











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






face-api.js中加入MTCNN:进一步支持使用JS实时进行人脸跟踪和识别
2018年07月20日 由 yuxiangyu 发表
22614
0
如果你现在正在阅读这篇文章,那么你可能已经阅读了我的介绍文章(JS使用者福音:在浏览器中运行人脸识别)或者之前使用过face-api.js。如果你还没有听说过face-api.js,我建议你先阅读介绍文章再回来阅读本文。
和往常一样,本文中为你准备了一个代码示例。我们将解析一个小的应用程序,这个程序将在浏览器中访问摄像头图像执行实时人脸检测和人脸识别,让我们开始吧!
到目前为止,face-api.js单独实现了基于SSD Mobilenet v1的CNN进行人脸检测。虽然这个是一个非常精确的人脸检测器,但SSD并不像其他架构那么快(在推理时间方面),并且可能无法通过这个人脸检测器实现实时检测,除非你或者你的用户在他们的机器中内置了一个不错的GPU。
事实证明,你并不总是需要那么高的准确度,有时候你会宁愿用高精度换取更快的人脸检测器。
所以我们要用到MTCNN,它现在可以在face-ap .js中使用了!MTCNN是一种更轻量级的面部检测器。与SSD Mobilenet v1相比:
MTCNN(Multi-task Cascaded Convolutional Neural Networks)是一种由3个阶段组成的算法,它可以检测图像中人脸的边界框以及它们的5个点的面部地标。每个阶段通过将其输入通过CNN逐步改善检测结果,CNN返回具有其分数的候选边界框,然后是非最大抑制。
论文:https://kpzhang93.github.io/MTCNN_face_detection_alignment/paper/spl.pdf
在阶段1中,输入图像被缩放多次以构建影像金字塔,并且图像的每个缩放版本都通过其CNN传递。在第2阶段和第3阶段,我们为每个边界框提取图像块并调整它们的大小(第2阶段为24x24,第3 阶段为48x48),然后通过该阶段的CNN传递它们。除了边界框和分数之外,阶段3还为每个边界框计算5个面部地标点。
在修改了一些MTCNN实现之后,结果表明,与SSD Mobilenet v1相比,即使在CPU上运行推断,也可以在更低的推断时间获得相当可靠的检测结果。并且,从5个面部地标点中,我们可以免费获得面部对齐!这样,在计算面部描述符之前,我们不必执行68点面部地标检测作为中间步骤。
尽管在我看来这很有前景,我还是继续在tfjs-core中实现了这一点。经过几天的努力,我终于能够找到一个有效的解决方案。
如前所述,我们现在将看看如何使用摄像头实现人脸跟踪和人脸识别。在这个例子中,我会使用我的摄像头再次跟踪和识别一些《生活大爆炸》主角的脸,但当然你可以使用这些代码来跟踪和识别自己。
要显示网络摄像头中的帧,只需使用如下视频元素即可。此外,我将一个绝对定位的画布放在视频元素的顶部,具有相同的高度和宽度。我们将使用画布作为透明的叠加层,稍后我们可以在上面绘制检测结果:
加载页面后,我们将加载MTCNN模型和人脸识别模型,以计算面部描述符。此外,我们使用navigator.getUserMedia将我们的摄像头流附加到视频元素:
现在程序应该会请求授予浏览器访问摄像头的权限。在我们为视频元素指定的onPlay回调中,我们将处理每个帧的实际加工。注意,一旦视频开始播放,就会触发onplay事件。
正如我所说,我们可以在这里配置一些检测参数。默认参数:
要跟踪摄像头中的人脸,我们会将minFaceSize增加到至少200px。仅检测较大尺寸的人脸使我们获得更短的推理时间,因为网络将图像缩小的系数更大:
如你所见,我们可以简单地将视频元素提供给它,就像图像或画布元素那样。
通过MTCNN前向传递给我们一个FaceDetection数组(边界框+得分)以及每个检测到的人脸的FaceLandmark5。现在我们可以将结果绘制到叠加层上:
例子如下,到目前为止,我们将得到下面的结论:
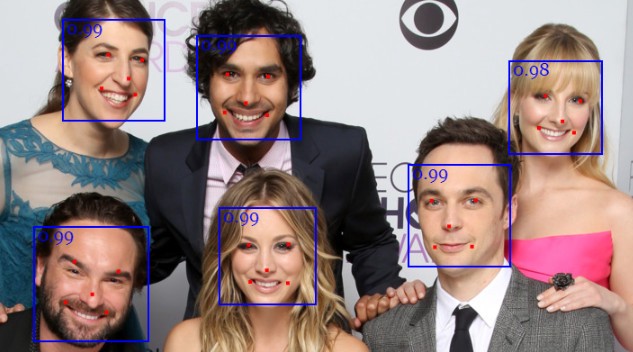
从我之前的教程中你应该已经知道,在计算任何面部描述符之前,我们需要将人脸地标的位置与人脸边界框的位置对其。从对齐的框中,我们提取对齐的通过人脸识别网络传递的面部张量:
如果你觉得这样做很麻烦,代码太多,还有一个方便快捷的函数—faceapi.allFacesMtcnn。它可以检测图像中所有人脸并计算它们的描述符(类似于faceapi.allFaces):
从现在开始,我们只需按照上一个教程中的方式进行操作。回想一下,为了识别人脸,在运行主循环之前,我们必须为每个我们想要识别(参考数据)的人的示例图像预先计算一个(至少一个)面部描述符。为了做出决策,是哪一个人坐在摄像头前面,我们将在参考数据中的面部描述符中查询人脸描述符并返回最相似的匹配:
如果你只想跟踪自己,只需自拍一张然后运行faceapi.allFaces就可以检索自己脸部的面部描述符(参考描述符)。然后,可以使用faceapi.euclideanDistance直接计算查询面部描述符的距离(从你的摄像头图像到参考描述符)。
最后,我们将带有预测标签的文本和相对于边界框位置的距离再次绘制到覆盖层画布上:
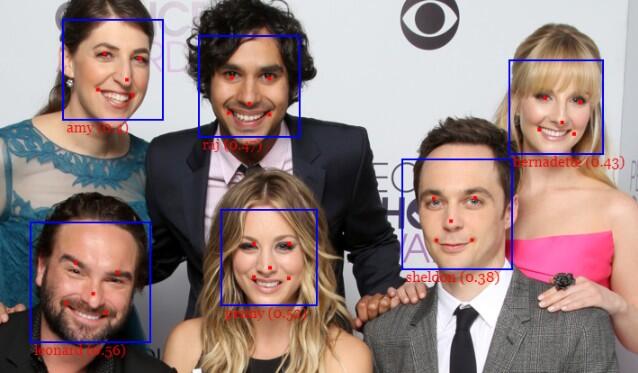
然后,不要忘记调用onPlay继续迭代处理最近的帧。就是这些!
最后要注意的是,为每一帧重新计算查询面部描述符是一种非常幼稚的方法。显然,有更有效的方法,例如每隔x帧跟踪和更新检测结果的面部描述符。通常,被跟踪的人脸的姿势不会在几帧中有剧烈地改变。但为了简单起见,这样就可以了。如果你想要从中挤出更多的fps,可以利用这一点。
示例的完整源代码:https://github.com/justadudewhohacks/face-api.js/blob/master/examples/views/mtcnnFaceRecognitionWebcam.html
和往常一样,本文中为你准备了一个代码示例。我们将解析一个小的应用程序,这个程序将在浏览器中访问摄像头图像执行实时人脸检测和人脸识别,让我们开始吧!
使用face-api.js进行人脸检测
到目前为止,face-api.js单独实现了基于SSD Mobilenet v1的CNN进行人脸检测。虽然这个是一个非常精确的人脸检测器,但SSD并不像其他架构那么快(在推理时间方面),并且可能无法通过这个人脸检测器实现实时检测,除非你或者你的用户在他们的机器中内置了一个不错的GPU。
事实证明,你并不总是需要那么高的准确度,有时候你会宁愿用高精度换取更快的人脸检测器。
所以我们要用到MTCNN,它现在可以在face-ap .js中使用了!MTCNN是一种更轻量级的面部检测器。与SSD Mobilenet v1相比:
优点:
- 更短的推理时间(更快的检测速度)
- 同时检测5个面部标志点(我们“免费”获得人脸对齐)
- 模型更小:相比对于6MB(量化的SSD Mobilenet v1权重)来说,它仅约2MB
- 可配置性:你可以调整一些参数以提高性能以满足你的特定要求
缺点:
- 不如SSD Mobilenet v1准确
MTCNN - 同时进行人脸检测和面部地标
MTCNN(Multi-task Cascaded Convolutional Neural Networks)是一种由3个阶段组成的算法,它可以检测图像中人脸的边界框以及它们的5个点的面部地标。每个阶段通过将其输入通过CNN逐步改善检测结果,CNN返回具有其分数的候选边界框,然后是非最大抑制。
论文:https://kpzhang93.github.io/MTCNN_face_detection_alignment/paper/spl.pdf
在阶段1中,输入图像被缩放多次以构建影像金字塔,并且图像的每个缩放版本都通过其CNN传递。在第2阶段和第3阶段,我们为每个边界框提取图像块并调整它们的大小(第2阶段为24x24,第3 阶段为48x48),然后通过该阶段的CNN传递它们。除了边界框和分数之外,阶段3还为每个边界框计算5个面部地标点。
在修改了一些MTCNN实现之后,结果表明,与SSD Mobilenet v1相比,即使在CPU上运行推断,也可以在更低的推断时间获得相当可靠的检测结果。并且,从5个面部地标点中,我们可以免费获得面部对齐!这样,在计算面部描述符之前,我们不必执行68点面部地标检测作为中间步骤。
尽管在我看来这很有前景,我还是继续在tfjs-core中实现了这一点。经过几天的努力,我终于能够找到一个有效的解决方案。
摄像头人脸跟踪和人脸识别
如前所述,我们现在将看看如何使用摄像头实现人脸跟踪和人脸识别。在这个例子中,我会使用我的摄像头再次跟踪和识别一些《生活大爆炸》主角的脸,但当然你可以使用这些代码来跟踪和识别自己。
要显示网络摄像头中的帧,只需使用如下视频元素即可。此外,我将一个绝对定位的画布放在视频元素的顶部,具有相同的高度和宽度。我们将使用画布作为透明的叠加层,稍后我们可以在上面绘制检测结果:
加载页面后,我们将加载MTCNN模型和人脸识别模型,以计算面部描述符。此外,我们使用navigator.getUserMedia将我们的摄像头流附加到视频元素:
$(document).ready(function() {
run()
})
async function run() {
// load the models
await faceapi.loadMtcnnModel('/')
await faceapi.loadFaceRecognitionModel('/')
// try to access users webcam and stream the images
// to the video element
const videoEl = document.getElementById('inputVideo')
navigator.getUserMedia(
{ video: {} },
stream => videoEl.srcObject = stream,
err => console.error(err)
)
}现在程序应该会请求授予浏览器访问摄像头的权限。在我们为视频元素指定的onPlay回调中,我们将处理每个帧的实际加工。注意,一旦视频开始播放,就会触发onplay事件。
人脸检测
正如我所说,我们可以在这里配置一些检测参数。默认参数:
const mtcnnForwardParams = {
// number of scaled versions of the input image passed through the CNN
// of the first stage, lower numbers will result in lower inference time,
// but will also be less accurate
maxNumScales: 10,
// scale factor used to calculate the scale steps of the image
// pyramid used in stage 1
scaleFactor: 0.709,
// the score threshold values used to filter the bounding
// boxes of stage 1, 2 and 3
scoreThresholds: [0.6, 0.7, 0.7],
// mininum face size to expect, the higher the faster processing will be,
// but smaller faces won't be detected
minFaceSize: 20
}要跟踪摄像头中的人脸,我们会将minFaceSize增加到至少200px。仅检测较大尺寸的人脸使我们获得更短的推理时间,因为网络将图像缩小的系数更大:
const mtcnnForwardParams = {
// limiting the search space to larger faces for webcam detection
minFaceSize: 200
}
const mtcnnResults = await faceapi.mtcnn(document.getElementById('inputVideo'), mtcnnForwardParams)如你所见,我们可以简单地将视频元素提供给它,就像图像或画布元素那样。
通过MTCNN前向传递给我们一个FaceDetection数组(边界框+得分)以及每个检测到的人脸的FaceLandmark5。现在我们可以将结果绘制到叠加层上:
faceapi.drawDetection('overlay', mtcnnResults.map(res => res.faceDetection), { withScore: false })
faceapi.drawLandmarks('overlay', mtcnnResults.map(res => res.faceLandmarks), { lineWidth: 4, color: 'red' })例子如下,到目前为止,我们将得到下面的结论:
计算人脸描述符
从我之前的教程中你应该已经知道,在计算任何面部描述符之前,我们需要将人脸地标的位置与人脸边界框的位置对其。从对齐的框中,我们提取对齐的通过人脸识别网络传递的面部张量:
const alignedFaceBoxes = results.map(
({ faceLandmarks }) => faceLandmarks.align()
)
const alignedFaceTensors = await extractFaceTensors(input, alignedFaceBoxes)
const descriptors = await Promise.all(alignedFaceTensors.map(
faceTensor => faceapi.computeFaceDescriptor(faceTensor)
))
// free memory
alignedFaceTensors.forEach(t => t.dispose())
如果你觉得这样做很麻烦,代码太多,还有一个方便快捷的函数—faceapi.allFacesMtcnn。它可以检测图像中所有人脸并计算它们的描述符(类似于faceapi.allFaces):
const fullFaceDescriptions = await faceapi.allFacesMtcnn(document.getElementById('inputVideo'), mtcnnParams)
// fullFaceDescriptions[0].detection
// fullFaceDescriptions[0].landmarks
// fullFaceDescriptions[0].descriptor人脸识别
从现在开始,我们只需按照上一个教程中的方式进行操作。回想一下,为了识别人脸,在运行主循环之前,我们必须为每个我们想要识别(参考数据)的人的示例图像预先计算一个(至少一个)面部描述符。为了做出决策,是哪一个人坐在摄像头前面,我们将在参考数据中的面部描述符中查询人脸描述符并返回最相似的匹配:
const sortAsc = (a, b) => a - b
const results = fullFaceDescriptions.map((fd) => {
const bestMatch = refDescriptors.map(
({ descriptor, label }) => ({
label,
distance: faceapi.euclideanDistance(fd.descriptor, descriptor)
})
).sort(sortAsc)[0]
return {
detection: fd.detection,
label: bestMatch.label,
distance: bestMatch.distance
}
})
如果你只想跟踪自己,只需自拍一张然后运行faceapi.allFaces就可以检索自己脸部的面部描述符(参考描述符)。然后,可以使用faceapi.euclideanDistance直接计算查询面部描述符的距离(从你的摄像头图像到参考描述符)。
最后,我们将带有预测标签的文本和相对于边界框位置的距离再次绘制到覆盖层画布上:
// 0.6 is a good distance threshold value to judge
// whether the descriptors match or not
const maxDistance = 0.6
results.forEach(result => {
faceapi.drawDetection(canvas, result.detection, { withScore: false })
const text = `${result.distance < maxDistance ? result.className : 'unknown'} (${result.distance})`
const { x, y, height: boxHeight } = detection.getBox()
faceapi.drawText(
canvas.getContext('2d'),
x,
y + boxHeight,
text
)
})
然后,不要忘记调用onPlay继续迭代处理最近的帧。就是这些!
结语
最后要注意的是,为每一帧重新计算查询面部描述符是一种非常幼稚的方法。显然,有更有效的方法,例如每隔x帧跟踪和更新检测结果的面部描述符。通常,被跟踪的人脸的姿势不会在几帧中有剧烈地改变。但为了简单起见,这样就可以了。如果你想要从中挤出更多的fps,可以利用这一点。
示例的完整源代码:https://github.com/justadudewhohacks/face-api.js/blob/master/examples/views/mtcnnFaceRecognitionWebcam.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消