











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI:通过无监督学习提高语言理解能力
2018年06月12日 由 浅浅 发表
772645
0

研究者通过一个可扩展的,与任务无关的系统获得了一系列不同语言任务的最新成果,这一系统也即将发布。此方法结合了两种现有的想法:Transformer和无监督的预训练。这些结果说明将监督学习方法与无监督预训练结合很好。
这是许多人探索过的想法,研究者希望这样的结果能激发更多的研究,将这个想法应用到更大、更多样化的数据集上。
系统分两个阶段工作:首先以非监督的方式在大量数据上训练Transformer模型,使用语言建模作为训练信号;然后在更小的监督数据集上对这个模型进行微调,以帮助它解决特定的任务。从根据情绪神经元开发这种方法的工作中,研究者注意到无监督学习技术可以在训练足够的数据时产生出人意料的区分性特征。
以此可以进一步探索:可以开发一个模型,以无监督的方式对大量数据进行训练,然后对模型进行微调以实现许多不同任务的良好性能。我们的研究结果表明,这种方法的效果非常好。相同的核心模型可以针对不同的任务进行微调,而且只需最少量的调整。
这项工作建立在半监督序列学习中介绍的方法上,该方法展示了如何通过使用LSTM的无监督预训练,然后进行有监督的微调来提高文档分类性能。它还扩展了ULMFiT,这项研究显示了如何对单个数据集不可知的LSTM语言模型进行微调,以获得各种文档分类数据集上的最新性能。研究者的工作展示了如何使用基于Transformer的模型来实现超越文档分类的更广泛的任务,如常识推理,语义相似性和阅读理解。它也与ELMo相似,但是更具有任务不可知性,其中包含预训练,但使用任务定制架构,以获得广泛的任务的最新成果。
用很少的调整来实现结果,所有数据集都使用单一的正向语言模型,没有任何集合,大多数报告结果使用完全相同的超参数设置。
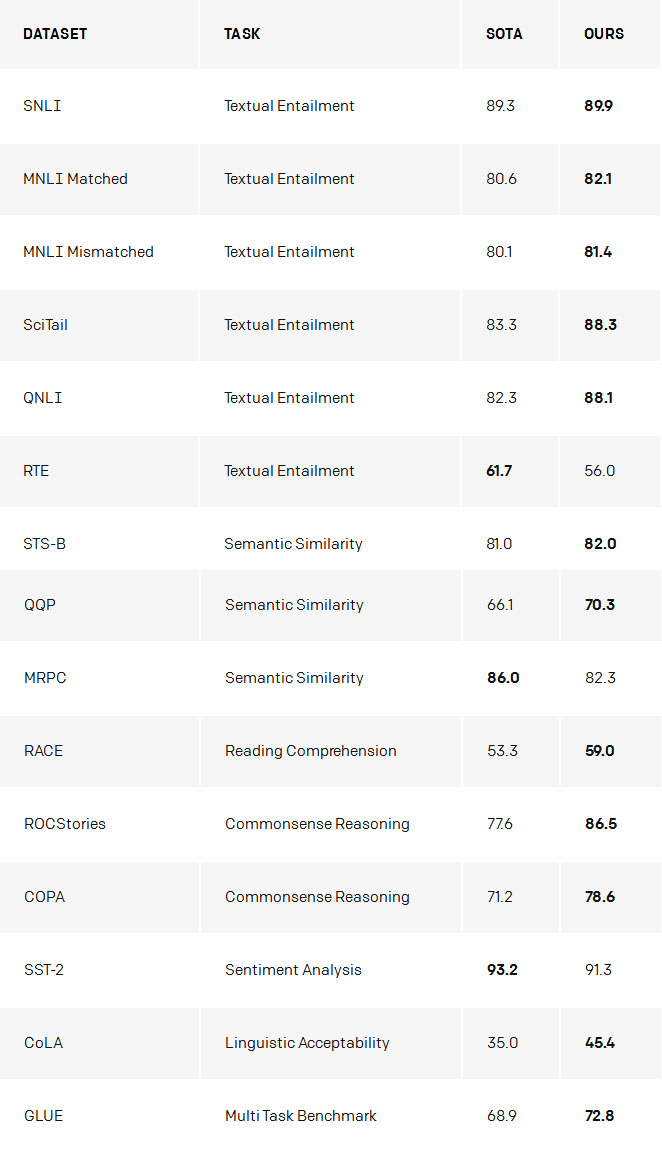
最令人兴奋的结果是研究者的方法在三个数据集(COPA,RACE和ROCStories)上的表现,旨在测试常识推理和阅读理解。模型在很大程度上获得了这些数据集的最新结果。这些数据集被认为需要多句子推理和重要常识来解决,而现在的结果表明我们的模型主要通过无监督学习来提高这些技能。这表明通过无监督技术来开发复杂的语言理解功能很有希望。
为什么是无监督学习?
监督学习是机器学习应用大获成功的核心。但是,它可能需要大量的,经过仔细清理的和高成本的数据集才能正常工作。无监督学习是有吸引力的,因为它有可能解决这些缺点。由于无监督学习消除了显式人类标记的瓶颈,因此它也随着当前趋势的增加,而增加了原始数据可计算性和可用性。无监督学习是非常活跃的研究领域,但其实际用途往往有限。
最近有人试图通过使用无监督学习来增强具有大量未标记数据的系统,从而进一步提高语言能力;通过无监督技术训练的单词表征可以使用由TB级信息组成的大型数据集,并且当与监督学习相结合时,可以提高各种NLP任务的性能。直到最近,这些NLP的无监督技术(例如GLoVe和word2vec)都使用简单模型(单词向量)和训练信号(单词本地共同出现)。Skip思维向量是值得注意的早期演示,展示了更复杂的方法潜在的可以实现的改进。但现在正在使用新技术,这些技术进一步提高了性能。这些包括使用预先训练的句子表示模型,情境中的单词向量(主要是ELMo和CoVE),以及使用定制架构来融合无监督预训练和监督微调的方法。
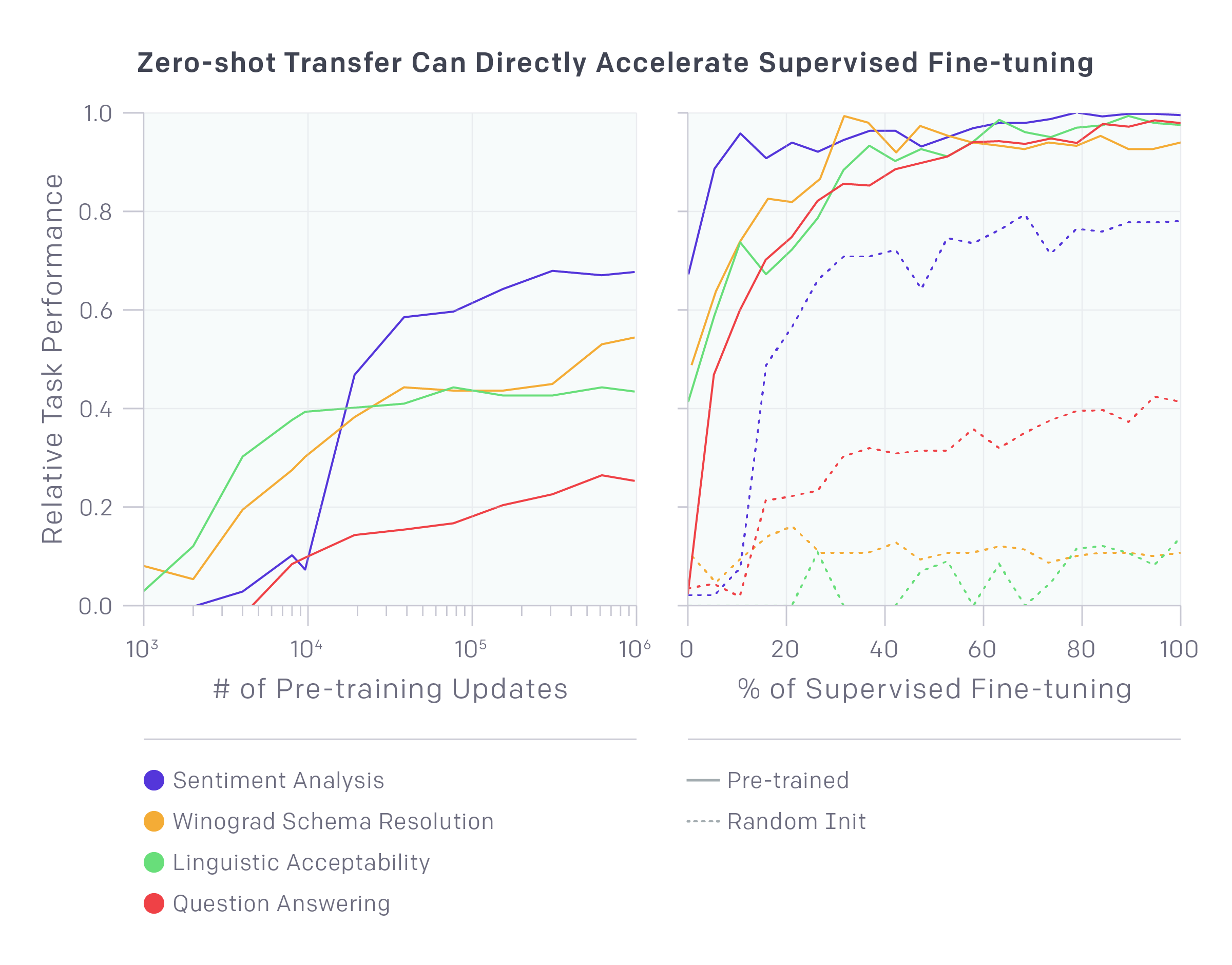
在大量文本的基础上对模型进行预训练,极大地提高了它在挑战性的自然语言处理任务上的性能,比如Winograd模式解析。
我们还注意到,可以使用底层语言模型执行任务,而无需对它们进行任何训练。例如,随着基础语言模型的改进,像选择题选择正确答案这样的任务性能会稳步增加。虽然这些方法的绝对性能仍然相对于受监督的最新技术而言仍然很低(对于问题回答,它仍然优于简单的滑动窗口基线),但这种行为在广泛集合的任务中具有鲁棒性。使用这些启发式方法,不包含关于任务和世界的信息的随机初始化网络不会比随机更好。
我们还可以使用模型中现有的语言功能来执行情感分析。对于由正面和负面电影评论中的句子组成的Stanford Sentiment Treebank数据集,可以使用语言模型通过在句子后面输入单词“very”来猜测评论是正面还是负面,并且观察模型预测词“积极”或“消极”的可能性。这种方法根本不需要根据任务调整模型,其性能与经典基线相当,准确度达到80%。
研究也验证了Transformer架构的鲁棒性和实用性,表明它具有足够的灵活性,可在广泛的任务中实现最新的结果,而无需复杂的特定任务或进行超参数调整。
缺点
这个项目有一些值得注意的突出问题:
- 计算要求:许多以前的NLP任务方法都是从头开始在单个GPU上训练相对较小的模型。新的方法需要高成本的预训练,用8个GPU耗时1个月。幸运的是,这只需要做一次,研究者发模型,以便其他人可以避免重复。它也是一个大型模型(与之前的工作相比),因此使用更多的计算和内存,研究者使用了37层(12块)Transformer架构,并且训练的序列最多可达512个。大多数实验都是在4个和8个GPU系统上进行的。该模型可以快速调整新任务,从而有助于减轻额外的资源需求。
- 通过文本学习现存的局限性和偏见:互联网上现成的书籍和文本不包含世界知识所有的准确信息。最近的研究表明,某些类型的信息很难通过文本学习,而其他工作表明了模型学习和利用数据分布中的偏见。
- 脆弱的广泛性:尽管我们的方法改善了广泛任务的性能,但目前的深度学习NLP模型仍然表现出违反直觉的行为,尤其是在以系统性,对抗性或分布式分布的方式进行评估时。尽管已经观察到一些迹象,但此方法不能解决这些问题。此方法表现出比先前的纯文本包含的神经方法更好的词法鲁棒性。在Glockner等人介绍的数据集中(2018年),模型性能达到83.75%,类似于通过WordNet整合外部知识的KIM。
未来
- 扩展规模:语言模型的性能改进与下游任务的改进密切相关。目前研究使用的是商品级别的硬件(一台8 GPU计算机)以及仅有几千本书籍(约5GB文本)的培训数据集。这表明使用经过充分验证的更多计算和数据方法有很大改进空间。
- 改进微调:方法目前非常简单。使用更复杂的适应和传输技术(例如ULMFiT中探索的技术)可能会有实质性的改进。
- 更好地理解生成性预训练:尽管我们已经讨论了一些想法,但更有针对性的实验和研究将有助于区分相互竞争的解释。例如,我们观察到的收益中,有多少是由于改进了处理更广泛背景的能力?又有多少是由于改进了世界知识的结果?

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消