


















赫尔辛基大学AI基础教程:神经网络是如何构建的(5.2节)
注:
权重和输入
基本的人工神经元模型包含一组自适应参数,称为权重,类似于线性和逻辑回归中的权重。并且就像在回归中一样,这些权重被用作神经元输入的乘数,然后相加。权重乘以输入的和称为输入的线性组合。你大概可以回顾一下购物账单的做类比:将每件商品的数量乘以每件商品的价格并加起来得到总价。
如果我们有一个具有六个输入的神经元(类似于六个购物项:土豆,胡萝卜等等),输入1,输入2,输入3,输入4,输入5和输入6,我们还需要六个权重。权重类似于物品的价格。我们称它们为权重1,权重2,权重3,权重4,权重5和权重6。另外,我们通常会像在线性回归中那样包含一个截距项。举个例子,你可以想象你使用信用卡付款的固定附加费用。
然后,我们可以计算这样的线性组合:线性组合=截距+权重1×输入1 + ... +权重6×输入6。
用实际的数字举例,如:
10.0 + 5.4 × 8 + (-10.2) × 5 + (-0.1) × 22 + 101.4 × (-5) + 0.0 × 2 + 12.0 × (-3) = -543.0
练习21:权重和输入与文本输入
C.-3
D.5.4
A.8, 5, 22, -5, 2, -3
B. 5.4, 8, -10.2, 5, -0.1, 22, 101.4, -5, 0.0, 2, 12.0, -3
C. 5.4, -10.2, -0.1, 101.4, 0.0, 12.0
D. 43.2, -51.0, -2.2, -507.0, 0.0, -36.0
为了增加一定量的输出哪一个输入需要改变最少?
A.第一个
B.第二个
C.第三个
D.第四个
当第五个输入增加1时会发生什么?
A.输出不变
B.输出增加1
C.输出增加2
D.其他
正如前面讨论的那样,权重几乎总是通过使用与线性或逻辑回归相同的原理从数据中学习。但在我们更详细地讨论这个之前,我们要介绍神经元在发出输出信号之前完成的另一个重要阶段。
激活和输出
线性组合计算出来后,神经元还要再做一次操作。即,将得到的线性组合通过激活函数。激活函数的典型例子包括:
- 恒等函数:什么也不做,只输出线性组合
- 阶梯函数:如果线性组合的值大于零,则发送一个脉冲(ON),否则不执行任何操作(OFF)
- sigmoid函数:step函数的“软”版本
请注意,第一个激活函数,恒等函数,神经元与线性回归完全相同。这就是为什么恒等函数很少用于神经网络的原因:它不会引起任何新鲜和有趣的东西。
注意
神经元如何激活
真正的生物神经元通过被称为“spikes ”尖锐的电脉冲来进行通信,因此在任何给定的时间,它们发出的信号要么是开,要么是关(1或0)。阶梯函数就是模仿这种行为。人工神经网络倾向于使用第二种激活函数,以便它们始终输出连续的数字激活水平。因此,用一个不太恰当的比喻,真实的神经元通过类似于莫尔斯电码的方式进行通信,而人造神经元就像约德尔唱法那样通过调整其语音的音调来进行通信。

由线性组合和激活函数确定的神经元输出可用于预测或决策。例如,如果网络的设计目的是识别自动驾驶汽车前的停车标志,则输入可以是由安装在汽车前面的摄像头捕获的图像像素,而输出可以用于激活在标志前停车的停车程序。
网络中的学习或适应发生在对权重进行调整以使网络产生正确的输出时,就像线性或逻辑回归一样。许多神经网络非常大,最大的神经网络包含上千亿的权重。优化它们都是一项艰巨的任务,需要大量的计算能力。
练习22:激活和输出
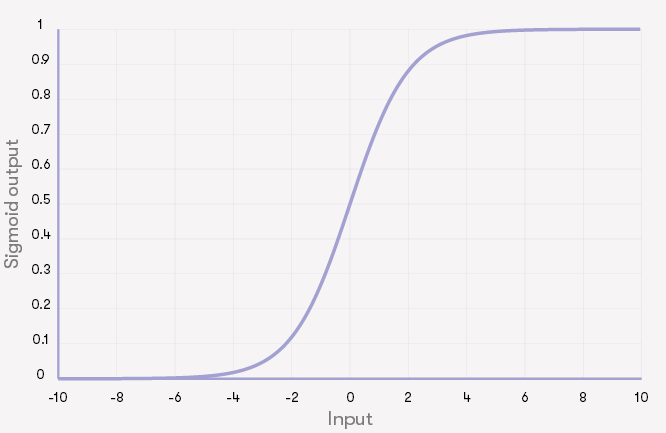
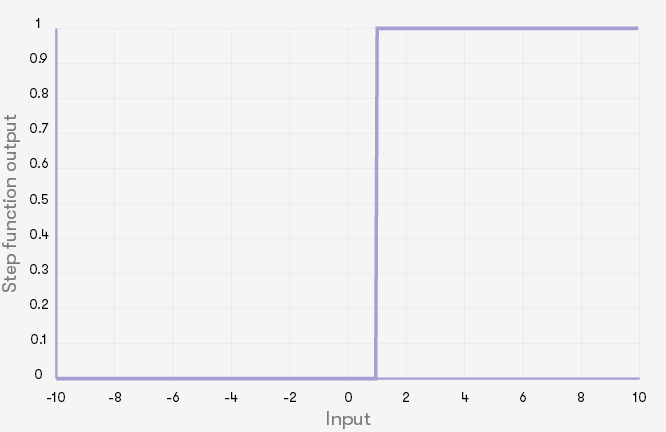
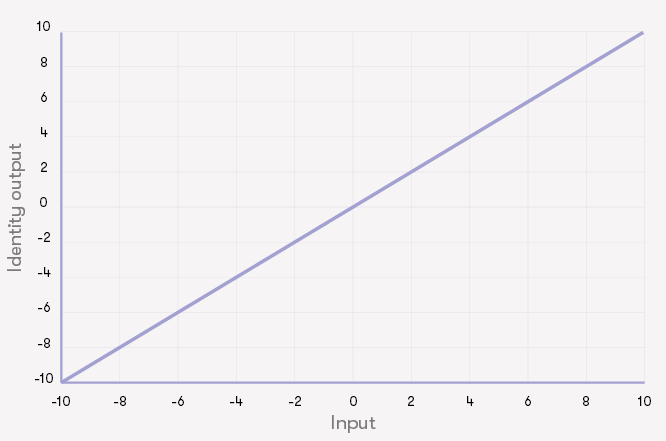
上面描述的哪个激活给出(A.Sigmoid,B.恒等函数,C.阶梯函数):
输入为5时的最大输出?
输入-5的最小输出?
输入为-2.5的最大输出?
所有人工神经网络的起源:感知器
感知器只是带有我们上面介绍的阶梯激活函数的简单的神经元模型的一个花哨的名字。它是最早的神经计算模型之一,并且由于它在神经网络的历史中的重要作用,将其称为“所有人工神经网络的母亲”也不为过。
它可以用作二元分类任务中的简单分类器。1957年,心理学家弗兰克·罗森布拉特(Frank Rosenblatt)介绍了一种从数据中获取感知器权重的方法,叫做感知器算法。在这里,我们不会详细研究感知器算法。你只要知道它就像最近邻分类一样简单就够了。它的基本原理是一次只给网络提供一个训练数据的实例。每次误分类都会更新权重。
注:
AI夸张
在发现感知器算法之后,它受到了很多关注,尤其是因为其发明人弗兰克所做的乐观表述。AI夸张的典型例子是1958年7月8日发表的纽约时报文章:
“海军今天透露了电子计算机的胚胎,预计它将能够走路,谈话,看东西,繁衍并意识到自己的存在“。
请注意神经网络爱好者并不是唯一倾向于乐观的人。基于逻辑的专家系统方法在人工智能方面的兴衰具有人工智能炒作的相同特征,人们声称不久之后就有真正的突破。结果导致了20世纪60年代初和80年代末期的名为AI寒冬的研究经费崩溃。
最终导致在20世纪60年代几乎完全放弃神经网络方法并持续了二十年的辩论历史非常迷人。米克尔·奥拉扎兰(发表在《科学社会研究》1996年)的一篇关于感知器官方争议史的社会学研究,从科学社会学的角度回顾了这一事件(http://journals.sagepub.com/doi/10.1177/030631296026003005)。今天读这本书真是发人深思。阅读关于“已经开发出很快达到人类智能水平并变得自觉的神经网络算法”的著名的AI人的故事,可以与当前炒作中的一些言论相比较。如果你看一下这篇文章,即使你没有阅读全文,它也会为今天的新闻提供一个有趣的背景。以2017年9月发表在《麻省理工学院技术评论》上的一篇文章为例(https://www.technologyreview.com/s/608911/is-ai-riding-a-one-trick-pony/),Jordan Jacobs是一家价值数百万美元的人工智能矢量研究所的联合创始人,他将Geoffrey Hinton(目前深度学习热潮的领军人物)与爱因斯坦相比较,因为他在20世纪80年代对神经网络算法的开发做出了贡献。然后,还要回顾前一节中提到的人类大脑项目。
根据Hinton的说法,“事实上,它不起作用只是一个暂时的烦恼。”(根据文章说,Hinton对上述说法感到好笑,因此很难说他对此有多认真。)人类大脑项目声称,我们对意识的理解有了一个深刻的飞跃。这听起来熟悉吗?
没有人真正了解未来,但知道了早期即将突破的报道记录,建议你多一些批判性思维。我们将在最后一章讲到人工智能的未来,但现在让我们看看人工神经网络是如何构建的。
将神经元连在一起:网络
单个神经元太简单了,无法在大多数实际应用中可靠地进行决策和预测。为了利用神经网络能力,我们可以使用一个神经元的输出作为其他神经元的输入,而这些其他神经元的输出可以是下一个其他神经元的输入,以此类推。整个网络的输出是求得的神经元某个子集的输出,它们被称为输出层。我们将在讨论神经网络如何通过从数据中学习它们的参数来适应产生不同的行为之后再回顾这个问题。
关键术语
层
通常神经网络由层组成。输入层由直接从数据获取输入的神经元组成。因此,例如,在图像识别任务中,输入层将使用输入图像的像素值作为它的输入。神经网络通常还具有隐藏层,即使用其他神经元的输出作为它们的输入,并且将其输出作为其他神经元层的输入。最后,输出层生成整个网络的输出。给定层上的所有神经元都从前一层的神经元获得输入,并将其输出馈送到下一层。
多层网络的经典例子是所谓的多层感知器。如上所述,感知器算法可用于学习感知器的权重。对于多层感知器而言,相应的学习问题会更加困难,并且需要很长时间才能找到可用的解决方案。但最终,人们发明了一种:即反向传播算法,它导致了导致了神经网络在80年代后期的复兴。目前仍然是许多最先进的深度学习解决方案的核心。
注;
同时在赫尔辛基...
导致反向传播算法的路径相当长且曲折。历史上一个有趣的部分与赫尔辛基大学计算机科学系有关。大约在1967年该系成立三年后,一个名叫Seppo Linnainmaa的学生写了一篇硕士论文。这篇论文的主题是“算法的累积舍入误差作为个体舍入误差的泰勒近似”(论文是用芬兰语写的,所以这是对实际标题“Algoritmin kumulatiivinen pyöristysvirhe yksittäisten pyöristysvirheiden Taylor-kehitelmänä”的翻译)。
本文开发的自动微分方法后来被其他研究人员用来量化多层神经网络输出对个体权重的敏感性,这是反向传播的核心思想。
简单的神经网络分类
一个使用神经网络分类的相对简单的例子,我们思考一个与MNIST数字识别任务非常相似的任务,即将图像分为两类。我们将首先创建一个分类器来分类图像是显示一个叉(x)还是一个圈(o)。我们的图像在这里表示为彩色或白色的像素,像素以5×5网格排列。在这种格式下,我们的×和圈(说实话,更像是菱形)看起来如下:
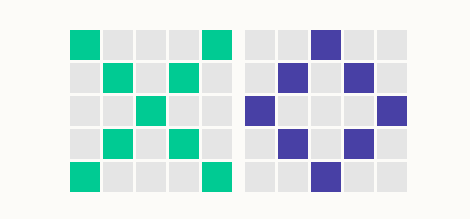
为了建立一个神经网络分类器,我们需要将问题正规化,以使我们能够使用所学的方法来解决它。我们的第一步是用可以用作分类器输入的数值表示像素中的信息。如果正方形着色,我们使用1;如果是无色(或者说白色),则使用0。请注意,尽管上图中符号的颜色不同(绿色和蓝色),但我们的分类器将忽略颜色信息并仅使用彩色或白色信息。图像中的25个像素构成分类器的输入。
为了确保我们知道哪个像素是数字表示中的哪个像素,我们可以决定按照与读取文本相同的顺序列出像素,从左至右读取每行,读取一行后按从上到下的顺序读取下一行。例如,叉的第一行表示为1,0,0,0,1;第二行为0,1,0,1,0,依此类推。叉的全部输入为:1,0,0,0,1,0,1,0,1,0,0,0,1,0,0,0,1,0,1,0,1,0,0,0,1。
我们将使用基本的神经元模型,第一步是计算输入的线性组合。因此需要每个输入像素的权重,这意味着我们总共有25个权重。
最后,我们使用阶梯激活函数。如果线性组合是负值,则神经元激活为零,我们用这个值表示一个叉。如果线性组合是正的,神经元激活是1,我们用它表示圈。
让我们尝试当所有权重都是数值1时发生的情况。使用此设置,我们的叉图像的线性组合为9(9个彩色像素,9个1,和16个白色像素,16个0),对于圈图像是8(8个彩色像素,8个1,和17个白色像素,17个0)。换句话说,线性组合对于两个图像都是正的,因此它们都被分类为圈。虽然只有两幅图像需要分类,但还是效果不佳。
为了改善结果,我们需要调整权重,使得线性组合对于叉为负,对于圈为正。如果我们想区分叉形和圈形的图像,我们可以看到圈形在图像的中心没有彩色像素,而叉形有。同样,图像角落处的像素在叉中着色,但在圈中无色。
我们现在可以调整权重。有很多的权重可以完成这项工作。例如,为中心像素(第13像素)分配权重-1,并将权重1分配给图像四边中点的像素,让所有其他权重为0。现在,对于叉输入,中心像素产生值-1,而对于其他像素,权重的像素值为0,因此-1是总值。激活0,并且叉被正确地分类。
那么这个圈呢?每个边中间像素产生值1,总共4×1 = 4。而其他像素,像素值或权重为零,因此值为4。由于4是正值,所以激活为1,并且圈也被正确识别。
笑脸和哭脸?
现在我们将按照类似的推理来构建笑脸的分类器。你可以通过单击它们为图像中的输入像素分配权重。单击一次将权重设置为1,然后再次单击将其设置为-1。激活1指示图像被分类为笑脸,其可以是正确的或不正确的,而激活-1则将图像分类为哭脸(由于条件限制,请访问原网站点击)。
不要因为你无法正确分类所有的笑脸而感到灰心:事实上,我们简单的分类器根本做不到!这是一个重要的学习目标:有时候不可能实现完美的分类,因为分类器太简单了。在这种情况下,使用输入线性组合的简单神经元对任务来说太简单了。观察如何构建在不同情况下运行良好的分类器:有些分类器可以正确分类大多数快乐的脸部,而对于悲伤的脸部则很糟糕(或者与此相反)。
你可以达到6/8分类笑脸和哭脸吗?
练习20.神经网络的元素
A.细胞体
B.树突(输入)
C.轴突(输出)
D.突触(连接)
赫尔辛基大学AI基础教程合集:赫尔辛基大学AI基础教程









