


















一文教你如何提高生成对抗网络性能方法!
与其他深度网络相比,GAN模型会在以下情况中受到严重影响。
- 不收敛(Non-convergence):模型不会收敛,更糟的是它们变得不稳定。
- 模式崩溃(Mode collapse):生成器产生单个或有限的模式。
- 训练迟钝(Slow training):训练生成器发生梯度消失。
有许多方法可以改进GAN。本文将探讨如何改进GAN。
- 更改损失函数以获得更好的优化得分。
- 为损失函数添加额外的惩罚来执行约束。
- 避免过度自信和过拟合。
- 更好的方式来优化模型。
- 添加标签
特征映射(Feature Mapping)
生成器试图找到最好的图像来欺骗鉴别器。当两个网络互相对抗时,“最佳”图像不断变化。但是,优化可能会变得过于贪心,使其陷入永无止境的猫捉老鼠游戏中。这是模型不收敛和模式崩溃的原因之一。
特征映射改变了生成器的损失函数,以最小化真实图像和生成图像的特征之间的统计差异。我们通过对图像特征f(x)平均值之间加上L2范数距离惩罚生成器。
![]()
其中f(x)是鉴别器中即时层的输出,用于提取图像特征。
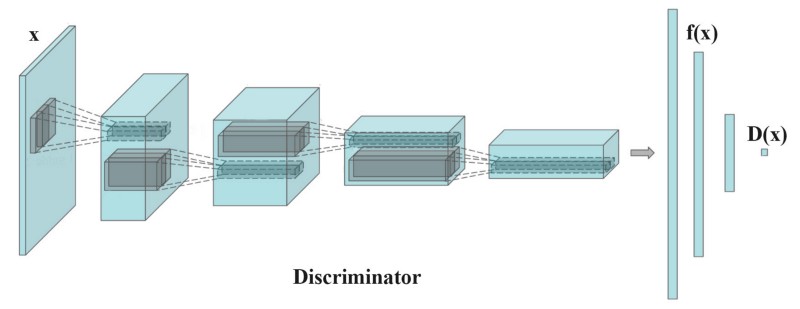
在这里,我们的目标不是简单地欺骗鉴别者。我们希望生成的图像具有与真实图像相同的特征。实际图像特征的平均值每个小批次都计算,每个批次有一定波动。这可能有利于缓解模式崩溃。它引入了随机性,使鉴别器不容易过拟合。
当训练期间GAN模型不稳定时,特征映射是有效的。
小批次歧视(Minibatch discrimination)
在发生模式崩溃时,所有被创建的图像看起来都差不多。我们将不同批次的真实图像和生成的图像分别送入鉴别器。我们计算图像x与同一批次中其余图像的相似性。我们在鉴别器中的一个密集层中附加相似度o(x),以区分这个图像是真实的还是生成的。
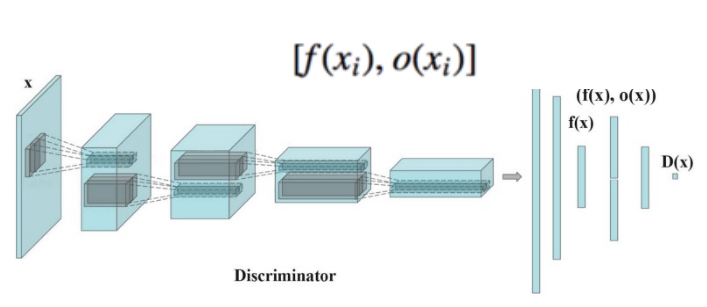
如果模式开始崩溃,则生成的图像的相似性会增加。如果图像的相似度与真实图像的相似度不匹配,鉴别器就可以判断图像是否为生成。这鼓励生成器创建多样性更接近真实图像的图像。
通过变换矩阵T计算图像xi与同一批次中的其他图像之间的相似性o(xi)。在下图中,xi是输入图像,xj是同一批次中的其余图像。
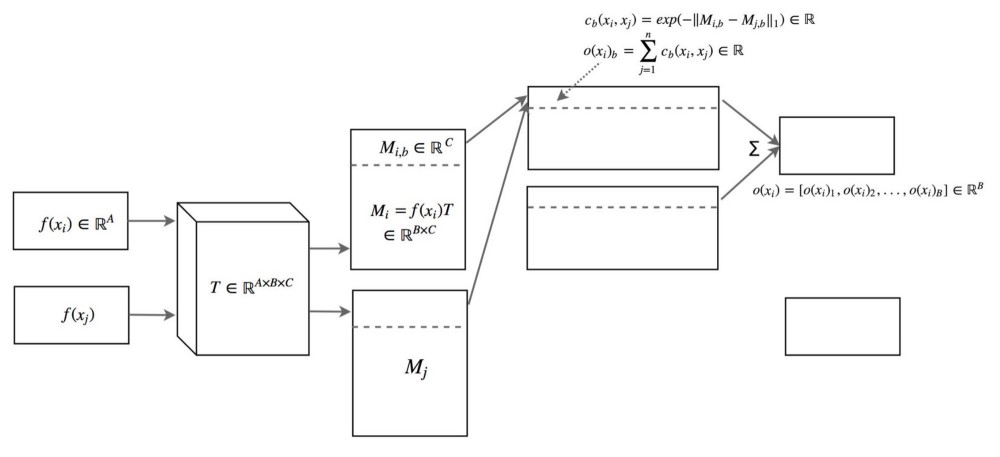
这些方程可能不大好看懂,但概念非常简单。我们使用变换矩阵T将特征xi转换为Mi,它是一个B×C矩阵。
![]()
我们使用L1范数和下面的等式推导图像i和j之间的相似性c(xi,xj)。
![]()
图像xi与该批次中其余图像之间的相似性o(xi)为:
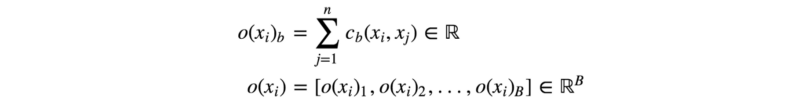
汇总:
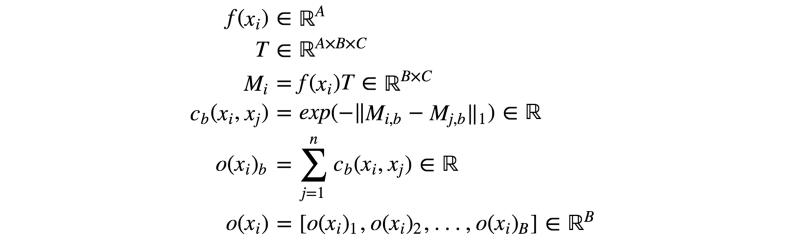
引用论文“Improved Techniques for Training GANs”
小批次歧视使得我们能够非常快速地生成具有视觉吸引力的样本,并且在这方面它优于特征匹配。
单面标签平滑(One-sided label smoothing)
深度神经网络可能会受到过度自信影响。例如,它使用很少的特征来分类对象。深度学习使用规则(regulation)和辍学(dropout )来缓解问题。在GAN中,当数据有噪音时,我们不希望过拟合模型。如果鉴别器过度依赖于一小组特征检测真实图像,则生成器可以很快模仿这些特征来愚弄鉴别器在GAN中,过度自信会造成严重伤害,因为鉴别器很容易被生成器利用。为了避免这个问题,当对任何真实图像的预测超过0.9时(D(real image)>0.9),我们惩罚鉴别器。我们的通过将目标标签值设置为0.9而不是1.0来完成它。下面是伪代码:
p = tf.placeholder(tf.float32, shape=[None, 10])
# Use 0.9 instead of 1.0.
feed_dict = {
p: [[0, 0, 0, 0.9, 0, 0, 0, 0, 0, 0]] # Image with label "3"
}
# logits_real_image is the logits calculated by
# the discriminator for real images.
d_real_loss = tf.nn.sigmoid_cross_entropy_with_logits(
labels=p, logits=logits_real_image)
虚拟批归一化(VBN)
在许多深度网络设计中,批归一化BM在成为事实上的标准。BM的平均值和方差由当前小批次得出。但是,它会创建样本之间的依赖关系。生成的图像并不相互独立。
![]()
在实验中,这反映在同一批次生成的图像显出的色调上。

第一批橙色调,第二批绿色调。
来自论文:https://arxiv.org/pdf/1701.00160v3.pdf
最初,我们从给出的独立样本的随机分布中抽样z。然而,批归一化产生的偏见打破了z的随机性。
虚拟批归一化(VBN)在训练前采样一个参考批次。在正向传播中,我们可以预选一个参考批次来计算BN的归一化参数(μ和σ)。但是,由于我们在整个训练中使用同一批次,因此我们模型对这个参考批次过拟合。为了减轻这一点,我们将参考批次与当前批次结合起来计算归一化参数。
历史平均(Historical averaging)
在历史平均中,我们跟踪最后t模型的参数。或者,如果我们需要保留一个长序列模型,我们更新模型参数的运行平均值。
我们在损失函数下面添加一个L2损失:
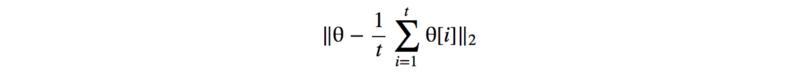
对于一些具有非凸对象函数的对抗,历史平均可能会使模型停止在均衡点附近并开始收敛。
经验回放(Experience replay)
为了避免鉴别器的过拟合,我们可以保留最近生成的图像,并将它们重放给与新生成的图像并行的鉴别器。因此,鉴别器将不会对生成器的某次特定实例过拟合。
多GAN
模式崩溃可能并不全是坏事。事实上,当模式崩溃时,图像质量通常会提高。事实上,我们可能会为每种模式收集最佳模型,并使用它们重新创建不同模式的图像。

论文:https://arxiv.org/pdf/1611.02163.pdf
鉴别器和生成器之间的平衡
鉴别器和生成器在拉锯战中尽可能压倒对方。生成器一直在积极创造最佳图像来击败鉴别器。如果鉴别器响应速度慢,则生成的图像将会收敛并且模式开始崩溃。相反,当鉴别器表现良好时,生成器的损失函数的梯度消失且学习缓慢。所以,我们要注意平衡生成器和鉴别器之间的损失,在训练GAN中找到最佳点。然而,这个解决方案有些难以捉摸。在鉴别器和生成器之间的交替梯度下降的过程中,定义它们之间的静态比例似乎就很不错,但许多人质疑这是否真的有益。如果这样做,我们实际上可能会看到研究人员每次生成器更新时训练鉴别器5次。也有其他平衡这两个网络的建议被提出,但其有效性同样遭到质疑。
一些研究人员质疑平衡这些网络的可行性和可取性。训练好的鉴别器无论如何都可以向生成器提供不从反馈。而且,训练生成器总是赶上鉴别器并不容易。相反,当生成器运行不良时,我们可能会将注意力转移到寻找没有接近零梯度的损失函数。
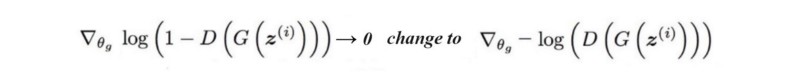
不过,问题依然存在。新的损失函数可能会给模型带来新的不稳定性。许多关于改进GAN的研究集中在寻找在训练期间具有非零梯度的损失函数。人们提出了许多建议,但关于它是否能达到宣传的结果,人们的报道却相互矛盾。但非收敛问题是现实存在的,模式崩溃也是常见的。这鼓励人们尝试不同的损失函数,并去期望寻求终极的损失函数。
鉴别器和生成器的网络容量
鉴别器的模型通常比生成器更复杂(更多的过滤器和层),好的鉴别器会提供好的信息。在许多GAN应用中,我们可能会遇到瓶颈问题,即增加生成器容量并不能提高质量。在确定瓶颈并加以解决之前,增加生成器的容量并不是首要任务。
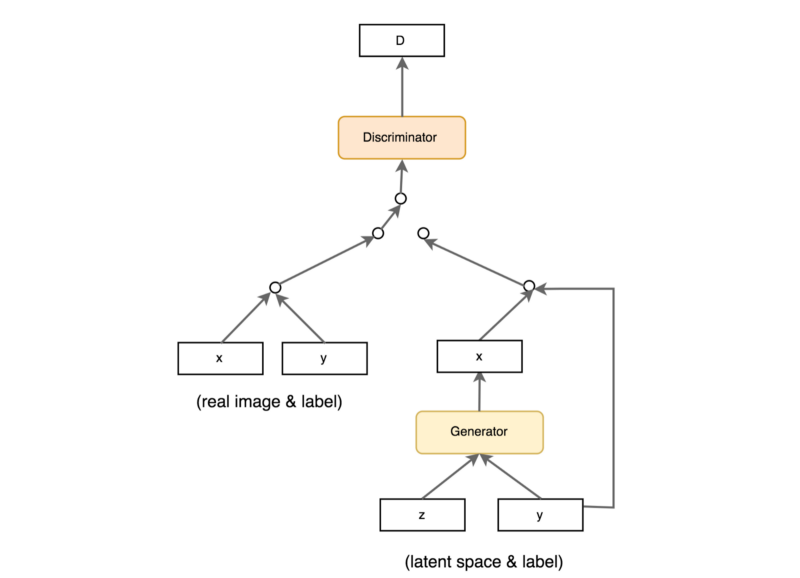
使用标签(CGAN)
许多数据集都带有对应于于样本对象类型的标签。将标签添加为潜在空间z的一部分并将它们馈送到鉴别器的输入中,有助于GAN性能的提高。下图是CGAN中利用样本中的标签的数据流。
损失函数
损失函数很重要吗?这个领域有这么多的研究,当然是因为它重要。但是如果你听说2017年的Google Brain论文,你肯定会有很多疑问。我们还没有看到特定的损失函数在所有GAN应用中可以一直表现出更好的图像质量,或者我们看到某种损失函数淘汰原始的GAN。我们最多可以说,如果你需要更好图像质量,你可能要测试不同的方法。但是每种方法都需要超参数优化。在Google的论文中,它表明GAN的性能对超参数非常敏感。为了使单独的方法起作用,可能需要大量的参数搜索。

改进表:https://github.com/hwalsuklee/tensorflow-generative-model-collections
改进建议
- 将图像像素值缩放到-1和1之间。使用tanh作为生成器的输出层。
- 用高斯分布实验取样z。
- 批归一化通常会使训练稳定。
- 使用PixelShuffle和转置卷积进行上采样。
- 避免使用最大池进行下采样。使用 convolution stride。
- Adam优化器通常比其他方法效果更好。
- 在将真实图像和生成图像送入鉴别器之前,为他们增加噪声。
GAN模型的原理还没有得到很好的理解。所以这些只是建议,不适用于所有情况。举个例子,LSGAN的论文报告RMSProp在实验中得到了更稳定的训练。这种情况很少见,但它表明提出通用建议非常的难。
随机播种(Random seed)
用于初始化模型参数的随机播种会影响GAN的性能。如下所示,测量GAN表现的FID得分在50次单独运行(训练)中的很小范围内变化。但是这个范围相对较小,很可能只在以后的微调中完成。
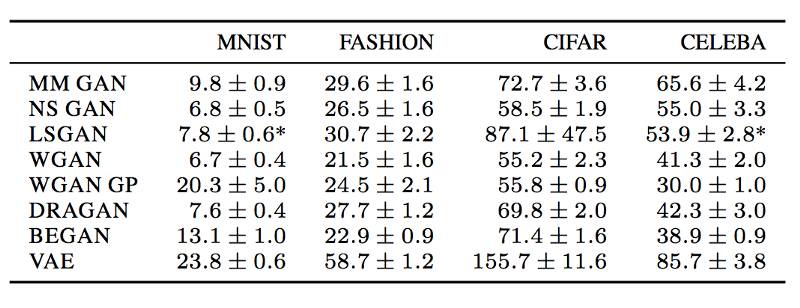
https://arxiv.org/pdf/1711.10337.pdf
参考
Improved Techniques for Training GANs:https://arxiv.org/pdf/1606.03498.pdf
本文由ATYUN译编,未经授权任何人不得转载。ATYUN专注人工智能。









