











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Bing研究人员开发新的方法,用于自动收集高质量AI训练数据
2018年06月19日 由 浅浅 发表
290122
0

微软Bing团队的研究人员已经开发出一种用于训练机器学习模型的高质量数据生成方法。CVPR会议之前发表的博客文章和论文中,他们描述了一个系统,该系统能够以准确的一致性区分准确标记的数据和标记不准确的数据。
研究人员写道:“获取足够高质量的训练数据通常是构建基于人工智能服务的最具挑战性的部分。通常,由人类标记的数据质量很高(错误相对较少),但成本高昂,无论是金钱还是时间方面。此外,自动方法允许大量成本低的数据生成,但会有更多错误标记。”
正如Bing团队解释的那样,训练算法需要收集数十万甚至数百万个数据样本,并手动将这些样本分类,这对于数据科学家来说无疑是艰巨的任务。一个经常使用的捷径是通过将类别列表放在一起从搜索引擎中抓取数据,对列表中的每个项目执行网络搜索并收集结果(例如,在构建可区分不同种类食物的计算机视觉算法的语料库过程中,可以执行“寿司”的图像搜索)。
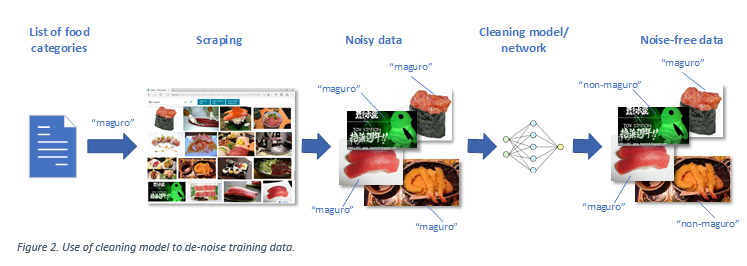
Bing团队的模型清除了来自语料库的噪音数据。
但并不是每个结果都与搜索类别相关,并且训练数据中的错误可能会导致机器学习模型中的偏差和不准确性。减少错误标记问题的一种方法是通过训练第二种算法找出不匹配数据并纠正它们,但这是一个处理密集型解决方案; 必须为每个类别训练一个模型。
Bing团队的方法采用了AI模型,可以实时纠正错误。在训练过程中,系统的一部分,类嵌入矢量学习选择最能代表每个类别的图像。同时,模型的另一部分,查询嵌入矢量学习将示例图像嵌入到相同的矢量中。随着训练的进行,系统的设计方式使得如果图像是类别中的一部分,则类别嵌入向量和查询图像向量变得越来越相似,如果不是类别的一部分,则进一步分离。
该系统最终识别它用于为每个类别找到高度代表性图像的模式。该团队说,它甚至可以在没有手动确认标记的情况下进行工作。
该团队写道,“这种方法对于为图像相关任务清理训练数据非常有效,我们相信它同样适用于视频,文字或演讲。”
关于此研究的博客文章和论文网址如下:
blogs.bing.com/search-quality-insights/2018-06/Artificial-intelligence-human-intelligence-Training-data-breakthrough
https://arxiv.org/pdf/1711.07131.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消