











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






DeepMind发布新算法:生成查询网络GQN,可将2D照片渲染成3D模型
2018年06月15日 由 浅浅 发表
344454
0
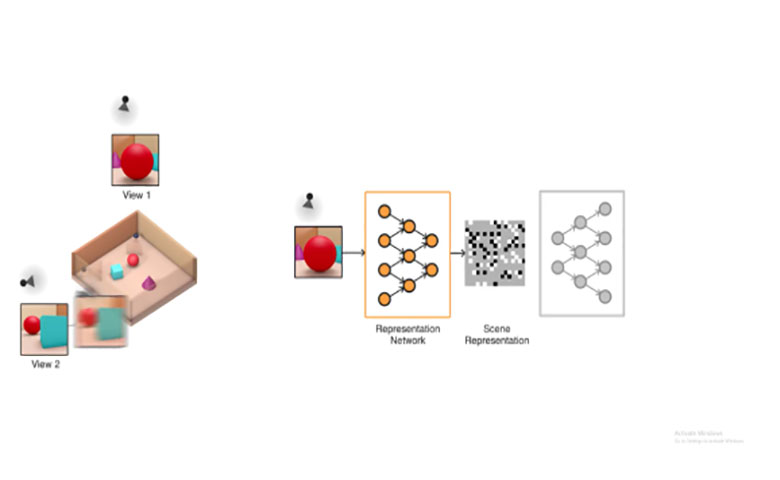
谷歌子公司DeepMind发布了一种新型计算机视觉算法,可以从2D快照生成场景的3D模型:生成查询网络(GQN)。
GQN的详细信息发表在Science杂志上,无需任何人工监督或训练即可“想象”并从任何角度渲染场景。如果只给出一小部分场景的图片,例如,地板上有一个彩色的球体的墙纸装饰房间,这个算法可以呈现出相反的、不可见的物体侧面,并从多个角度产生一个3D视图,甚至可以考虑到像阴影中的光线。
它旨在复制人类大脑了解其周围环境和物体之间物理交互的方式,并消除AI研究人员在数据集中注释图像的需求。大多数视觉识别系统都需要人员标记数据集中每个场景中每个对象的每个方面,这是一个费时费力的过程。
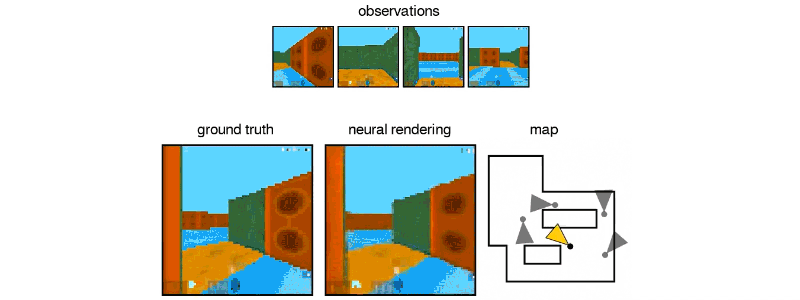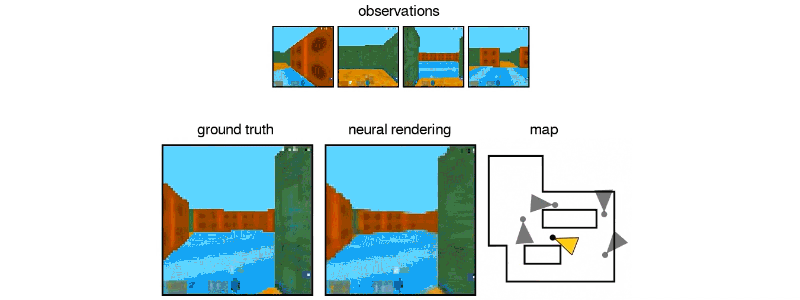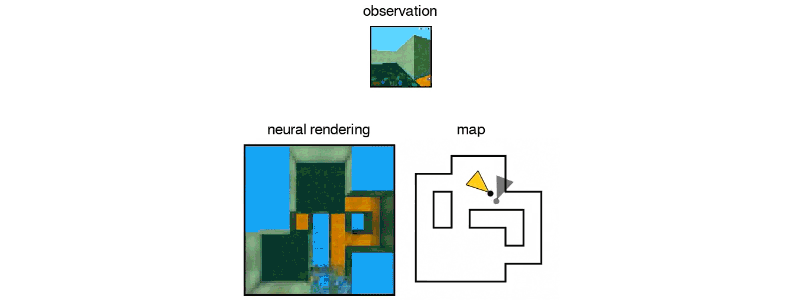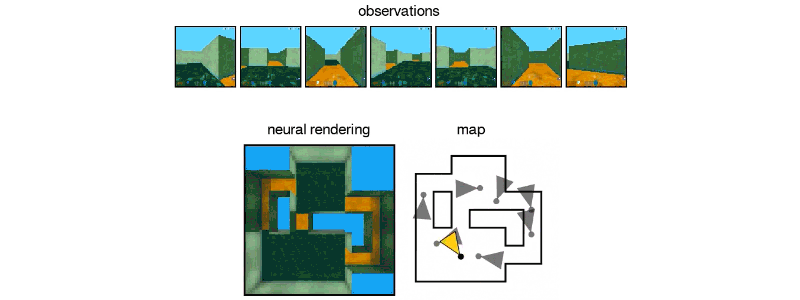
GQN从静态图像中想象出这个迷宫
“与婴儿和动物一样,GQN通过尝试理解从周围世界观察到的事物来学习,”DeepMind的研究人员在一篇博客文章中写道。“在这样做的时候,在没有任何人对场景内容的标注的情况下,GQN了解了看似合理的场景及其几何属性。”
该系统由两部分组成:表示网络和生成网络。前者获取输入数据并将其转换为描述场景的数学表示(矢量),后者则对场景进行图像处理。
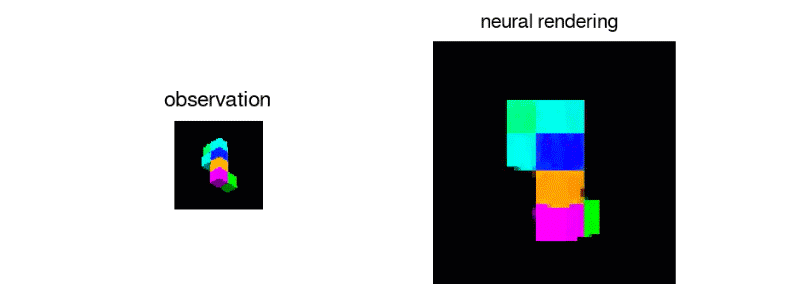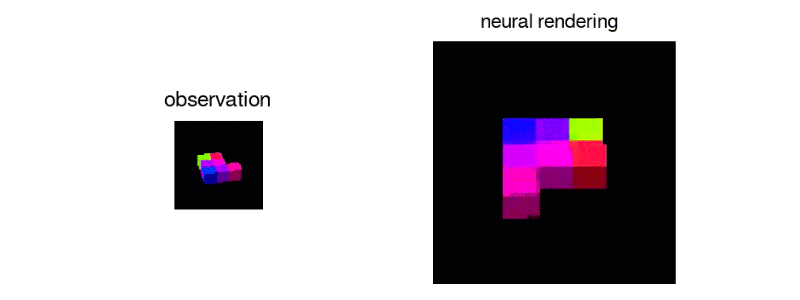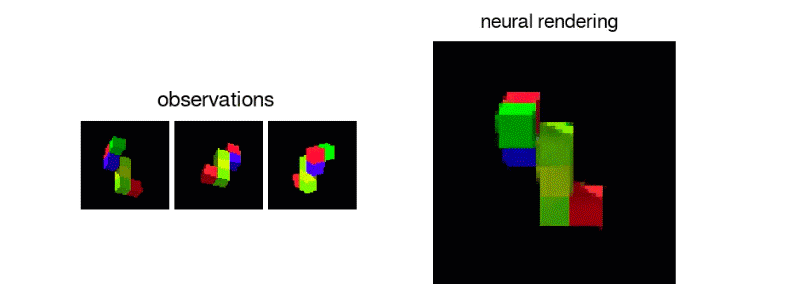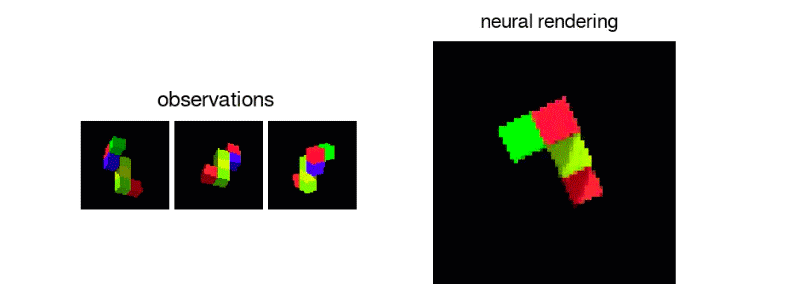
GQN从2D采样数据创建可操作的虚拟对象
为了训练这个系统,DeepMind的研究人员从不同角度提供了GQN场景图像,用这些图像中物体的纹理,颜色和光照以及它们之间的空间关系来进行训练。然后预测了这些物体的外观,即看起来是侧面还是后面。
利用其空间理解,GQN可以控制物体(例如,通过使用虚拟机器人手臂来拾取球体)。当它在场景中移动时,它会自我修正,当出现问题时它会调整预测。
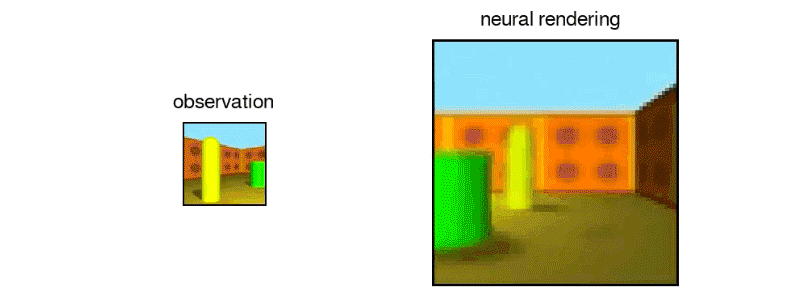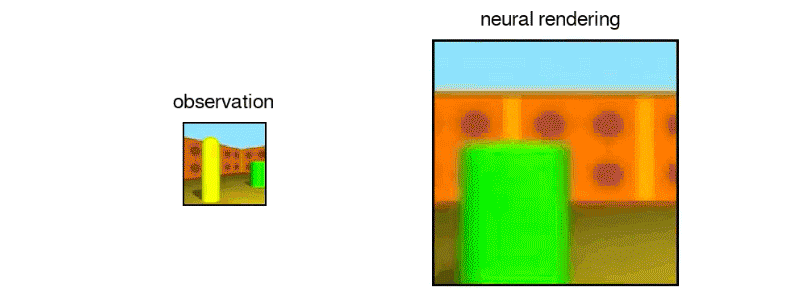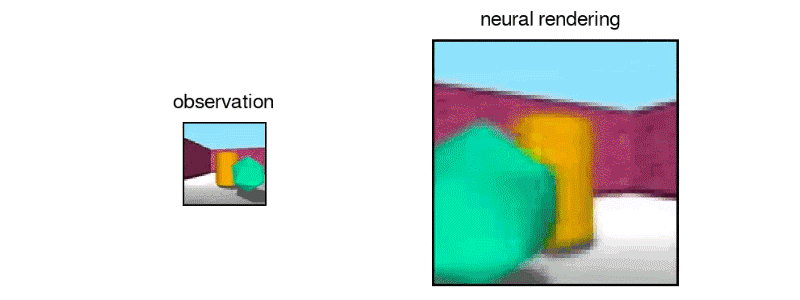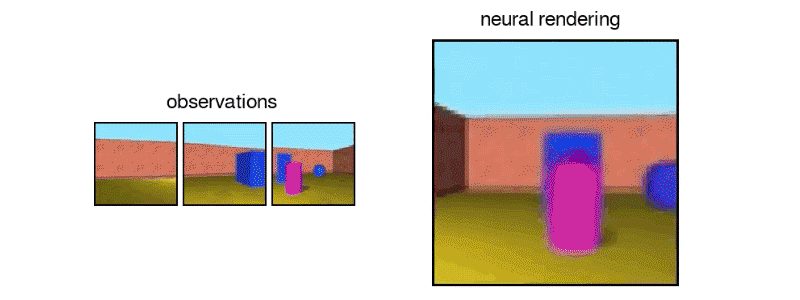
由GQN设想的另一个3D迷宫
GQN并非没有限制,它只在包含少量对象的简单场景中进行了测试,而且它无法生成复杂的3D模型。但DeepMind正在开发更强大的系统,这些系统需要更少的处理能力和更小的语料库,以及可处理更高分辨率图像的框架。
研究人员表示,“虽然我们的方法在实践部署之前还有很多需要完善,但我们相信这项工作对于完全自动的场景理解来说是相当重要的。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消