











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌:神经网络相似性如何帮助我们理解训练和泛化
2018年06月22日 由 浅浅 发表
465306
0

为了解决任务,深度神经网络(DNN)逐步将输入数据转换为一系列复杂表征(即跨越单个神经元的激活模式)。理解这些表征非常重要,不仅是为了解释,也是为了我们可以更智能地设计机器学习系统。但是,理解这些表征方式非常困难,特别是在比较网络中的表征。在之前的文章中,研究者概述了典型相关分析(CCA)作为理解和比较卷积神经网络(CNN)表征工具的好处,表明了它们在自下而上的模式中会聚,在训练过程中,早期层会逐渐融合到最终层中。
在“Insights on Representational Similarity in Neural Networks with Canonical Correlation”论文中,我们进一步开发了这项工作以提供对CNN的表征相似性的新见解,包括记忆网络之间的差异(例如,只能将他们以前见过的图像分类的网络)一般化的那些(例如,可以正确分类先前未见的图像的网络)。重要的是,我们还扩展了这种方法,以提供对循环神经网络(RNN)动力学的见解,这是一类对连续数据(如语言)特别有用的模型。比较RNN在许多方面与CNN相比很困难,但是RNN提出了额外的挑战,即它们的表征在序列过程中发生变化。这使得CCA及其有用的不变性成为研究RNN和CNN的理想工具。因此,我们另外开放了用于在神经网络上应用CCA的代码,希望能够帮助研究机构更好地理解网络动态。
记忆与泛化CNN的表征相似性
最终,机器学习系统只有在能够推广到以前从未见过的新情况时才有用。因此,了解区分推广网络和不推荐网络的因素是非常重要的,并且可能会导致改进泛化性能的新方法。为了研究代表的相似性是否可以预测泛化,我们研究了两种类型的CNN:
- 泛化网络:CNN使用未经修改的准确标签对数据进行培训,并学习推广新颖数据的解决方案。
- 记忆网络:对带有随机标签的数据集进行训练的CNN必须记住训练数据,并且不能根据定义进行泛化。
我们训练了每个网络的多个实例,仅在网络权重的初始随机值和训练数据的顺序上有所不同,并且使用新的加权方法来计算CCA距离度量,以比较每组内记忆和泛化网络表征。
我们发现,不同广义网络的群体一直汇聚到比记忆网络群更类似的表示(特别是在后面的层次中)(见下图)。在表示网络的最终预测的softmax,因为每个单独组中的网络进行类似的预测,所以每组广义和记忆网络的CCA距离显着减小。
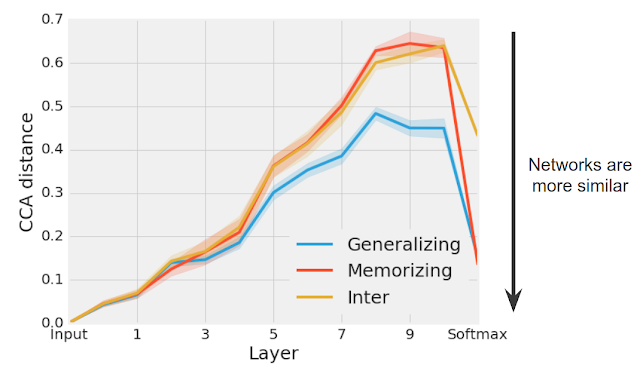
泛化网络组(蓝色)汇聚成比记忆网络组(红色)更类似的解决方案。在真实CIFAR-10标签(泛化)或随机CIFAR-10标签(记忆)之间以及训练的记忆和广义网络组(Inter)之间计算CCA距离。
最令人惊讶的是,在后面的隐藏层中,任何给定的记忆网络对之间的表征距离与记忆网络和泛化网络之间的表征距离大致相同,尽管这些网络是用完全不同的标签对数据进行训练的。直观地说,这个结果表明虽然有许多不同的方式来记忆训练数据(导致更大的CCA距离),但学习可泛化解决方案的方法更少。在未来的工作中,我们计划探索这种洞察力是否可以用于规范网络以学习更广泛的解决方案。
理解回归神经网络的训练动力学
到目前为止,我们只将CCA应用于对图像数据进行训练的CNN。然而,在训练过程中和序列的过程中,也可以应用CCA来计算在RNN中的表征相似性。将CCA应用到RNN,我们首先看RNN是否显示了我们在之前的CNN工作中观察到的自下而上的会聚模式。为了验证这一点,我们测量了在训练过程中和训练结束时的每一层的表征之间的CCA距离。我们发现,在训练的早期和训练过程中,与输入更接近的层的CCA距离比更深的层要更早下降,这表明,像CNN一样,RNN也会以自下向上的模式会聚(见下图)。
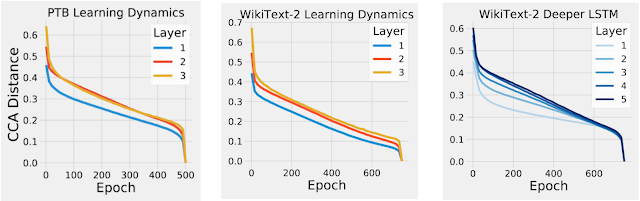
RNN在训练过程中的会聚动态呈现自下而上的特性,因为更接近输入的层在训练之前会聚到它们的最终表征。例如,在训练中,第1层比第2层更早会聚到其最终表征。Epoch指定了模型在训练过程中被查看的次数,而不同的颜色代表了不同层次的会聚动力学。
我们的论文中的其他发现表明,更广泛的网络(例如,每层具有更多神经元的网络)比狭隘的网络会聚到更相似的解决方案。我们还发现,具有相同结构但不同学习速率的网络会聚到具有相似性能但表征截然不同的群集。我们还将CCA应用于单个序列过程中的RNN动态,提供一些初步的洞察,以了解影响RNN表示的各种因素,而不是简单地将它应用到训练过程中。
结论
这些发现强化了分析和比较DNN表征的效用,以便提供对网络功能,泛化和会聚的见解。然而,仍然有许多问题尚未解决:在今后的工作中,我们希望揭示CNN和RNN中跨网络的表征哪些方面是保守的,以及这些见解是否可用于改善网络性能。
论文:arxiv.org/abs/1806.05759
代码:github.com/google/svcca/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消