


















赫尔辛基大学AI基础教程:机器学习的类型(4.1节)
手写数字是讨论我们为什么使用机器学习时经常使用的经典案例,我们也以此为例。
下面你可以看到来自常用MNIST数据集的手写图像示例:
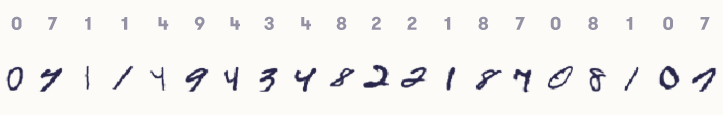
每张图片上方都会显示正确的标签(本应写入的数字)。请注意,某些“正确的”类标签是存疑的:例如,请参阅左侧的第二个图像:那是7还是4?
注意
MNIST是什么?
几乎每个学机器学习的人都知道MNIST数据集。但很少有人知道什么是首字母缩写词代表什么。事实上,M代表Modified,而NIST代表National Institute of Standards and Technology。现在你知道了通常机器学习专家都不知道的东西!
在普通的机器学习问题中,一次只有一个类别的值是正确的。MNIST案例也是如此,但正如我们所说,正确的答案往往很难说清楚。在这类问题中,一个实例不可能同时属于多个类(或者根本不属于任何类)。我们想要实现的是一种AI方法,可以像上面那样为给定的图像自动分类正确的标签(0到9之间的数字)。
注意
为何不用编程方法解决问题
原则上,自动数字识别器可以通过编写如下规则来手动构建:
- 如果黑色像素大部分以单个环状的形式存在,则标签为0
- 如果黑色像素形成两个相交的环,则标签为8
- 如果黑色像素大部分集中在图中间的垂直直线上,则标签为1
等等......
这就是人工智能方法在20世纪80年代的主要发展方式(它被称为“专家系统”)。但是,即使对于数字识别这样一个简单的任务来说,编写这些规则的任务也是非常费力的。事实上,上面示例的规则不够具体,无法通过编程实现 - 我们必须精确地定义“大部分”,“环”,“直线”,“中间”等等的含义。
即使我们完成了所有这些工作,其结果可能会是一个不好的AI方法,因为正如你所看到的,手写数字通常很像,每个规则都需要十几条例外。
三种类型的机器学习
机器学习发源于统计学,也可以被认为是从数据中提取知识的技术。特别是线性回归和贝叶斯统计等,它们都已经有两个多世纪的历史了!而这些方法甚至直到今天都是机器学习的核心。有关更多示例和简要历史记录,请参阅维基百科(https://en.wikipedia.org/wiki/Timeline_of_machine_learning)。
机器学习领域常常分成不同的领域以攻克不同的问题。大致分类如下:
监督式学习:给我们一个输入,例如一张带有交通标志的照片,任务是预测正确的输出或标签,例如图片中是哪个交通标志(限速,停车标志......) 。在最简单的情况下,答案为判断对或不对。(我们称这些二元分类问题。)
无监督学习:没有标签或正确的输出。其任务是发现数据的结构:例如,将相似的项目分组以形成“簇”,或将数据降维到少数重要的“维度”。数据可视化也可以被认为是无监督学习。
强化学习:通常用于像自动驾驶汽车这样的AI智能体必须在环境中运行,并且关于好的或坏的选择的反馈是有延迟的。也可用于仅在游戏结束时才能确定结果的游戏中。
这些类别有些重叠和模糊,所以某种特定的方法有时很难放在一个类别中。例如,半监督学习一部分监督学习,一部分是无监督学习。
注:
分类
谈到机器学习,我们主要关注监督学习,特别是分类任务。在分类中,我们观察输入,如交通标志的照片,并试图推断其“类”,如标志的类型(限速80公里/小时,人行横道,停车标志等) 。分类任务的其他例子包括:识别假Twitter账户(输入包括关注者列表,以及他们开始关注账户的速度,类是假的或真实的账户)和手写数字识别(输入是图像,类是0,...,9)。

人教机器:监督学习
代替手动写下确切的规则完成分类,监督机器学习的重点是使用大量实例,用正确的标签标记每个实例,并用它们“训练”AI方法为训练实例和任何其他图像自动识别正确的标签。这当然要求提供正确的标签,这就是我们称它为监督学习的原因。提供正确标签的用户是指导学习算法朝向正确答案的监督者,最终该算法可以独立地分类正确答案。
除了学习如何在分类问题中预测正确的标签外,监督式学习还可用于预测结果为数字的情况。例如,根据广告内容和用户之前的在线行为数据预测将点击Google广告的人数,根据道路状况和速度限制预测交通事故的数量,或根据房子位置、大小和条件预测房子的售价。这些问题被称为回归。你可能知道线性回归这个术语,它是一种经典的,仍然非常流行的回归技术。
注:
例
假设我们有一套由公寓销售数据组成的数据集。对于每一笔购买,我们显然会得到支付的价格,以及公寓多少平方米(或平方英尺,如果你喜欢的话),卧室数量,建筑年份,条件(从脏乱到崭新)。然后,我们可以使用机器学习来训练一个基于这些特征预测销售价格的回归模型。(示例:http://kannattaakokauppa.fi/#/en/)
警告:小心使用该机器学习算法
我们想让你了解一些潜在的错误。它们与这样一个事实有关,除非你对使用机器学习方法的方式非常小心,否则你可能对预测的准确性过于自信,而当预测的准确性被证明比预期的更糟糕时,你可能会非常失望。
为避免重大错误,首先你要将数据集分为两部分:训练数据和测试数据。我们首先仅使用训练数据来训练算法。这使我们得到一个基于输入变量预测输出的模型或规则。
要评估我们实际预测输出的能力,我们不能依赖训练数据。虽然模型可能在训练数据中做出非常好的预测,但它不能证明它可以推广到其他数据。这时测试数据就派上用场了:我们可以使用训练好的模型来预测测试数据的输出,并将预测与实际输出(例如未来公寓售价)进行比较。
注意
太过适应数据,警惕过拟合
一定要记住,机器学习学习的预测器的准确性在训练数据和分离的测试数据中可能是完全不同的。这就是所谓的过拟合现象,许多机器学习研究都是为了避免这种现象的发生。直觉上,过度拟合意味着过度“聪明”。当预测一位已知艺术家的新歌成功时,你可以查看艺术家早期歌曲的纪录,并提出一条规则,例如“如果歌曲是关于爱情的,并且包含一个朗朗上口的合唱,它将会进入前20“。然而,也许有两首带有吸引人的合唱的情歌并没有进入前20,所以你决定延伸这个规则“......除非提及瑞典或瑜伽”来改善你的规则。这可能会使你的规则完美地拟合过去的数据,但事实上它可能会使预测未来的测试数据变得更糟。
机器学习方法特别容易出现过度拟合,因为他们可以尝试大量不同的“规则”,直到找到完全符合训练数据的规则。特别是那些非常灵活并且能够适应数据中几乎任何模式的方法,除非数据量很大,否则它们可能会过度适合。例如,与通过线性回归获得的受限的线性模型相比,神经网络在产生可靠的预测之前可能需要大量的数据。
学习避免过拟合并选择一个不太受制,也不过于灵活的模型数据科学家最基本的技能之一。
没有老师的学习:无监督学习
上面我们讨论了有监督学习,在有正确答案的情况下,而机器学习算法的要点是找到一个能够根据输入数据预测正确答案的模型。
在无人监督的学习中,没有提供正确的答案。这使得情况大不相同,因为我们无法通过使模型适合训练数据的正确答案来构建模型。并且由于我们无法检查学习的模型是否做得好,也使得对性能的评估更加复杂。
典型的无监督学习方法试图学习数据背后的某种结构。例如,在可视化中,相似的项目被放置在彼此附近,而不同的项目则被放置的离彼此更远。它也可以意味着集群化我们使用数据的地方,以识别彼此相似但与其他集群中的数据不相似的项目组或“集群”。它还可以指聚类,我们使用这些数据来识别彼此相似但与其他集群中的数据不同的项的组或簇。
注:
举例:
杂货连锁店收集关于顾客购物行为的数据(所以你会有很多会员卡)。为了更好地了解他们的顾客,商店可以使用图形将数据可视化,其中每个顾客用点表示,并且倾向于购买相同产品的顾客放置得比购买不同产品的顾客更近。这样,商店可以应用聚类来获得“低预算健康食品爱好者”,“高档鱼爱好者”,“每周6天喝汽水吃披萨”等等的顾客组。注意,机器学习方法只会将客户分组成簇,但它不会自动生成簇的标签。这项任务需要人做。
无监督学习的另一个例子可以被称为生成模型。这已经成为近几年来的一个突出的方法,因为称为生成式对抗网络(GAN)的深度学习技术已经取得了巨大的进步。例如,给定一些数据,例如人脸照片,生成模型可以生成的更像:更真实的伪造人脸图像。
后期我们将介绍GAN,并解释能够生成高质量人造图像内容的影响,但接下来我们将仔细研究监督学习,并更详细地讨论一些具体方法。
练习12:一个单词的垃圾邮件过滤器
答案:5.1
练习13:完整的垃圾邮件过滤器
答案:65.1168
赫尔辛基大学AI基础教程合集:赫尔辛基大学AI基础教程









