











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI提出比GAN更具优势的可逆生成模型Glow
2018年07月10日 由 浅浅 发表
983534
0

Glow,一种使用可逆1x1卷积的可逆生成模型。它扩展了以前的可逆生成模型,简化了架构。模型可以生成逼真的高分辨率图像,支持高效采样,并发现可用于操纵数据属性的功能。我们正在发布模型代码和在线可视化工具,以便人们可以探索并构建这些结果。另外,网站上也可以进行交互性操作。
动机
[video width="1024" height="1024" mp4="https://www.atyun.com/uploadfile/2018/07/both_loop_new.mp4"][/video]
研究人员Prafulla Dhariwal和Durk Kingma的图像属性操作。该模型在训练时没有给出属性标签,但它学习了一个潜在空间,其中某些方向对应于胡须密度,年龄,头发颜色等属性的变化。
生成建模就是观察数据,如一组面部图片,然后学习如何生成这些数据的模型。学习近似数据生成过程需要学习数据中存在的所有结构,并且成功的模型应该能够合成看起来类似于数据的输出。准确的生成模型具有广泛的应用,包括语音合成,文本分析和综合,半监督学习和基于模型的控制。我们提出的技术也可以应用于这些问题。
Glow是一种可逆的生成模型,也称为基于流的生成模型,是NICE和RealNVP技术的扩展。与GAN和VAE相比,基于流的生成模型迄今为止在研究界很少受到关注。
基于流的生成模型的一些优点包括:
- 精确的潜变量推断和对数似然评估。在VAE中,人们只能推断出与数据点相对应的潜在变量的值。GAN根本没有编码器来推断潜伏者。在可逆的生成模型中,这可以在没有近似的情况下完全完成。这不仅可以实现准确的推理,还可以优化数据的精确对数似然,而不是其下限。
- 高效的推理和有效的合成。自回归模型,例如PixelCNN,也是可逆的,但是来自这些模型的合成难以并行化,并且通常在并行硬件上效率低。基于流的生成模型(如Glow(和RealNVP))可以有效地进行推理和合成的并行化。
- 对下游任务有用的潜在空间。自回归模型的隐藏层具有未知的边际分布,使得执行有效的数据操作变得更加困难。在GAN中,数据点通常不能直接在潜在空间中表示,因为它们没有编码器,并且可能无法支持全部的数据分布。对于可逆生成模型和VAE而言,情况并非如此,后者允许各种应用,例如数据点之间的插值和现有数据点的有意义修改。
- 节省内存的巨大潜力。如RevNet论文所述,在可逆神经网络中计算梯度需要一定量的内存,而不是线性的深度。
结果
我们的技术与RealNVP相比,我们在标准基准测试中取得了显着的改进,RealNVP是以前基于流量的生成模型的最佳公布结果。
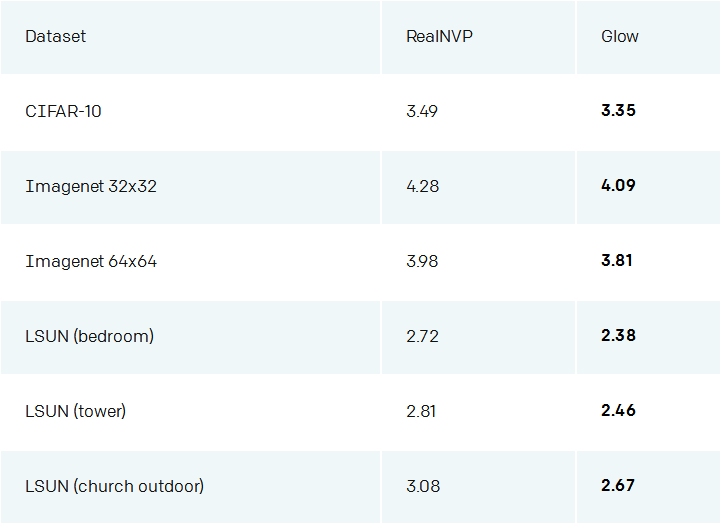
RealNVP模型与我们的Glow模型在各种数据集的测试集上,评估bits per dimension定量性能。
[video width="2048" height="1024" mp4="https://www.atyun.com/uploadfile/2018/07/samples.mp4"][/video]
在对30,000个高分辨率面部的数据集进行训练后,我们模型中的样本。
Glow模型可以生成逼真的高分辨率图像,并且很高效。我们的模型需要大约130ms才能在NVIDIA 1080 Ti GPU上生成256 x 256样本。与之前的工作一样,我们发现从降低温度模型中取样通常会产生更高质量的样品。上述样品就是通过将潜伏的标准偏差缩放0.7的温度获得的。
潜在空间的插值
我们还可以在任意人脸之间进行插值,使用编码器对两个图像进行编码并从中间点进行采样。请注意,输入是任意人脸,而不是模型中的样本,因此模型支持整个目标分布。
[video width="1024" height="1024" mp4="https://www.atyun.com/uploadfile/2018/07/prafulla_people_loop.mp4"][/video]
Prafulla的脸与名人的脸进行插值。
在潜在空间中操纵
我们可以在没有标签的情况下训练基于流的模型,然后将学习的潜在表示用于下游任务,例如操纵输入的属性。这些语义属性可以是面部中的头发颜色,图像的样式,音乐声音的音调或文本句子的情感。由于基于流的模型具有完美的编码器,因此可以对输入进行编码并计算具有或不具有属性的输入的平均潜在向量。然后可以使用两者之间的矢量方向来操纵朝向该属性的任意输入。
上述过程需要相对少量的标记数据,并且可以在模型训练完成后完成(训练时不需要标签)。以前使用GAN的工作需要单独训练编码器。用 VAE的方法只能保证解码器和编码兼容数据分布。其他方法涉及直接学习表示变换的函数,如Cycle-GAN,但是它们需要对每次变换进行重新训练。
# Train flow model on large, unlabelled dataset X
m = train(X_unlabelled)
# Split labelled dataset based on attribute, say blonde hair
X_positive, X_negative = split(X_labelled)
# Obtain average encodings of positive and negative inputs
z_positive = average([m.encode(x) for x in X_positive])
z_negative = average([m.encode(x) for x in X_negative])
# Get manipulation vector by taking difference
z_manipulate = z_positive - z_negative
# Manipulate new x_input along z_manipulate, by a scalar alpha \in [-1,1]
z_input = m.encode(x_input)
x_manipulated = m.decode(z_input + alpha * z_manipulate)
简单的代码片段,用于使用基于流的模型来操作属性。
贡献
我们的主要贡献是增加了可逆的1x1卷积,以及删除其他组件,从而简化了整体架构。
RealNVP架构由两种类型的层组成:具有棋盘屏蔽的层和具有通道屏蔽的层。我们使用棋盘屏蔽删除图层,简化了体系结构。具有通道屏蔽功能的层执行相当于以下步骤的重复:
- 通过在通道维度上反转它们的顺序来置换输入。
- 将输入分为A和B两部分,位于要素尺寸的中间。
- 将A馈入浅卷积神经网络。根据神经网络的输出将B线性变换。
- 连接A和B。
通过链接这些层,A更新B,然后B更新A,然后A再更新B……这种双向信息流显然非常严格。我们发现通过将步骤(1)的反向排列改变为(固定的)混洗排列来改善模型性能。
更进一步,我们也可以学习最优排列。学习置换矩阵是一种离散优化,不能修改为梯度上升。但由于置换操作只是使用方阵进行线性变换的一种特殊情况,我们可以使用卷积神经网络,因为置换通道相当于具有相同数量输入和输出通道的1x1卷积运算。因此,我们用学习的1x1卷积运算替换固定排列。1x1卷积的权重被初始化为随机旋转矩阵。如下图所示,此操作可带来显着的建模改进。我们还表明,通过权重的LU分解可以有效地完成优化目标函数所涉及的计算。
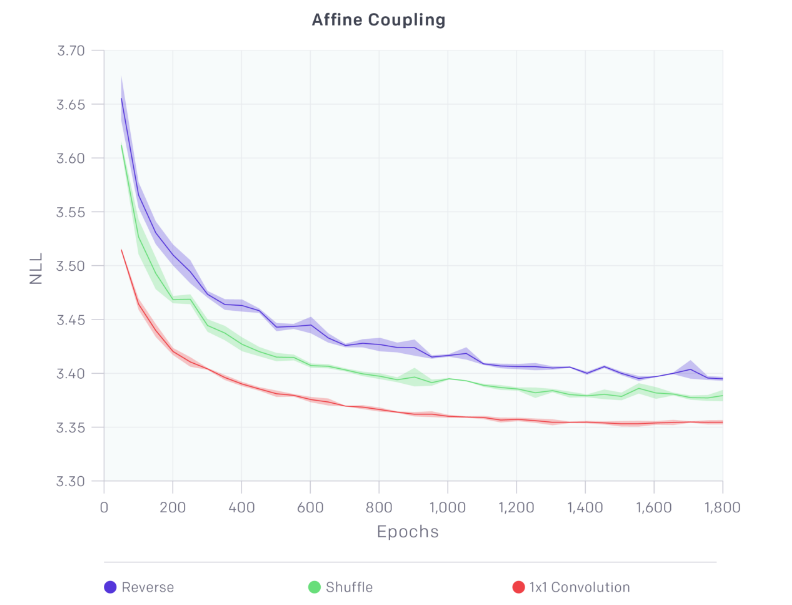
我们的主要贡献是可逆的1x1卷积,可以带来显着的建模改进。
此外,我们删除批量标准化并将其替换为激活标准化层。该层简单地移动和缩放激活,具有依赖于数据的初始化,该初始化在给定初始小批量数据的情况下规范化激活。这允许将小批量大小缩小到1(对于大图像)并扩大模型的大小。
规模
我们的架构结合各种优化,例如梯度检查点,使我们能够比平常更大规模地训练基于流的生成模型。我们使用Horovod在多台机器的集群上轻松训练我们的模型; 我们演示中使用的模型在5台机器上进行了培训,每台8个GPU。使用此设置,可以训练具有超过一亿个参数的模型。
研究方向
我们的工作表明,可以训练基于流量的模型来生成逼真的高分辨率图像,并学习可以轻松用于下游任务(如数据操作)的潜在表征。
未来工作的几个方向:
- 在似然函数方面与其他模型类别竞争。自回归模型和VAE在对数似然性方面比基于流量的模型表现更好,但它们分别具有低效采样和不精确推理的缺点。人们可以将基于流量的模型,VAE和自回归模型结合起来,这将是未来工作的一个有趣方向。
- 改进架构以提高计算效率和参数效率。为了生成逼真的高分辨率图像,面部生成模型使用2亿个参数和600个卷积层,这使得训练成本高昂。较浅的模型在学习远程依赖性方面表现较差。使用自注意架构或执行渐进式训练以扩展到高分辨率可以使得训练Glow模型的计算成本更低。
论文:d4mucfpksywv.cloudfront.net/research-covers/glow/paper/glow.pdf
代码:github.com/openai/glow

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消