


















赫尔辛基大学AI基础教程:先进的神经网络技术(5.3节)
在赫尔辛基大学AI基础教程前一节中,我们讨论了大多数神经网络方法的基本思想:多层神经网络,非线性激活函数并学习了反向传播算法。
它们为几乎所有现代神经网络应用提供动力 而它们的很多有趣而有力的变种,导致深度学习许多领域取得了巨大进展。
卷积神经网络(CNN)
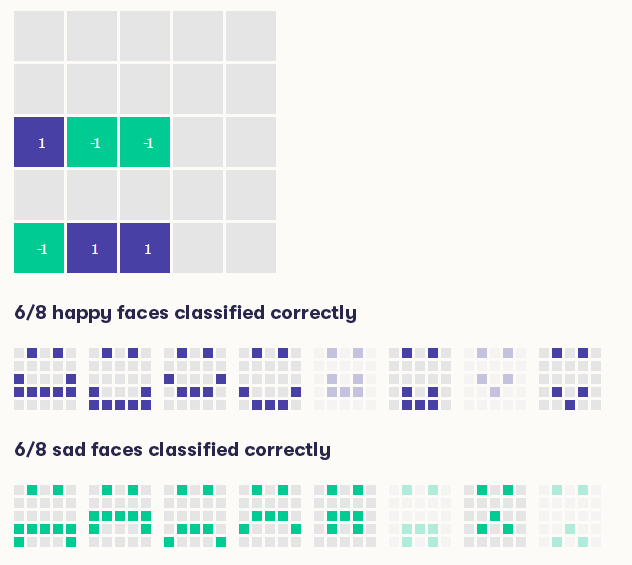
图像处理是深度学习取得惊人成功的一个领域。我们在前一节详细研究的简单分类器能力有限,甚至无法正确分类所有笑脸。通过在网络中增加更多层并使用反向传播来学习权重理论上上可以解决问题,但会出现另一个问题:权重的数量变得非常大,因此达到令人满意的精度所需的训练数据量可能会变得大到不现实。
幸运的是,对于过多权重的问题,有一个非常优雅的解决方案:一种特殊的神经网络,或者更确切地说,是一种可以包含在深度神经网络中的特殊类型的层。这种特殊的层是一个所谓的卷积层。包含卷积层的网络被称为卷积神经网络(CNN)。它们的关键属性是它们可以检测图像特征,如亮或暗(或者特定颜色)斑点,各种方向的边缘,模式等等。这些特征构成了检测更抽象特征的基础,例如猫的耳朵,狗的鼻子,人的眼睛或八角形的停车标志。通常很难训练神经网络来基于输入图像的像素来检测这些特征,因为特征可以以不同尺寸出现在图像中的不同位置和不同上:移动物体或摄像机角度即使物体本身看起来相同,也会显著改变像素值。为了在所有这些不同的条件下学习检测停车标志,将需要大量的训练数据,因为网络只能在训练数据中出现的条件下检测这个标志。所以,例如,只有当训练数据包含图像的右上角有停车标志时,才会检测图像右上角的停车标志。而CNN可以识别图像中任何位置的物体,无论它在训练图像中处在什么位置。
注意
为什么我们需要CNN
CNN使用巧妙的技巧来减少检测不同条件下物体所需的训练数据量。这个技巧基本上相当于为许多神经元使用相同的输入权重 - 因此所有这些神经元都被相同的模式激活 - 但是具有不同的输入像素。例如,我们可以拥有一组被猫的尖耳朵激活的神经元。当输入是猫的照片时,两个神经元被激活,一个用于左耳,另一个用于右耳。我们还可以让神经元从较小或较大的区域中获取输入像素,以便不同的神经元被不同尺度(大小)的耳朵激活,这样即使训练数据仅包含大猫的耳朵,我们也可以检测到小猫的耳朵。
卷积神经元通常放置在网络的底层,处理原始输入像素。基础神经元(如上面讨论的感知神经元)被放置在较高层中,处理底层的输出。底层通常可以使用无监督学习进行训练,不需要考虑特定的预测任务。它们的权重将被调整,以检测输入数据中经常出现的特征。因此,对于动物的照片,典型的特征将是耳朵和鼻子,而在建筑物的图像中,特征是的组成部分,例如墙壁,屋顶,窗户等等。如果将各种对象和场景混合使用作为输入数据,那么底层学到的特征或多或少是通用的。这意味着预训练的卷积层可以在许多不同的图像处理任务中重复使用。这点非常重要的,因为它很容易获得几乎无限量的无标签训练数据(无标签图像)用于训练底层。顶层则是通过有监督的机器学习技术(例如反向传播)进行训练。

神经网络是否梦见电子羊?生成对抗网络(GAN)
从数据中学习的神经网络可以用于预测。由于神经网络的顶层已经以监督的方式进行了训练以执行特定的分类或预测任务,所以顶层只适用于该任务。一个专门训练为检测停车信号的网络对于检测手写数字或猫是没有用的。
通过对训练前的底层进行研究,也就是说研究他们学到的特征是什么样的,我们得到了一个有趣的结果。这项研究可以通过生成激活底层中特定的一组神经元的图像来实现。查看生成的图像,我们可以看到神经网络“认为”某个特征是什么样子,或者具有一组特定特征的图像是什么样的。有些图像甚至像神经网络的“梦”或者“幻觉”(请参阅https://en.wikipedia.org/wiki/DeepDream)。
注意
小心比喻
我们想再次强调比喻的问题,比如在对输入图像进行简单优化时的“做梦”(第一章中讨论的手提箱词)。神经网络并不是真的做梦,它没有像人类理解的那样理解猫的概念。它只是被训练简单地识别物体并生成与输入数据相似的图像。
想要真正生成逼真的猫,人脸或其他物体(你可以用一切物体做输入数据),目前在Google大脑工作的Ian Goodfellow提出了使用两个神经网络的巧妙组合。它的思路是让这两个网络相互竞争。其中一个网络经过训练可生成像训练数据的图像。另一个网络的任务是将第一个网络生成的图像与训练数据中的真实图像分开,它被称为对抗网络,整个系统被称为生成式对抗网络(GAN)。
系统同时训练两个模型。在训练开始时,对抗模型很容易区分训练数据中的真实图像和生成模型的拙劣的尝试。然而,随着生成网络逐渐变得越来越好,对抗模型也被迫改进,循环一直持续到最终生成的图像几乎无法与真实图像进行区分。GAN不仅要在训练数据中再现图像:这是打败对抗网络的最简单的策略。还要被训练生成新的,逼真的图像。

上图是由英伟达公司开发的一种GAN生成,这个项目由由Jaakko Lehtinen教授领导。
你能认出它们是假的吗?
练习21:权重和输入与文本输入
B、A、D、A
练习22:激活和输出
B、B、A
笑脸和哭脸?(仅供参考)
赫尔辛基大学AI基础教程合集:赫尔辛基大学AI基础教程









