看,我们听到的声音、单词甚至是句子一开始都毫无意义。我们必须记住的是,真正在线的任务之间的区别即:每次输入后都需要一个输出和某些输入段结束时才需要输出。
- Alex Graves和Jurgen Schmidhuber,Framangular Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures,2005
使用双向LSTM可能不会对所有序列预测问题都有意义,但是可以对适合的领域提供更好的结果。
我们发现双向网络比单向网络显着更有效
- Alex Graves和Jurgen Schmidhuber,Framangular Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures,2005
要知道,输入序列中的时间步仍然一次处理一个,只是同时在网络的从两个方向通过输入序列而已。
Keras中的双向LSTM
Keras通过双向层包装器支持双向LSTM 。
这个包装器需要一个循环层(例如第一个LSTM层)作为参数。
它还允许你指定合并模式,也就是在传递到下一个层之前,如何组合前向和后退输出。选项有:
- ' sum':输出相加。
- ' mul':输出相乘。
- ' concat':输出连接在一起(默认),将输出数量提高到下一层的两倍。
- ' ave':输出的平均值。
默认模式是连接,这是双向LSTM研究中经常使用的方法。
序列分类问题
我们将定义一个简单的序列分类问题来探索双向LSTM。
该问题被定义为0和1之间的随机值序列。该序列作为每个时间步长每个数字的问题的输入。
二进制标签(0或1)与每个输入相关联。输出值全为0.一旦序列中的输入值的累积和超过阈值,则输出值从0翻转为1。
使用序列长度的1/4。
例如,下面是10个输入时间步长(X)的序列:
| 0.63144003 0.29414551 0.91587952 0.95189228 0.32195638 0.60742236 0.83895793 0.18023048 0.84762691 0.29165514 |
相应的分类输出(y)为:
| 0 0 0 1 1 1 1 1 1 1 |
我们可以在Python中实现。
第一步是生成一系列随机值。我们可以使用随机模块中的random()函数。
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(10)])
我们可以将阈值定义为输入序列长度的四分之一。
# calculate cut-off value to change class values
limit = 10/4.0
可以使用cumsum()NumPy函数计算输入序列的累积和。该函数返回累积和值的序列,例如:
| 1 | pos1, pos1+pos2, pos1+pos2+pos3, ... |
然后,我们可以计算输出序列,以确定每个累积和值是否超过阈值。
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
下面的名为get_sequence()的函数将所有这些函数一起绘制,作为输入序列的长度,并返回一个新的问题情况的X和Y组件。
from random import random
from numpy import array
from numpy import cumsum
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
return X, y
我们可以用新的10个时间步序来测试这个函数,如下所示:
X, y = get_sequence(10)
print(X)
print(y)
运行示例首先打印生成的输入序列,然后输出匹配的输出序列。
| | [ 0.22228819 0.26882207 0.069623 0.91477783 0.02095862 0.71322527 0.90159654 0.65000306 0.88845226 0.4037031 ] [0 0 0 0 0 0 1 1 1 1] |
LSTM用于序列分类
我们可以通过开发用于序列分类问题的传统LSTM来开始。
首先,我们必须更新get_sequence()函数,以将输入和输出序列重新形成3维以满足LSTM的期望。预期的结构具有尺寸[样本,时间步长,特征]。分类问题具有1个样本(例如一个序列),可配置的时间步长数量和每个时间步长的一个特征。
分类问题具有1个样本(例如一个序列),可配置的时间步长数量和每个时间步长的一个特征。
因此,我们可以按如下顺序重新整理。
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
更新的get_sequence()函数如下所示。
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
我们将把序列定义为具有10个时间步长。
接下来,我们可以为问题定义一个LSTM。输入层将具有10个时间步长,其中1个特征为一组,input_shape =(10,1)。我们将把序列定义为具有10个时间步长。
第一个隐藏层将具有20个存储单元,输出层将是完全连接的层,每个时间步长输出一个值。在输出端使用S形激活函数来预测二进制值。
在输出层周围使用TimeDistributed包装层,以便在提供的完整序列作为输入时,可以预测每个时间步长的一个值。这要求LSTM隐藏层返回一个值序列(每个时间步长一个),而不是整个输入序列的单个值。
最后,因为这是二进制分类问题,所以使用二进制日志丢失(Keras中的binary_crossentropy)。使用有效的ADAM优化算法找到权重,并计算每个时期报告的精度度量。
# define LSTM
model = Sequential()
model.add(LSTM(20, input_shape=(10, 1), return_sequences=True))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
LSTM将接受1000次训练。将为每次训练生成一个新的随机输入序列,以使网络适合。这样可以确保模型不会记住单个序列,也可以通过推广解决方案来解决所有可能的随机输入序列。
# train LSTM
for epoch in range(1000):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
model.fit(X, y, epochs=1, batch_size=1, verbose=2)
一旦被训练,网络将被评估另一个随机序列。然后将预测与预期输出序列进行比较,以提供系统技能的具体示例。
# evaluate LSTM
X,y = get_sequence(n_timesteps)
yhat = model.predict_classes(X, verbose=0)
for i in range(n_timesteps):
print('Expected:', y[0, i], 'Predicted', yhat[0, i])
完整的示例如下所示。
from random import random
from numpy import array
from numpy import cumsum
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import TimeDistributed
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
# define problem properties
n_timesteps = 10
# define LSTM
model = Sequential()
model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
# train LSTM
for epoch in range(1000):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
model.fit(X, y, epochs=1, batch_size=1, verbose=2)
# evaluate LSTM
X,y = get_sequence(n_timesteps)
yhat = model.predict_classes(X, verbose=0)
for i in range(n_timesteps):
print('Expected:', y[0, i], 'Predicted', yhat[0, i])
运行示例打印每个时期随机序列的日志丢失和分类精度。
这提供了一个清晰的想法,模型如何推广到序列分类问题的解决方案。运行示例打印每个时期随机序列的日志丢失和分类精度。
我们可以看到,该模型表现良好,达到90%和100%准确度的最终精度。不完美,但对我们的目的有好处。
将新随机序列的预测与预期值进行比较,显示出具有单个错误的大多数正确的结果。
...
Epoch 1/1
0s - loss: 0.2039 - acc: 0.9000
Epoch 1/1
0s - loss: 0.2985 - acc: 0.9000
Epoch 1/1
0s - loss: 0.1219 - acc: 1.0000
Epoch 1/1
0s - loss: 0.2031 - acc: 0.9000
Epoch 1/1
0s - loss: 0.1698 - acc: 0.9000
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
双向LSTM用于序列分类
现在我们知道如何为序列分类问题开发LSTM,我们可以扩展示例来演示双向LSTM。
我们可以通过用双向层包装LSTM隐藏层来实现,如下所示:
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1)))
这将创建隐藏层的两个副本,一个适合输入序列,一个在输入序列的反转副本上。默认情况下,这些LSTM的输出值将被连接。
这意味着,代替时分布层接收到20个输出的10个时间步长,它现在将接收10个20(20个单位+20个单位)输出的10个时间步长。
完整的示例如下所示。
from random import random
from numpy import array
from numpy import cumsum
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import TimeDistributed
from keras.layers import Bidirectional
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
# define problem properties
n_timesteps = 10
# define LSTM
model = Sequential()
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1)))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
# train LSTM
for epoch in range(1000):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
model.fit(X, y, epochs=1, batch_size=1, verbose=2)
# evaluate LSTM
X,y = get_sequence(n_timesteps)
yhat = model.predict_classes(X, verbose=0)
for i in range(n_timesteps):
print('Expected:', y[0, i], 'Predicted', yhat[0, i])
运行示例,我们看到与上一个示例类似的输出。
使用双向LSTM具有允许LSTM更快地学习问题的效果。
从运行结束时来看,这并不太明显,但随着时间的推移,也越来越明显。
...
Epoch 1/1
0s - loss: 0.0967 - acc: 0.9000
Epoch 1/1
0s - loss: 0.0865 - acc: 1.0000
Epoch 1/1
0s - loss: 0.0905 - acc: 0.9000
Epoch 1/1
0s - loss: 0.2460 - acc: 0.9000
Epoch 1/1
0s - loss: 0.1458 - acc: 0.9000
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
将LSTM与双向LSTM进行比较
在这个例子中,我们将比较训练中的传统的LSTM与双向LSTM的模型的性能。
我们将调整实验,使模型只能训练250个时期。这样,我们可以清楚地了解每个模型的学习方式如何展开,以及双向LSTM的学习行为如何不同。
我们将比较三种不同的型号; 具体如下:
- LSTM(按原样)
- 带有输入序列LSTM(例如,您可以通过将LSTM图层的“go_backwards”参数设置为“True”来实现)
- 双向LSTM
这种比较将有助于表明双向LSTM实际上可以增加一些东西,而不仅仅是带有逆转输入序列。
我们将定义一个函数来创建和返回具有前向或后向输入序列的LSTM,如下所示:
def get_lstm_model(n_timesteps, backwards):
model = Sequential()
model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True, go_backwards=backwards))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
我们可以为双向LSTM开发类似的功能,其中可以将合并模式指定为参数。可以通过将合并模式设置为值'concat'来指定连接的默认值。
def get_bi_lstm_model(n_timesteps, mode):
model = Sequential()
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1), merge_mode=mode))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
最后,我们定义一个函数来拟合模型,并且检索和存储每个训练时期的损失,然后在模型拟合之后返回收集的损失值的列表。这样我们可以从每个模型配置中绘制日志丢失并进行比较。
def train_model(model, n_timesteps):
loss = list()
for _ in range(250):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
hist = model.fit(X, y, epochs=1, batch_size=1, verbose=0)
loss.append(hist.history['loss'][0])
return loss
将这一切放在一起,下面列出了完整的例子。
首先创建一个传统的LSTM,并对日志损失值进行匹配。这与使用反向输入序列的LSTM重复,最后是具有级联合并的LSTM。
from random import random
from numpy import array
from numpy import cumsum
from matplotlib import pyplot
from pandas import DataFrame
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import TimeDistributed
from keras.layers import Bidirectional
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
def get_lstm_model(n_timesteps, backwards):
model = Sequential()
model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True, go_backwards=backwards))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
def get_bi_lstm_model(n_timesteps, mode):
model = Sequential()
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1), merge_mode=mode))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
def train_model(model, n_timesteps):
loss = list()
for _ in range(250):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
hist = model.fit(X, y, epochs=1, batch_size=1, verbose=0)
loss.append(hist.history['loss'][0])
return loss
n_timesteps = 10
results = DataFrame()
# lstm forwards
model = get_lstm_model(n_timesteps, False)
results['lstm_forw'] = train_model(model, n_timesteps)
# lstm backwards
model = get_lstm_model(n_timesteps, True)
results['lstm_back'] = train_model(model, n_timesteps)
# bidirectional concat
model = get_bi_lstm_model(n_timesteps, 'concat')
results['bilstm_con'] = train_model(model, n_timesteps)
# line plot of results
results.plot()
pyplot.show()
运行示例创建一个线条图。
您的具体情节可能会有所不同,但会显示相同的趋势。
我们可以看到LSTM向前(蓝色)和LSTM向后(橙色)在250个训练时期显示相似的日志丢失。
我们可以看到双向LSTM日志丢失是不同的(绿色),下降到一个较低的值,一般保持低于其他两个配置。
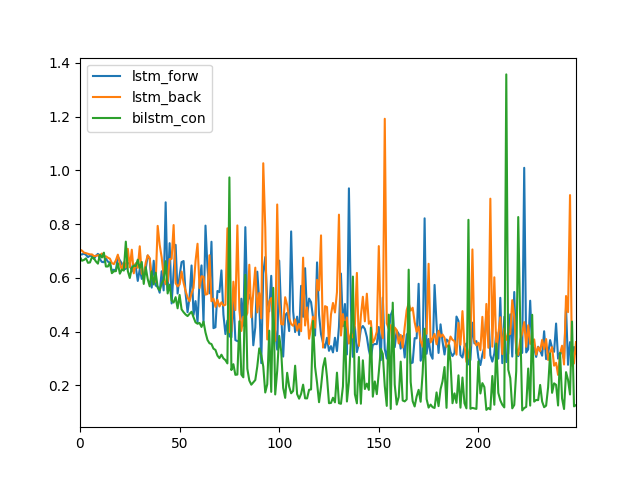
LSTM,反转LSTM和双向LSTM的日志丢失线路图
比较双向LSTM合并模式
有四种不同的合并模式可用于组合双向LSTM层的结果。
它们是连接(默认)、相乘、求平均和相加。
我们可以通过更新上一节中的示例来比较不同合并模式的行为如下:
n_timesteps = 10
results = DataFrame()
# sum merge
model = get_bi_lstm_model(n_timesteps, 'sum')
results['bilstm_sum'] = train_model(model, n_timesteps)
# mul merge
model = get_bi_lstm_model(n_timesteps, 'mul')
results['bilstm_mul'] = train_model(model, n_timesteps)
# avg merge
model = get_bi_lstm_model(n_timesteps, 'ave')
results['bilstm_ave'] = train_model(model, n_timesteps)
# concat merge
model = get_bi_lstm_model(n_timesteps, 'concat')
results['bilstm_con'] = train_model(model, n_timesteps)
# line plot of results
results.plot()
pyplot.show()
运行示例将创建一个线图,比较每个合并模式的日志丢失。
您的具体情节可能不同,但会显示相同的行为趋势。
不同的合并模式导致不同的模型性能,这将根据您的具体序列预测问题而有所不同。
在这种情况下,我们可以看到,求和(蓝色)和连接(红色)合并模式可能会导致更好的性能,或者说至少降低了日志丢失。
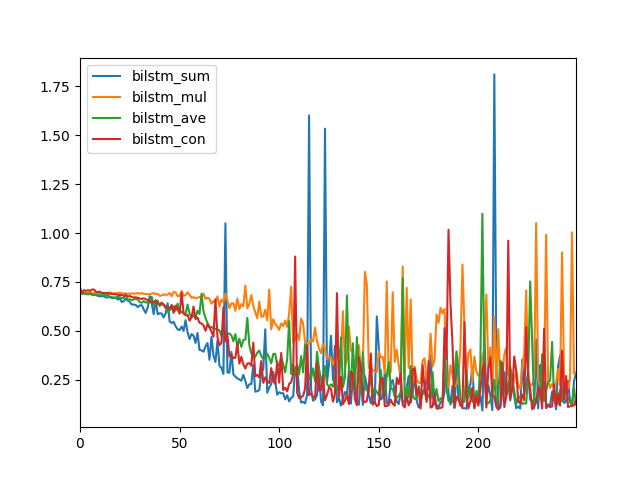
线性图比较双向LSTM的合并模式
概要
在本教程中,您发现了如何使用Keras在Python中开发用于序列分类的双向LSTM。
具体来说,你学到了:
- 如何开发一个设计的序列分类问题。
- 如何开发LSTM和双向LSTM进行序列分类。
- 如何比较双向LSTM的序列分类的合并模式。
注:此文作者为Jason Brownlee,原网址:https://startupsventurecapital.com/essential-cheat-sheets-for-machine-learning-and-deep-learning-researchers-efb6a8ebd2e5

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消