


















赫尔辛基大学AI基础教程:回归(4.3节)
我们在本节中的主要学习目标是监督学习方法的另一个很好的例子,它也和最近邻分类一样简单:线性回归。以及它的近亲逻辑回归。
注:
分类和回归之间的区别
我们应该在不同情景下产生的那种预测有一个虽然小但很重要的差异。例如,最近邻分类为给定的选项集(如垃圾邮件/合法邮件,或0,1,2,...,9)中的任何项选择一个类标签,线性回归产生的数字预测不会被限制为整数。所以线性回归更适用于输出变量可以是任何数字的情况,例如产品的价格,到障碍物的距离,下一部星球大战电影的票房收入等等。
线性回归的基本思想是将每个特征变量的影响相加以产生预测值。相加过程的技术术语是线性组合。这个想法非常简单,可以通过购物账单来说明。
注:
将线性回归看作购物账单
假设你去杂货店购买2.5公斤土豆,1.0公斤胡萝卜和两瓶牛奶。如果土豆的价格是每公斤2欧元,胡萝卜的价格是每公斤4欧元,一瓶牛奶是3欧元,那么由收银员计算的账单总计为2.5×2欧元+ 1.0欧元×4欧元+ 2×3欧元= 15欧元。在线性回归中,土豆,胡萝卜和牛奶的数量是数据的输入。输出是您购物价格,它显然取决于你购买的每种产品的价格和数量。
线性这个词意味着当一个输入特征增加某个固定量时输出的增加总是相同的。换句话说,无论何时向购物篮中加入两公斤胡萝卜,账单都会增加8欧元。当你再增加两公斤时,账单又增加8欧元,如果你增加一般,1千克,那么账单也增加一半,即4欧元。
关键术语
系数或权重
在线性回归术语中,表示不同物品的价格将被称为系数或权重。(不要和土豆萝卜的重量混淆!)线性回归的主要优点之一是易于解释:学到的权重实际上可能比输出的预测更值得关注。
例如,当我们使用线性回归来预测预期寿命时,吸烟(每天的吸烟数)的权重大约为减寿半年,这意味着每天多吸一根香烟的平均减寿大约为半年。同样,蔬菜摄入的重量(每天一把蔬菜)的权重是增寿一年,所以每天吃一把蔬菜,平均增寿一年。
练习16:线性回归
假设进行了大量研究发现在一个特定的国家,不吃任何蔬菜也不吸烟女性的预计寿命(平均寿命)为80岁。进一步假设,平均而言,男人的寿命少5年。还有上面提到的数字:每天吸一根烟会使人的寿命减少半年,每天吃一把蔬菜会使人的寿命增加一年。
计算下列示例的预期寿命:
例如,第一个病例是男性(减5年),每天抽8支香烟(减8×0.5 = 4年),每天吃2把蔬菜(加2×1 = 2年),所以预计寿命是73年。
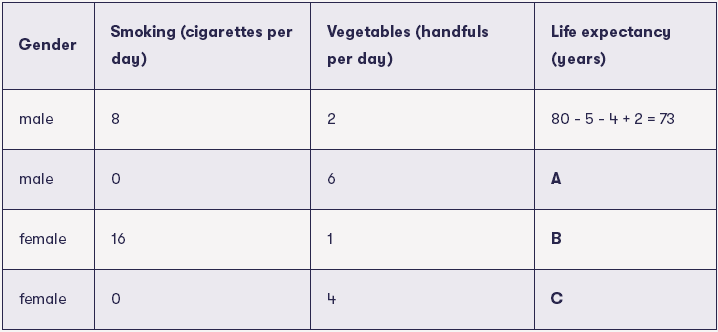
你的任务:计算A,B和C的值.
在上述练习中,不吸烟、厌恶素食的女性80岁的预期寿命是计算的起点。起点的技术术语是截距(intercept)。当我们讨论如何从数据中学习线性回归模型时,我们将回到下面的例子。
学习线性回归
以上,我们讨论了当权重和输入特征都已知时,线性回归如何获得预测。也就是说我们得到输入和权重,我们就可以产生预测的输出。
当我们给出一些项的输入和输出时,我们就可以找到权重,使得预测的输出尽可能与实际输出相匹配。这就是机器学习解决的问题。
注:
例
继续购物比喻,假设我们已知许多购物篮里装的都有什么商品并已知每个购物篮商品的总价格,然后要求我们弄清楚每种商品(土豆,胡萝卜等)的价格。一个篮子里,比如说有1公斤牛腰牛排,2公斤胡萝卜和一瓶基安蒂,即使我们知道总费用是35欧元,我们也无法确定价格,因为有很多种价格的组合可以产生相同的总价。但,有了很多篮子,我们通常就能解决这个问题。
但是,问题变得更加困难,因为在现实世界中,实际输出并不总是完全由输入决定,因为各种因素会在过程中引入不确定性或者说“噪声”。你可以想象在集市上购物,那里的任何一种产品的价格都可能随时发生变化,或者在餐馆最终价格要包括不同金额的小费。在这种情况下,我们可以估算价格,但精度有限。
找到优化训练数据中预测和实际输出之间匹配的权重是一个可以追溯到19世纪的经典统计问题,甚至对于海量数据集它也可以轻松解决。
我们不会详细讨论实际寻找权重的算法,比如经典的最小二乘法(尽管这些算法很简单)。但是,你可以在下面的练习中感受到数据趋势。
可视化线性回归
了解线性回归可以告诉我们的一个好方法是绘制一张包含我们的数据和我们的回归结果的图。一个简单例子:我们的数据集的变量是,每天员工喝咖啡的杯数,而该员工每天所写的代码行数作为输出。这不是一个真实的数据集,因为很明显,除了咖啡以外,还有其他因素对员工的工作效率产生影响,这些因素以复杂的方式相互作用。通过增加咖啡量来提高生产力也只能保持在一定程度上,在此之后会过于激动使人分心。
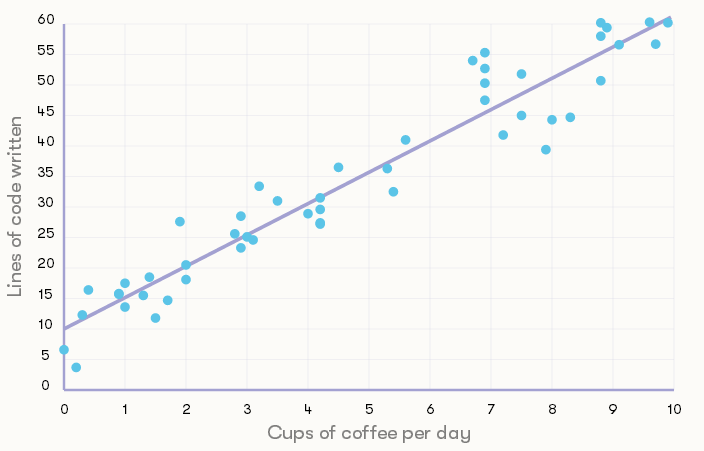
上面的图表中将每个点表示一名员工,我们可以看到,显然大趋势是喝更多的咖啡会写更多代码。(不要当真,这是虚构的数据。)从这个数据集中,我们可以了解与咖啡消费相关的系数或权重,并且我们可以已经说过它似乎接近5,因为每喝一杯咖啡消耗的代码行数大约要增加五。例如,对于每天喝大约两杯咖啡的员工,他们每天写大约15行代码,而喝四杯咖啡,则大约写25行。
还可以注意到,根本不喝咖啡的员工也会写代码,图中显示,他们大约写十行代码。这个数字是我们前面提到的术语,截距。截距是模型中的另一个参数,就像权重一样,可以从数据中学习。就像预期寿命的例子一样,它可以被认为是在我们添加了输入变量的之前的计算的起点,无论我们有多少个变量。
图中的线表示我们的预测结果,我们通过使用最小二乘的线性回归技术来估计截距和系数。这条线可用于预测当输入是咖啡杯的数量时产生的代码行数。请注意,允许输入非整数的杯数(如半杯,四分之一杯等),我们同样可以获得预测结果。
练习17:预期寿命和教育(第1部分)
让我们研究一下在学校度过的年数(包括学前教育和大学之间的一切)和预期寿命之间的关系。下面是三个国家的数据点:
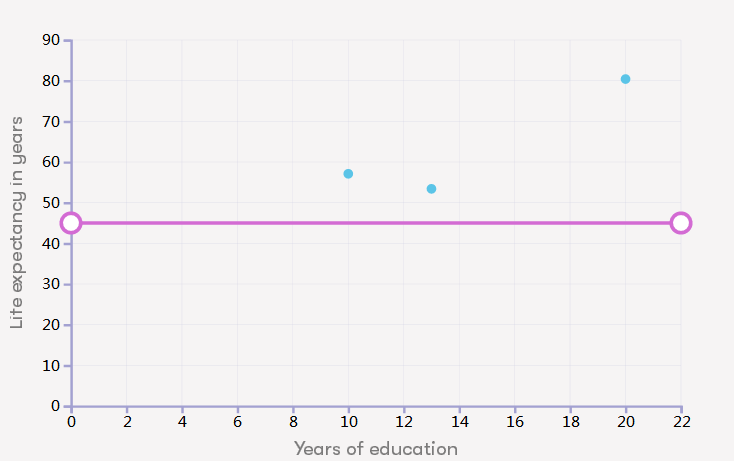
一个国家的平均在校年数是10,预期寿命是57,第二个国家的平均在校年数是13岁,预期寿命是53岁,第三个国家的平均在校年数是20,预期寿命是80。
通过拖动实线的端点,使其按照数据点的趋势来定位这条线(我们这里是图片,所以你只能想象了)。请注意,你无法使这条线与数据点完全匹配,而且这样做是是可以的:一些数据点会位于线的上方,一些点位于线的下方。最重要的是这条线描述了整体趋势。在定位线后,你可以使用它来预测预期寿命。
根据这些数据,假设受过15年教育,你可以得出什么结论?
A.正好64年
B.肯定在60到70年之间
C.一定少于70年
D.可能不到90年
练习18:预期寿命和教育(第2部分)
在上个的练习中,我们只有三个国家的数据。完整的数据集由来自14个不同国家的数据组成,如图所示:
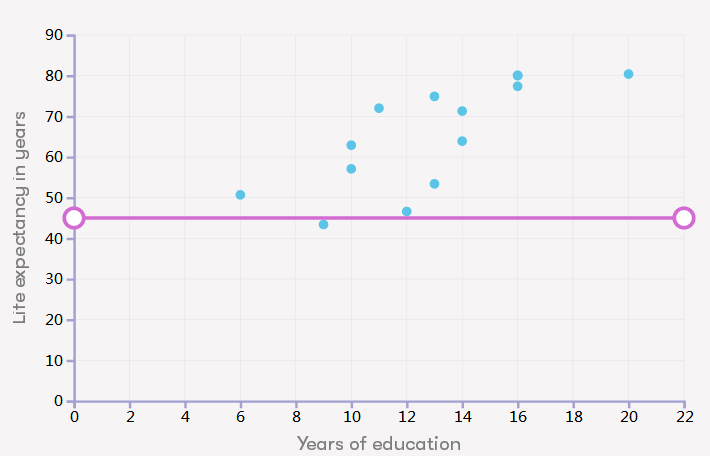
根据这些数据,你的预测是否会改变?如果会,为什么?
以下哪一种选择最符合您对15年教育人群预期寿命的估计?
A.45至50年
B.60至80年
C.69至71年
D.30至100年
应该指出的是,像上述练习中使用的那些研究不能确定因果关系。换句话说,仅从这些数据来看,我们无法判断学习是否真的通过更明智、更健康的生活方式或其他机制提高了预期寿命,或者预期寿命与教育之间的明显联系,应该归因于影响两者的潜在因素。例如,在人们接受高等教育的国家,营养,健康护理和安全性可能会更好,从而提高预期寿命。通过这种简单的分析,我们只能识别关联,当然这对预测仍然有用。
线性回归在机器学习中的应用
线性回归确实是许多AI和数据科学应用的主力。它有它的局限性,但它们的简单性、可解释性和效率可以补偿这一点。线性回归已成功用于以下问题:
- 预测在线广告的点击率
- 产品零售需求预测
- 预测好莱坞电影的票房收入
- 软件成本预测
- 保险费用预测
- 预测犯罪率
- 预测房地产价格
我们可以使用回归来预测标签吗?
正如我们上面所讨论的,线性回归和最近邻方法产生了不同类型的预测。线性回归输出数字输出,而最近邻方法从固定的一组类中产生标签。
线性回归优于近邻的地方是可解释性。为什么?你可以说,最近邻法和它产生的任何单一预测都很容易解释:它只是最近的训练数据元素!这是对的,但是当涉及到学习模型的可解释性时,有一个明显的区别。以与线性回归中的权重类似的方式解释最近邻中的训练模型是不可能的:学习模型基本上是整个数据,并且而且它通常太大太复杂,无法为我们提供足够的洞察力。如果我们想要一个方法来产生与最近邻居标签相同的输出,但是像线性回归一样可以解释呢?
逻辑回归
这样的方法是有的,因为:我们可以将线性回归方法的输出转化为对标签的预测。这种做法被称为逻辑回归。我们不会深入介绍技术细节,只要说最简单的情况下,我们从线性回归中得到输出,这是一个数字,如果标签大于零,则预测为标签A,如果标签小于或等于零,则预测另一个标签B。实际上,逻辑回归不仅可以是预测类,还可以预测不确定性。比如,如果我们预测客户今年是否会购买新智能手机,我们可以预测客户A,90%的概率购买手机,比如对于另一个不太好预测的客户,我们可以预测他们55%概率不会 买(换句话说,45%的概率买)。
也可以使用相同的技术来获得对两个以上可能标签的预测,因此,不是只可以预测“是”或“否”(买不买新电话或真新闻还是假新闻等),而是使用逻辑回归来识别例如,手写的数字,在这种情况下,有十个可能的标签。
逻辑回归的一个例子
我们假设我们收集学生参加烹饪介绍性课程的数据。除了诸如学生证,姓名等基本信息之外,我们还要求学生报告他们为考试学习了多少小时(你为了烹饪考试而学习,所以要报告做菜时间?),并且希望他们在报告中诚实一些。考试结束后,我们会知道每个学生是否通过该课程。部分数据点如下所示:
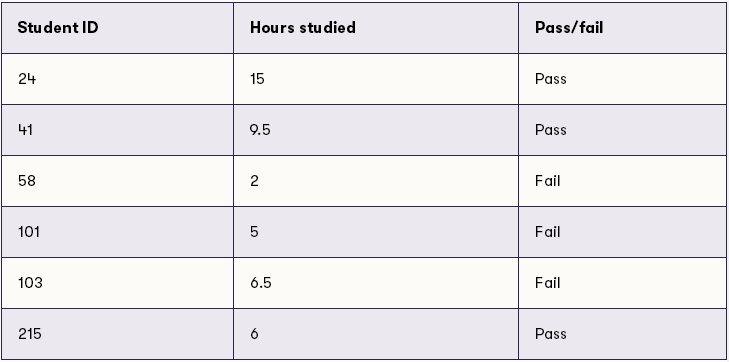
根据表格,你能在学习和通过考试的时间之间得出什么样的结论?我们可以认为,如果我们有来自数百名学生的数据,也许我们就可以看出为了通过课程需要学习的时间。我们可以在图中展示这些数据,如下:
练习19:逻辑回归
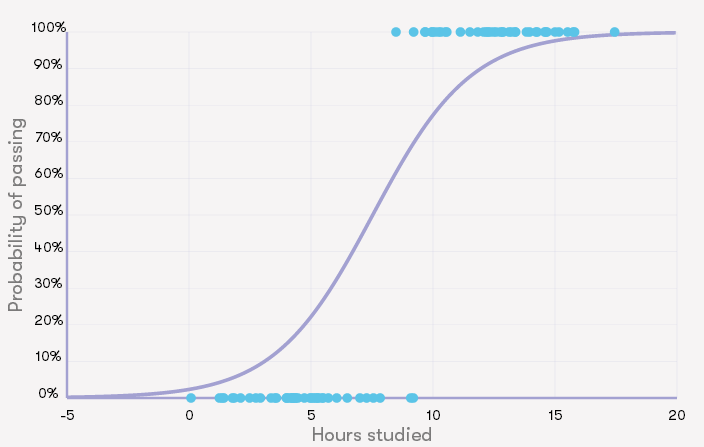
图上的每个点对应一名学生。图的底部刻度是学生为考试学习多少小时,通过考试的学生在图顶部显示,而没通过的显示在底部。我们将使用左侧刻度来表示预测的通过概率(我们从下面解释的逻辑回归模型中得到它)。根据这个数字,你可以大致地看到,学习时间较长的学生通过这门课的机会较大。特别是极端的地方非常直观:准备不足一个小时很难通过课程,但如果准备了非常长的时间,则大部分都会通过。但那些花时间在它们之间的某处呢?如果你学习6个小时,你通过考试的几率是多少?
我们可以用逻辑回归来量化通过的概率。图中的曲线可以解释为通过的概率:例如,在学习五个小时后,通过概率略高于20%。它类似于我们在线性回归中学习权重的方法,在这里我们不做详细讨论。
根据上图,如果你想有80%的机会通过考试,你应该学习几个小时?
A.6-7小时
B.7-8小时
C.8-9小时
D.10-11小时
逻辑回归也用于各种现实世界的AI应用,如预测金融风险,医学研究等。然而,像线性回归一样,它也受到线性性质的限制,我们还需要其他许多方法。当我们下节讨论神经网络时,我们将回到线性问题。
机器学习的局限性
总而言之,机器学习是构建AI应用程序的一个非常强大的工具。除了最近邻法,线性回归法和逻辑回归法之外,还有成百上千种不同的机器学习技术,但它们都可归结为同一件事:试图从数据中提取模式和依赖关系并使用它们来理解现象,或者预测未来的结果。
机器学习可能是一个非常棘手的问题,我们通常无法实现一种始终会生成正确标签的完美方法。然而,在大多数情况下,一个好的但不是完美的预测总比没有好。有时我们可以自己做出更好的预测,但我们可能仍然更喜欢使用机器学习,因为机器会更快地做出预测,并且可以持续做出预测,不会感到疲劳。很好的例子就是推荐系统,它需要预测你更感兴趣的音乐、视频或广告。
影响我们可以取得的好成果的因素包括:
- 任务的难度:在手写数字识别中,如果数字写得非常潦草,即使是人也无法总是正确地猜出的意图
- 机器学习方法:有些方法比其他方法更适合于一些特定的任务
- 训练数据量:如果只有几个实例,就不可能获得一个好的分类器
- 数据质量
注:
数据质量很重要
在本章开始时,我们强调了拥有足够数据和过度拟合风险的重要性。另一个同样重要的因素是数据的质量。为了建立一个对训练数据以外的数据进行泛化的模型,训练数据需要包含足够的与手头问题相关的信息。例如,如果你创建了一个图像分类器,它可以告诉你为算法提供的图像是什么,并且你只给了狗和猫的图片进行训练,它会将所看到的所有内容识别为狗或猫。如果算法只在只看到猫和狗的环境中使用,这是有意义的,但是如果期望它也能看到船、汽车和花,这就没有意义了。
我们未来会回过头来讨论由“有偏见的”数据引起的潜在问题。
强调不同的机器学习方法适用于不同的任务也很重要。因此,对于所有问题没有单一的最佳方法(“即不可能用一个算法来归纳它们......”)。好在,人们可以尝试大量不同的方法,并查看哪一种方法对手头的问题而言最有效果。
这使我们想到了一个非常重要但在实践中经常被忽视的问题:更好地效果意味着什么。在数字识别任务中,好的方法当然是会在大多数时候产生正确的标签。我们可以通过分类错误来度量这一点:分类器输出错误类的百分比。在预测房价时,质量指标通常是预测价格与房子出售的实际价格之间的差。在许多现实应用中,某个方向有偏差可能比另一方向有偏差更糟糕:将价格设得过高可能晚卖出几个月,但将价格设定得太低意味着卖的钱少了。再举一个例子,如果没有发现汽车前面的行人,就会比在没有汽车的情况下错误地检测出一个人的错误要严重得多。
如上所述,我们通常不能实现零误差,但是也许我们会对小于1 / 100(或1%)的误差感到满意。当然,这也取决于应用方向:你不会乐意看到街上只有99%安全度的汽车,但能够预测你是否会以这种精度喜欢一首新歌可能足以让你有愉快的听歌体验了。时刻牢记真正的目标可以帮助我们确保创造真正的附加价值。
练习14:购买同类产品的客户
答案:Ville sunscreen
赫尔辛基大学AI基础教程合集:赫尔辛基大学AI基础教程









