


















赫尔辛基大学AI基础教程:最近邻分类(4.2节)
赫尔辛基大学AI基础教程是赫尔辛基大学面向全世界人工智能学习爱好者的免费人工智能教程。
赫尔辛基大学AI基础教程合集:赫尔辛基大学AI基础教程
本节讲解的是,最近邻分类是最简单的分类方法之一。当对给定项分类时,它会找到与这个项最相似的训练数据项,并输出其标签。下面的图给出了一个示例。
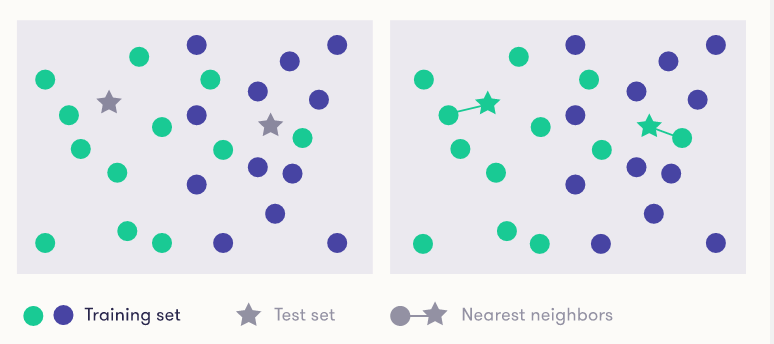
在上图中,我们展示了一组训练数据项,其中一部分属于一个类(绿色),另一部分属于另一个类(蓝色)。此外,还有两个测试数据项(星星),我们将使用最近邻方法进行分类。
两个测试项目都归类为“绿色”类,因为他们最近邻的都是绿色的(参见上面的图(b))。
图中点的位置以某种方式表示项的属性。由于我们在二维平面上绘制图表 - 你可以沿两个独立的方向移动:上下或左右 - 这些项目有两个属性,我们可以将其用于比较。想象一下,例如在一家诊所代表病人的年龄和血糖水平。但是上面的图应该只是作为一个可视化工具来说明总体思想,即将类别值与相似性或邻近性(邻近度)联系起来。这种方法决不局限于两个维度,最近邻分类可以很容易地应用于更多属性的项。
我们“最近”的意思是什么?
一个有趣的问题涉及(除其他之外)最近邻分类器是实例之间距离或者说相似度的定义。在上图中,我们默认使用标准几何距离,技术上称为欧几里得距离。这只是表示如果点在一张纸上绘制(或显示在屏幕上),则可以通过测量长度来测量任意两个项之间的距离。
注意
定义'最近'
使用几何距离来确定哪一个是最近的项目可能并不总是合理的,甚至可能:例如,输入的类型可以是文本,我们不清楚如何用几何表示的方式画出项也不知道如何测量距离。因此,你应该根据具体情况选择距离度量标准。
在MNIST数字识别的案例中,测量图像相似性的一种常见方式是计算每个像素的匹配。换句话说,我们将每幅图像左上角的像素相互比较,如果它们的颜色越接近(灰色阴影),则两幅图像越相似。然后,我们还会比较每个图像右下角的像素以及中间的所有像素。这种技术对移动或缩放图像非常敏感:如果我们拍摄'1'图像,并将1向左或向右稍稍移动,则结果是两幅图像非常不同,因为黑色像素在两幅图像中位于不同的位置。幸运的是,MNIST数据已经通过图像居中进行了预处理,减轻了这个问题。

使用最近邻来预测用户行为
最近邻方法的应用的经典示例是预测AI应用中的用户行为(例如推荐系统)。
这个想法是使用非常简单的原则,即过去行为相似的用户将来也会有类似的行为。设想一个收集用户聆听行为数据的音乐推荐系统。假设你听过20世纪80年代的迪斯科音乐。有一天,服务提供商得到了一个很难找到的1980年迪斯科经典,并将它添加到音乐库中。系统现在需要预测你是否喜欢它。这样做的一种方式是使用由服务提供商的输入的关于流派,艺术家和其他元数据的信息。但是,这些信息相对稀缺和粗糙,只能给出粗略的预测。
然而目前推荐系统使用的不是手动输入元数据,而是协同过滤。所谓协同,它使用其他用户的数据来预测你的偏好。“过滤”一词指的是只有通过过滤器的内容才会推荐给你:你可能喜欢的内容会被通过,其他内容不会。(这种过滤器可能会导致所谓的过滤器泡沫(filter bubbles))
现在让我们说,其他已经听过80年代迪斯科音乐的用户喜欢这个新发布的歌,并且不断地听它。系统将识别你和其他80年代的迪斯科狂热者的有相似的过去行为,并且由于像你这种的用户喜欢新发布的歌,系统也会预测你本人也喜欢。因此它会显示在你的推荐列表的顶部。如果事实是没人喜欢新发布的歌,也许新发布的歌曲不是那么好,其他与你过去的行为相似的用户并不喜欢它。在这种情况下,系统不会向你推荐它,或者至少不会让它显示在你推荐列表的顶部。
以下练习进一步阐释这种思路。
练习14:购买同类产品的客户
在这个练习中,我们将为在线购物应用程序构建一个简单的推荐系统,用户的购买历史记录将被用于预测用户可能购买下一个产品。
我们有来自六位用户的数据。我们记录了他们最近购买的四件商品的历史记录以及购买这四件商品后购买的商品:
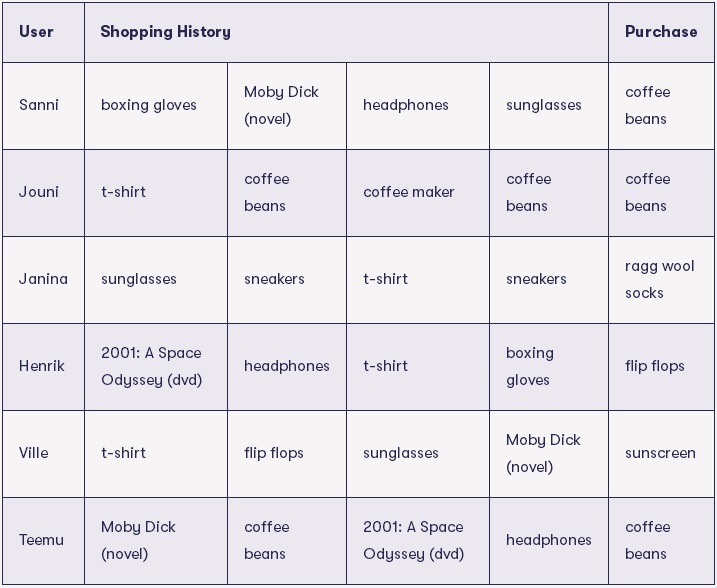
最近的一次购买是最右边一列,例如,在购买了t-shirt、flip flops、sunglasses和Moby Dick (小说)后,Ville购买了sunscreen。我们假设,在购买类似物品后,其他用户也可能购买sunscreen。
要应用最近邻的方法,我们需要定义最近邻的含义。这可以通过许多不同的方式实现(当然有好有坏)。我们使用购物历史记录通过计算两个用户已购买了多少物品来计算的相似性。
例如,Ville和Henrik的用户都购买了T恤,因此它们的相似性为1。注意,flip flops不被计算在内,因为在计算它们之间的相似之处时,我们不包括最近一次购买,它有其他用途。
我们的任务是预测买了以下产品的顾客Travis的下次购买:

您可以将Travis视为我们的测试数据,上面的6个用户构成了我们的训练数据。
按以下步骤进行:
- 计算Travis相对于训练数据中6个用户的相似度(通过将用户的类似购买数量加起来完成)。
- 计算了相似度后,通过选择计算出的相似度中的最大值来识别与Travis最相似的用户。
- 通过查看上一步中最相似用户的最新购买情况(表格中最右边的一列),预测Travis可能购买的下一个产品。
谁是与Travis最相似的用户?
特拉维斯预计购买什么?

在上面的例子中,我们只有六个用户的数据,我们的预测可能非常不可靠。但是,网上购物网站通常有数百万用户,他们产生的数据量非常大。在很多情况下,有一大堆用户的过去行为与你的行为非常相似,并且其购买历史可以很好地反应了你的兴趣。
这些预测也可以是自我实现预言,因为如果系统向你推荐一种产品,那么你更有可能购买它,这就使得评估它们的实际效果变得很棘手。同样的推荐系统也被用于向用户推荐音乐,电影,新闻和社交媒体内容。而在新闻和社交媒体的背景下,由这些系统产生的过滤可能导致过滤泡沫。
练习15:过滤泡沫
如上所述,推荐用户可能点击或喜欢的社交媒体新闻内容可能导致过滤泡沫,用户仅看到符合他们自己的价值观和观点的内容。
- 你认为过滤器泡沫有害吗?毕竟,它们是通过推荐用户喜欢的内容而创建的。如果有的话,会有哪些负面后果与过滤器泡沫有关?请随意从其他来源寻找更多信息。
- 你是否可以想办法避免过滤泡沫,同时还能够根据个人喜好推荐内容?尝试提出至少一个建议。你可以从其他渠道寻找创意,但我们也希望看到你自己的想法!









