











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用Python进行人脸聚类的详细教程
2018年07月12日 由 yuxiangyu 发表
126686
0
这篇文章的灵感来自读者Leonard Bogdonoff的一个问题:
类似这种“人脸聚类”或者说“身份聚类”的应用可用于辅助执法。
思考下面这个场景:两名劫匪在抢劫波士顿或纽约等繁华城市的银行。银行的安全摄像头工作正常,捕捉到了抢劫行为,但劫匪戴着头套,没办法看到他们的脸。
劫匪将现金藏在衣服下面逃离银行,摘掉面具,并将它们扔在附近的垃圾桶中,以免在公众场合显得可疑。
那么,他们会逃脱追责吗?也许会。
但安装在附近的加油站,餐馆和红灯/主要交叉路口的安全摄像头捕获了附近的所有行人活动。
在警察到达之后,他们可以利用人脸聚类来查找该区域内所有视频信息的所有独特的面孔 - 得到独特的面孔,可以:(1)手动调查它们并将它们与银行出纳员描述进行比较,(2)运行自动搜索将面孔与已知的罪犯数据库进行比较,或者(3)找好的刑警寻找可疑人员。
这当然是一个虚构的例子,但我希望你看到人脸聚类在现实世界中使用的价值。
人脸识别和人脸聚类并不相同,但概念高度相关。当进行面部识别时,我们使用监督学习,其中我们同时具有(1)我们想要识别的面部的示例图像,以及(2)与每个面部相对应的名字(即,“类标签”)。
但对人脸聚类,我们需要执行无监督学习,我们只有没有名字或者说标签的人脸本身。从这里,我们需要识别和计算数据集中某些独特的人。
在本文的第一部分中,我们将讨论我们的人脸聚类数据集以及我们将用于构建项目的项目结构。
在这里,我将帮助你编写两个Python脚本:
然后,我们将在样本数据集上运行我们的人脸聚类管道并检查结果。
参考:https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/
以下是你在Python环境中需要的所有内容:
如果有GPU,则需要安装带有CUDA的dlib。

由于2018年世界杯半决赛,我认为将人脸聚类应用于著名足球运动员的面孔会很有趣。
从上面的图1中可以看出,我已经整理了五个足球运动员的数据集,包括:
数据集中有129个图像。
我们的目标是提取量化图像中每个面部的特征,并将得到的“面部特征向量”聚类。理想情况下,每个足球运动员都拥有自己的簇,仅包含他们自己的脸。
我们的项目结构如下:
我们的项目有一个目录和三个文件:
通过深度学习编码面孔
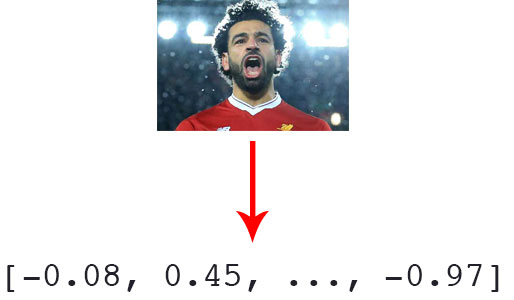
为了用数字表示人脸,我们用神经网络生成的128维特征向量对数据集中的所有人脸进行量化。
在我们对一组人脸进行聚类之前,我们首先需要对它们进行量化。这个量化人脸的过程将使用深度神经网络完成,该网络负责:
我将讨论这个深度神经网络如何工作以及如何进行训练。我们的encode_faces .py 脚本包含为每张脸提取128维特征向量表示的所有代码。
要查看此进程的执行方式,请创建名为encode_faces .py的文件 ,并插入以下代码:
我们所需的包在2-7行导入。注意:
然后,我们解析命令行参数上(10-17):
我还要提到的是,如果你认为这个脚本运行缓慢,或者你希望在没有GPU的情况下实时运行人脸聚类,可以将--detection-method设置为hog ,替代cnn。虽然CNN脸检测更准确,但在没有GPU运行实时检测速度太慢。
让我们抓取输入数据集中所有图像的路径:
在第4行,我们使用命令行参数中提供的数据集路径创建数据集中所有的imagePath列表 。
然后,初始化我们的data列表,我们稍后会填充图像路径,边界框和面部编码。
让我们开始遍历所有的imagePaths:
在 第2行,我们开始遍历imagePaths并继续加载(第8行)。然后我们在图像中交换颜色通道, 因为dlib默认rgb排序而不是OpenCV默认的bgr(第9行)。
现在已经处理了图像,让我们检测所有的人脸并抓取它们的边界框坐标:
我们必须先检测图像中人脸的实际位置,然后再对其进行量化(3-4)。你会注意到 face_recognition API非常易于使用。
注意: 我们使用CNN面部检测器以获得更高的精度,但如果使用的是CPU而不是GPU,则运行时间会长得多。如果希望编码脚本运行得更快或系统运行更快,并且你的系统没有足够的内存或CPU支持CNN面部检测器,请改用HOG + Linear SVM方法。
让我们来看看这个脚本主要部分。在下一个部分中,我们将计算面部编码:
在这里,我们计算rgb图像中每个检测到的人脸的128维面部编码(第2行)。
对于每个检测到的面部+编码,我们构建一个字典(第6和7行),其中包括:
然后我们将字典添加到我们的data列表中(第8行)。稍后当我们想要查看哪些人脸属于哪个簇时,我们会用到此信息。
要结束此脚本,我们只需将数据列表写入序列化的pickle文件:
使用我们的命令行参数 args [ “encodings” ] 作为路径+文件名,我们将数据列表作为序列化的pickle文件写入磁盘(第3-5行)。
请访问文末链接下载代码和图像数据集,数据集可以换成自己的。
然后,打开一个终端并激活你的Python虚拟环境(如果你用了虚拟环境的话)。
然后,使用两个命令行参数,执行脚本编码球员的脸,如下:
此过程可能需要一段时间,你可以用终端输出跟踪进度。
如果你使用GPU,大约1-2分钟。只要确保你安装DLIB与CUDA,把你的GPU的优势发挥出来。
但是,如果只使用CPU在笔记本电脑上执行脚本,则脚本可能需要运行20-30分钟。
现在我们已经将数据集中的所有的人脸都量化并编码为128维向量,下一步就是将它们聚类成组。
我们希望每个人都有自己独立的簇。问题是,许多聚类算法,如k-means和Hierarchical Agglomerative Clustering,要求我们提前指定簇的数量。
在这个例子中,我们知道只有五个足球运动员,但在实际应用中,你可能并不知道数据集中有多少个人。
因此,我们需要使用基于密度或基于图的聚类算法,这样的算法不仅可以聚类数据点,还可以根据数据密度确定聚类数量。
对于人脸聚类,我推荐使用两种算法:
我们将在本教程中使用DBSCAN,因为我们的数据集相对较小。对于真正庞大的数据集,应该考虑使用Chinese whispers 算法,因为它是time linear的(详见wiki:Chinese Whispers)。
DBSCAN算法通过将在n维空间中紧密排列的点分组 。靠在一起的点被分到同一个簇中。
DBSCAN也可以轻易的处理异常值,如果它们落在他们的“最近邻”很远的低密度区域,则标记它们。
让我们继续使用DBSCAN实现人脸聚类。
打开一个新文件,将其命名为cluster_faces .py ,然后插入以下代码:
DBSCAN内置在scikit-learn中。我们在第2行导入DBSCAN实现 。
我们还从imutils导入build_montages从模块(3行)。我们将使用此函数为每个簇构建“蒙太奇的脸”。
我们的其他导入在第4-7行 。
我们解析两个命令行参数:
让我们加载面部嵌入数据:
在这个块中我们有:
现在我们可以 在下一个代码块中对编码进行聚类 :
为了对编码进行聚类,我们只需创建一个DBSCAN 对象,然后 将模型fit(拟合)到encodings本身(第3和4行)。
现在让我们确定数据集中的独特人类!
第7行, clt 。labels_ 包含数据集中所有人脸的标签ID(即每个人脸所属的簇)。要查找独特面孔或标签的ID,我们只需使用NumPy的unique功能。结果是唯一的labelIDs列表 。
在 第8行, 我们计算numUniqueFaces 。有可能是值 - 1 ,在labelIDs中这个值对应于“异常值”类,即128维嵌入远离添加好的其他簇很多的点。这些点被称为“异常值”(或者说,离群值),根据人脸聚类的应用它可能值得研究或简单地丢弃。
在我们的例子中,我们设计 了计数中的负的labelID,因为我们知道我们的数据集只包含5个人的图像。是否这样做在很大程度上取决于你的项目。
我们接下来的三个代码块的目标是在我们的数据集中生成独特的球员的面部蒙太奇。
循环遍历所有独特的labelID :
在第7-9行, 我们找到当前labelID的所有索引 ,然后抓取最多25个图像的随机样本嵌入蒙太奇中。
face列表白喊面部图像本身(10行)。我们需要另一个循环来填充此列表:
我们开始在随机样本中循环遍历所有的idx(第2行)。
在循环的第一部分内,我们:
要完成我们的最外层的循环,让我们构建蒙太奇并将其显示在屏幕上:
我们采用 build_montages 的功能imutils以生成单个图像 蒙太奇 含有5×5的网格 面 (2线)。
从那里,我们 标题 窗口(第5和6行),然后 在我们的屏幕上显示窗口中的 蒙太奇。
只要OpenCV打开的窗口打开,你可以按一个键显示下一个人脸蒙太奇。
此脚本只需要一个命令行参数 - 编码文件的路径。要为执行人脸聚类,只需在终端中输入以下命令:
识别出五个人脸簇的类。face ID为-1包含找到的所有异常值。你将在屏幕上看到群集蒙太奇。按键生成下一个面部簇的蒙太奇(窗口处于焦点位置,以便OpenCV的highgui模块可以捕获你的按键)。
以下是我们的128维面部嵌入和DBSCAN聚类算法在我们的数据集上生成的人脸聚类:




最后,陌生的人类被挑了出来(实际上它是先显示的):

这张梅西的照片并没有被聚类成功,而是识别为一张“未知的面孔”。我们的Python人脸聚类算法很好地完成了对图像的聚类,只是对这个人脸图像进行了错误的聚类。
在我们数据集中的5个人的129张图像中,只有一张脸没有被分组到现有的簇中。
我们的无监督学习DBSCAN方法生成了五个簇。不幸的是,梅西有一个图片并没有与他的其他图片放在一起,但整体来说这种方法效果不错。
更多图像识别数据集下载“点击”这里
你好Adrian,能介绍下身份聚类吗?我有一个照片数据集,但我无法确定如何处理它们来识别特定的人。
类似这种“人脸聚类”或者说“身份聚类”的应用可用于辅助执法。
思考下面这个场景:两名劫匪在抢劫波士顿或纽约等繁华城市的银行。银行的安全摄像头工作正常,捕捉到了抢劫行为,但劫匪戴着头套,没办法看到他们的脸。
劫匪将现金藏在衣服下面逃离银行,摘掉面具,并将它们扔在附近的垃圾桶中,以免在公众场合显得可疑。
那么,他们会逃脱追责吗?也许会。
但安装在附近的加油站,餐馆和红灯/主要交叉路口的安全摄像头捕获了附近的所有行人活动。
在警察到达之后,他们可以利用人脸聚类来查找该区域内所有视频信息的所有独特的面孔 - 得到独特的面孔,可以:(1)手动调查它们并将它们与银行出纳员描述进行比较,(2)运行自动搜索将面孔与已知的罪犯数据库进行比较,或者(3)找好的刑警寻找可疑人员。
这当然是一个虚构的例子,但我希望你看到人脸聚类在现实世界中使用的价值。
使用Python进行人脸聚类
人脸识别和人脸聚类并不相同,但概念高度相关。当进行面部识别时,我们使用监督学习,其中我们同时具有(1)我们想要识别的面部的示例图像,以及(2)与每个面部相对应的名字(即,“类标签”)。
但对人脸聚类,我们需要执行无监督学习,我们只有没有名字或者说标签的人脸本身。从这里,我们需要识别和计算数据集中某些独特的人。
在本文的第一部分中,我们将讨论我们的人脸聚类数据集以及我们将用于构建项目的项目结构。
在这里,我将帮助你编写两个Python脚本:
- 一个用于提取和量化数据集中的人脸
- 另一个是对面部进行聚类,其中每个结果聚类(理想情况下)代表一个独特的个体
然后,我们将在样本数据集上运行我们的人脸聚类管道并检查结果。
配置开发环境
参考:https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/
以下是你在Python环境中需要的所有内容:
- OpenCV
- dlib
- face_recognition
- imutils
- scikit-learn
如果有GPU,则需要安装带有CUDA的dlib。
我们的人脸聚类数据集
由于2018年世界杯半决赛,我认为将人脸聚类应用于著名足球运动员的面孔会很有趣。
从上面的图1中可以看出,我已经整理了五个足球运动员的数据集,包括:
- 穆罕默德·萨拉赫
- 内马尔
- C罗
- 里奥·梅西
- 路易斯·苏亚雷斯
数据集中有129个图像。
我们的目标是提取量化图像中每个面部的特征,并将得到的“面部特征向量”聚类。理想情况下,每个足球运动员都拥有自己的簇,仅包含他们自己的脸。
面对集群项目结构
我们的项目结构如下:
$ tree --dirsfirst
.
├── dataset [129 entries]
│ ├── 00000000.jpg
│ ├── 00000001.jpg
│ ├── 00000002.jpg
│ ├── ...
│ ├── 00000126.jpg
│ ├── 00000127.jpg
│ └── 00000128.jpg
├── encode_faces.py
├── encodings.pickle
└── cluster_faces.py
1 directory, 132 files
我们的项目有一个目录和三个文件:
- dataset / :包含我们五个足球运动员的129张照片。请注意,在上面的输出中,文件名或其他文件中没有用于标识每个图像中的人员标识信息!根据文件名单独知道哪个足球运动员在哪个图像中是不可能的。我们将设计一个人脸聚类算法来识别数据集中相似且唯一的脸。
- encode_faces .py :第一个脚本,它为数据集中的所有的人脸计算面部嵌入并输出一个序列化的编码文件。
- encodings.pickle :我们的面部嵌入序列化的pickle文件。
- cluster_faces .py :在这个脚本中我们将聚类相似的人脸并找到异常值。
通过深度学习编码面孔
为了用数字表示人脸,我们用神经网络生成的128维特征向量对数据集中的所有人脸进行量化。
在我们对一组人脸进行聚类之前,我们首先需要对它们进行量化。这个量化人脸的过程将使用深度神经网络完成,该网络负责:
- 接受输入图像
- 并输出128维特征向量,量化人脸
我将讨论这个深度神经网络如何工作以及如何进行训练。我们的encode_faces .py 脚本包含为每张脸提取128维特征向量表示的所有代码。
要查看此进程的执行方式,请创建名为encode_faces .py的文件 ,并插入以下代码:
# import the necessary packages
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
我们所需的包在2-7行导入。注意:
- paths,来自我的imutils包
- face_recognition,(https://github.com/ageitgey/face_recognition)
然后,我们解析命令行参数上(10-17):
- --dataset:人脸和图像输入目录的路径。
- --encodings:包含面部编码的输出序列化pickle文件的路径。
- --detection-method:你可以使用卷积神经网络(CNN)或方向梯度直方图(HOG)方法在量化面部之前检测输入图像中的人脸。CNN方法更准确(但更慢),而HOG方法更快(但不太准确)。
我还要提到的是,如果你认为这个脚本运行缓慢,或者你希望在没有GPU的情况下实时运行人脸聚类,可以将--detection-method设置为hog ,替代cnn。虽然CNN脸检测更准确,但在没有GPU运行实时检测速度太慢。
让我们抓取输入数据集中所有图像的路径:
# grab the paths to the input images in our dataset, then initialize
# out data list (which we'll soon populate)
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
在第4行,我们使用命令行参数中提供的数据集路径创建数据集中所有的imagePath列表 。
然后,初始化我们的data列表,我们稍后会填充图像路径,边界框和面部编码。
让我们开始遍历所有的imagePaths:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# load the input image and convert it from RGB (OpenCV ordering)
# to dlib ordering (RGB)
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
print(imagePath)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
在 第2行,我们开始遍历imagePaths并继续加载(第8行)。然后我们在图像中交换颜色通道, 因为dlib默认rgb排序而不是OpenCV默认的bgr(第9行)。
现在已经处理了图像,让我们检测所有的人脸并抓取它们的边界框坐标:
# detect the (x, y)-coordinates of the bounding boxes
# corresponding to each face in the input image
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
我们必须先检测图像中人脸的实际位置,然后再对其进行量化(3-4)。你会注意到 face_recognition API非常易于使用。
注意: 我们使用CNN面部检测器以获得更高的精度,但如果使用的是CPU而不是GPU,则运行时间会长得多。如果希望编码脚本运行得更快或系统运行更快,并且你的系统没有足够的内存或CPU支持CNN面部检测器,请改用HOG + Linear SVM方法。
让我们来看看这个脚本主要部分。在下一个部分中,我们将计算面部编码:
# compute the facial embedding for the face
encodings = face_recognition.face_encodings(rgb, boxes)
# build a dictionary of the image path, bounding box location,
# and facial encodings for the current image
d = [{"imagePath": imagePath, "loc": box, "encoding": enc}
for (box, enc) in zip(boxes, encodings)]
data.extend(d)
在这里,我们计算rgb图像中每个检测到的人脸的128维面部编码(第2行)。
对于每个检测到的面部+编码,我们构建一个字典(第6和7行),其中包括:
- 输入图像的路径
- 图像中人脸的位置(即边界框)
- 128维编码本身
然后我们将字典添加到我们的data列表中(第8行)。稍后当我们想要查看哪些人脸属于哪个簇时,我们会用到此信息。
要结束此脚本,我们只需将数据列表写入序列化的pickle文件:
# dump the facial encodings data to disk
print("[INFO] serializing encodings...")
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
使用我们的命令行参数 args [ “encodings” ] 作为路径+文件名,我们将数据列表作为序列化的pickle文件写入磁盘(第3-5行)。
运行面部编码脚本
请访问文末链接下载代码和图像数据集,数据集可以换成自己的。
然后,打开一个终端并激活你的Python虚拟环境(如果你用了虚拟环境的话)。
然后,使用两个命令行参数,执行脚本编码球员的脸,如下:
$ python encode_faces.py --dataset dataset --encodings encodings.pickle
[INFO] quantifying faces...
[INFO] processing image 1/129
dataset/00000038.jpg
[INFO] processing image 2/129
dataset/00000010.jpg
[INFO] processing image 3/129
dataset/00000004.jpg
...
[INFO] processing image 127/129
dataset/00000009.jpg
[INFO] processing image 128/129
dataset/00000021.jpg
[INFO] processing image 129/129
dataset/00000035.jpg
[INFO] serializing encodings...
此过程可能需要一段时间,你可以用终端输出跟踪进度。
如果你使用GPU,大约1-2分钟。只要确保你安装DLIB与CUDA,把你的GPU的优势发挥出来。
但是,如果只使用CPU在笔记本电脑上执行脚本,则脚本可能需要运行20-30分钟。
聚类面孔
现在我们已经将数据集中的所有的人脸都量化并编码为128维向量,下一步就是将它们聚类成组。
我们希望每个人都有自己独立的簇。问题是,许多聚类算法,如k-means和Hierarchical Agglomerative Clustering,要求我们提前指定簇的数量。
在这个例子中,我们知道只有五个足球运动员,但在实际应用中,你可能并不知道数据集中有多少个人。
因此,我们需要使用基于密度或基于图的聚类算法,这样的算法不仅可以聚类数据点,还可以根据数据密度确定聚类数量。
对于人脸聚类,我推荐使用两种算法:
- Density-based spatial clustering of applications with noise (DBSCAN)
- Chinese whispers聚类
我们将在本教程中使用DBSCAN,因为我们的数据集相对较小。对于真正庞大的数据集,应该考虑使用Chinese whispers 算法,因为它是time linear的(详见wiki:Chinese Whispers)。
DBSCAN算法通过将在n维空间中紧密排列的点分组 。靠在一起的点被分到同一个簇中。
DBSCAN也可以轻易的处理异常值,如果它们落在他们的“最近邻”很远的低密度区域,则标记它们。
让我们继续使用DBSCAN实现人脸聚类。
打开一个新文件,将其命名为cluster_faces .py ,然后插入以下代码:
# import the necessary packages
from sklearn.cluster import DBSCAN
from imutils import build_montages
import numpy as np
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-j", "--jobs", type=int, default=-1,
help="# of parallel jobs to run (-1 will use all CPUs)")
args = vars(ap.parse_args())
DBSCAN内置在scikit-learn中。我们在第2行导入DBSCAN实现 。
我们还从imutils导入build_montages从模块(3行)。我们将使用此函数为每个簇构建“蒙太奇的脸”。
我们的其他导入在第4-7行 。
我们解析两个命令行参数:
- --encodings:我们在之前的脚本中生成的编码pickle文件的路径。
- --jobs:DBSCAN是多线程的,可以将参数传递给包含要运行的并行作业数的构造函数。值 - 1 的意思为使用所有可用的CPU(也是该命令行参数的默认值)。
让我们加载面部嵌入数据:
# load the serialized face encodings + bounding box locations from
# disk, then extract the set of encodings to so we can cluster on
# them
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
data = np.array(data)
encodings = [d["encoding"] for d in data]
在这个块中我们有:
- 从磁盘加载面部编码的data(第5行)。
- 将data处理为NumPy数组(第6行)。
- 从data中提取128维编码 ,将它们放在一个列表中(第7行)。
现在我们可以 在下一个代码块中对编码进行聚类 :
# cluster the embeddings
print("[INFO] clustering...")
clt = DBSCAN(metric="euclidean", n_jobs=args["jobs"])
clt.fit(encodings)
# determine the total number of unique faces found in the dataset
labelIDs = np.unique(clt.labels_)
numUniqueFaces = len(np.where(labelIDs > -1)[0])
print("[INFO] # unique faces: {}".format(numUniqueFaces))
为了对编码进行聚类,我们只需创建一个DBSCAN 对象,然后 将模型fit(拟合)到encodings本身(第3和4行)。
现在让我们确定数据集中的独特人类!
第7行, clt 。labels_ 包含数据集中所有人脸的标签ID(即每个人脸所属的簇)。要查找独特面孔或标签的ID,我们只需使用NumPy的unique功能。结果是唯一的labelIDs列表 。
在 第8行, 我们计算numUniqueFaces 。有可能是值 - 1 ,在labelIDs中这个值对应于“异常值”类,即128维嵌入远离添加好的其他簇很多的点。这些点被称为“异常值”(或者说,离群值),根据人脸聚类的应用它可能值得研究或简单地丢弃。
在我们的例子中,我们设计 了计数中的负的labelID,因为我们知道我们的数据集只包含5个人的图像。是否这样做在很大程度上取决于你的项目。
我们接下来的三个代码块的目标是在我们的数据集中生成独特的球员的面部蒙太奇。
循环遍历所有独特的labelID :
# loop over the unique face integers
for labelID in labelIDs:
# find all indexes into the `data` array that belong to the
# current label ID, then randomly sample a maximum of 25 indexes
# from the set
print("[INFO] faces for face ID: {}".format(labelID))
idxs = np.where(clt.labels_ == labelID)[0]
idxs = np.random.choice(idxs, size=min(25, len(idxs)),
replace=False)
# initialize the list of faces to include in the montage
faces = []
在第7-9行, 我们找到当前labelID的所有索引 ,然后抓取最多25个图像的随机样本嵌入蒙太奇中。
face列表白喊面部图像本身(10行)。我们需要另一个循环来填充此列表:
# loop over the sampled indexes
for i in idxs:
# load the input image and extract the face ROI
image = cv2.imread(data[i]["imagePath"])
(top, right, bottom, left) = data[i]["loc"]
face = image[top:bottom, left:right]
# force resize the face ROI to 96x96 and then add it to the
# faces montage list
face = cv2.resize(face, (96, 96))
faces.append(face)
我们开始在随机样本中循环遍历所有的idx(第2行)。
在循环的第一部分内,我们:
- 从磁盘加载image并使用在我们的面部嵌入步骤中找到的边界框坐标提取face ROI(第4-6行)。
- 调整人脸到固定尺寸96×96(行10),所以我们可以把它添加到脸部蒙太奇(11行)用于可视化每个簇。
要完成我们的最外层的循环,让我们构建蒙太奇并将其显示在屏幕上:
# create a montage using 96x96 "tiles" with 5 rows and 5 columns
montage = build_montages(faces, (96, 96), (5, 5))[0]
# show the output montage
title = "Face ID #{}".format(labelID)
title = "Unknown Faces" if labelID == -1 else title
cv2.imshow(title, montage)
cv2.waitKey(0)
我们采用 build_montages 的功能imutils以生成单个图像 蒙太奇 含有5×5的网格 面 (2线)。
从那里,我们 标题 窗口(第5和6行),然后 在我们的屏幕上显示窗口中的 蒙太奇。
只要OpenCV打开的窗口打开,你可以按一个键显示下一个人脸蒙太奇。
面对聚类结果
此脚本只需要一个命令行参数 - 编码文件的路径。要为执行人脸聚类,只需在终端中输入以下命令:
$ python cluster_faces.py --encodings encodings.pickle
[INFO] loading encodings...
[INFO] clustering...
[INFO] # unique faces: 5
[INFO] faces for face ID: -1
[INFO] faces for face ID: 0
[INFO] faces for face ID: 1
[INFO] faces for face ID: 2
[INFO] faces for face ID: 3
[INFO] faces for face ID: 4
识别出五个人脸簇的类。face ID为-1包含找到的所有异常值。你将在屏幕上看到群集蒙太奇。按键生成下一个面部簇的蒙太奇(窗口处于焦点位置,以便OpenCV的highgui模块可以捕获你的按键)。
以下是我们的128维面部嵌入和DBSCAN聚类算法在我们的数据集上生成的人脸聚类:
最后,陌生的人类被挑了出来(实际上它是先显示的):
这张梅西的照片并没有被聚类成功,而是识别为一张“未知的面孔”。我们的Python人脸聚类算法很好地完成了对图像的聚类,只是对这个人脸图像进行了错误的聚类。
在我们数据集中的5个人的129张图像中,只有一张脸没有被分组到现有的簇中。
我们的无监督学习DBSCAN方法生成了五个簇。不幸的是,梅西有一个图片并没有与他的其他图片放在一起,但整体来说这种方法效果不错。
更多图像识别数据集下载“点击”这里

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
一文搞懂什么是效应量度量








广告


写评论取消
回复取消