











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






研究人员开发深度学习系统,将球赛视频转换为可在任何地点观看的3D全息图
2018年06月07日 由 浅浅 发表
17257
0

再过几天,世界杯足球赛即将开始,你有没有想过罗纳尔多,梅西或者内马尔在你的餐桌上打比赛会是什么样子?华盛顿大学,Facebook和Google的研究人员开发了第一个端到端的深度学习系统,该系统可以将足球比赛的标准YouTube视频转换为可移动的3D全息图。
“单眼重建足球比赛面临着许多挑战。我们必须估计相机相对于场地的位置,检测并跟踪每个球员,重新构建他们的身体形状和姿势,并进行组合,”研究人员在他们的研究报告中写道。
结果是令人惊叹的,可以在任意地点通过3D查看器或用AR设备观看比赛。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2018/06/Soccer-On-Your-Tabletop.mp4"][/video]
该团队使用NVIDIA GeForce GTX 1080 GPU和NVIDIA TITAN Xp GPU以及cuDNN加速的 PyTorch深度学习框架,训练了卷积神经网络,从几小时的FIFA足球视频中提取球员3D数据。
基于这个视频游戏数据,神经网络能够在场上重建每个玩家的深度图,可以在3D查看器或AR设备上呈现这些深度图。
“事实证明,在玩Electronic Arts FIFA游戏并拦截引擎和GPU之间的调用时,可以从视频游戏帧中提取深度图。特别是,我们使用RenderDoc来拦截游戏引擎和GPU,”该团队表示,“FIFA与大多数游戏类似,在过程中使用延迟着色。通过访问GPU调用,可以捕获每帧的深度和颜色缓冲区。一旦在给定的帧中捕捉到深度和颜色,我们就会用它来提取球员。”
为了验证系统,该团队用YouTube上十个高分辨率职业足球比赛测试了他们的方法。值得注意的是,该系统仅通过合成视频游戏镜头进行训练。而在现实世界的情况下,该系统带来了值得一看的结果。
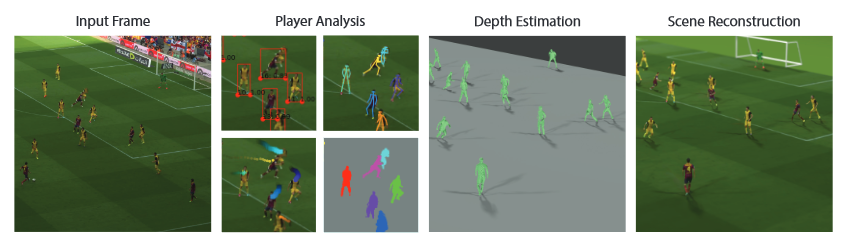
重建方法概述。从YouTube视频框中,我们使用字段线恢复相机参数。然后提取边界框,姿势和轨迹(跨多个帧)来分割球员。使用训练有素的视频游戏数据的深层网络,可以在场中重建每个玩家的深度图,并在3D查看器或AR设备进行渲染。
研究人员下一个项目包括专注训练系统更好地检测球,并开发可从任何角度观察的系统。
这项研究将于6月18日至22日在犹他州盐湖城举行的年度计算机视觉和模式识别(CVPR)大会上亮相。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消