











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用不确定性来解释和调试你的深度学习模型
2018年08月01日 由 yuxiangyu 发表
194281
0
随着深度神经网络(DNN)变得越来越强大,它们的复杂性也会增加。这种复杂性带来了新的挑战,包括模型的可解释性。
可解释性对于构建更强大且能抵抗对抗攻击的模型至关重要。此外,为一个新的,未经过深入研究的领域设计模型具有挑战性,而能够解释模型正在做什么可以帮助我们完成这个过程。
模特可解释性的重要性使研究人员开发出多种方法,并在去年的NIPS会议上专门讨论了这个主题。这些方法包括:
在我们深入研究如何使用不确定性来调试和解释模型之前,首先让我们了解为什么不确定性很重要。
比较典型的例子是高风险应用。假设你正在建立一个模型,帮助医生决定患者的首选治疗方案。在这种情况下,我们不仅要关心模型的准确性,还要关注模型对预测的确定程度。如果不确定性太高,医生应该将此考虑在内。
自驾车也是一个例子。当模型不确定道路上是否有行人时,我们可以使用此信息来减慢车速或触发警报,以使驾驶员接手。
不确定性也可以帮助我们摆脱数据实例。如果模型没有使用类似于手边样本的实例进行训练,那么如果它能够说“抱歉,我不知道”可能会更好。这可以避免谷歌在将非洲裔美国人误认为大猩猩时这样的尴尬错误。这种错误有时是由于训练集不够多样化产生的。
最后一次使用不确定性(也是本文的目标),是从业者调试模型的工具。我们稍后会深入研究这个问题,但首先,让我们谈谈不同类型的不确定性。
有不同类型的不确定性和建模,每种都有用于不同的目的。
模型不确定性,AKA认知不确定性:假设有一个数据点,想知道哪种线性模型最能解释您的数据。没有好的方法可以在图片中不同的线之间进行选择 - 我们需要更多数据!
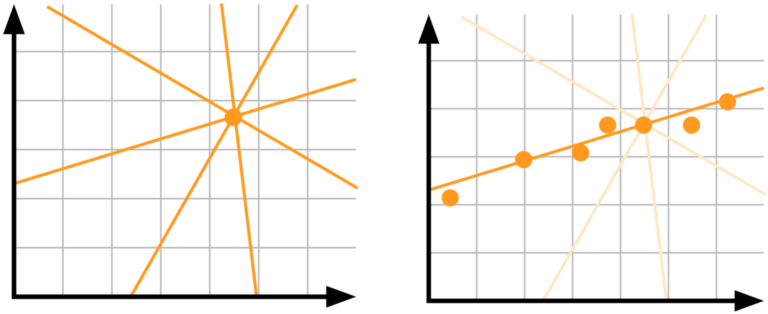

举个例子,假设你想要建立一个能够获得动物图片的模型,并预测该动物是否会尝试吃掉你。假设你用狮子和长颈鹿的图片训练模型,现在它看到了一个僵尸。由于该模型没有在僵尸图片上进行过训练,因此不确定性很高。这种不确定性就是模型的结果,如果给出僵尸图片够多,不确定性就会减少。
数据不确定性,或者说偶发不确定性捕获观察中固有的噪声。有时世界本身就是随机的。在这种情况下,获取更多数据对我们没有帮助,因为噪声是数据固有的。
要理解这一点,让我们继续思考食肉动物模型。我们的模型可以识别图像中有狮子,因此你可能会被吃掉。但是,如果狮子现在不饿了怎么办?这种不确定性来自数据。另外,两条看起来相同的蛇,但其中一条是可能有毒,另一条则没有。
偶发不确定性分为两种类型:
测量的不确定性:另一个不确定性来源是测量本身。当测量结果有噪声时,不确定性会增加。在动物示例中,如果使用质量差的相机拍摄照片,则可能会损害模型的置信度;或者如果我们正逃离一只发狂的河马,我们只能处理模糊的图像。
有噪声的标签:通过监督学习,我们使用标签来训练模型。如果标签有噪音,则不确定性会增加。
有各种方法来模拟每种不确定性。这些我以后会介绍。现在,让我们假设我们有一个黑盒模型,它暴露了对预测的不确定性。我们如何使用它来调试模型?
让我们思考Taboola中的一个模型,它被用于预测用户点击内容推荐的可能性,也称为CTR(Click Through Rate)。
该模型具有许多由嵌入向量表示的分类特征。它可能难以学习稀有值的通用嵌入。解决此问题的常用方法是使用特殊的OOV(Out of Vocabulary)嵌入。
想想某个物品的广告商。所有罕见的广告商都共享相同的OOV嵌入,因此,从模型的角度来看,他们本质上就是一个广告商。这个OOV广告商有许多不同的商品,每个商品都有不同的CTR。如果我们仅使用广告商作为CTR的预测,我们就会得到OOV的高不确定性。
为了验证模型对OOV输出的高不确定性,我们取一个验证集,并转换所有广告商嵌入到OOV。接下来,我们检查了转换前后的不确定性。正如预期的那样,不确定性增加了。该模型能够了解到,如果给予信息丰富的广告商,它应该减少不确定性。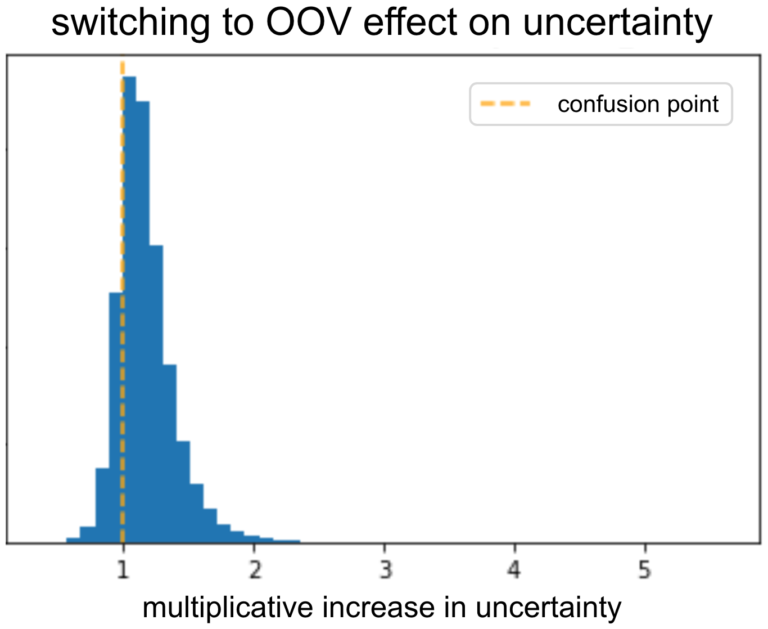
我们可以针对不同的特征重复这一点,并寻找在被OOV嵌入替换时导致低不确定性的特征。这些特征要么是无信息性的,要么是我们将它们提供给模型的方式并不理想。
我们甚至可以继续细分:某些广告商在不同商品的CTR之间存在较高的可变性,而另一些则有大致相同的CTR。我们希望该模型对第一类广告商具有更高的不确定性。因此,比较有用的分析是关注广告商中不确定性和CTR变异性之间的相关性。如果相关性不是正的,则意味着模型未能了解与每个广告商相关的不确定性。这个工具允许我们了解训练过程或模型架构中是否出现问题,这表明我们应该进一步调试它。
我们可以执行类似的分析,看看与特定项目相关的不确定性是否会减少了更多的我们展示它的次数(即向更多用户或更多地方显示)。同样,我们希望模型变得更加确定,如果不是 - 我们将进行调试!
另一个很酷的例子是标题特征:带有罕见词汇的独特标题应该会带来很高的模型不确定性。这是模型没有从那个领域所有可能标题看到很多例子的结果。然后我们使用其中一种标题对模型进行再训练,看看是否降低了整体的不确定性。然后我们将使用其中一个标题重新训练模型,并查看整个组的不确定性是否已降低。我们可以看到发生了什么:
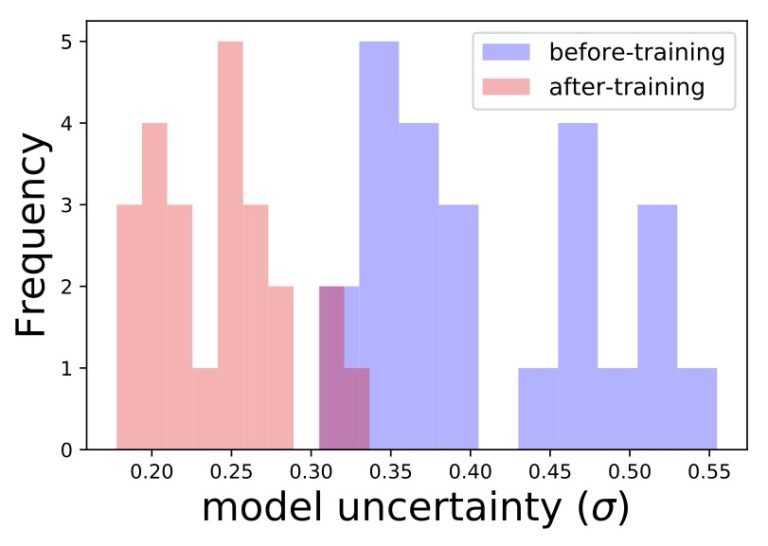
等一下......通过将模型暴露给某些标题,它能够变得更好,对一些新标题更加确定。也许我们可以用它来某种方式鼓励探索新的物品?是的,我们可以(我们后续会出)!
不确定性在许多领域都很重要。确定哪种不确定性类型更重要要根据特定的应用。一旦你了解了如何建模,就可以通过各种方式使用它们。在这篇文章中,我们讨论了如何使用它们来调试模型。在下一篇文章中,我们将讨论从模型中获得不确定性估计的不同方法。
可解释性对于构建更强大且能抵抗对抗攻击的模型至关重要。此外,为一个新的,未经过深入研究的领域设计模型具有挑战性,而能够解释模型正在做什么可以帮助我们完成这个过程。
模特可解释性的重要性使研究人员开发出多种方法,并在去年的NIPS会议上专门讨论了这个主题。这些方法包括:
- LIME:通过局部线性逼近解释模型预测的方法(https://arxiv.org/abs/1602.04938)
- 激活最大化:了解哪种输入模式产生最大的模型响应(https://pdfs.semanticscholar.org/65d9/94fb778a8d9e0f632659fb33a082949a50d3.pdf)
- 特征可视化:(https://distill.pub/2017/feature-visualization/)
- 将DNN层嵌入到低维可解释的空间中:(http://www.interpretable-ml.org/nips2017workshop/papers/04.pdf)
- 采用认知心理学的方法:(https://deepmind.com/blog/cognitive-psychology/)
- 不确定性估计方法
在我们深入研究如何使用不确定性来调试和解释模型之前,首先让我们了解为什么不确定性很重要。
为什么要关心不确定性?
比较典型的例子是高风险应用。假设你正在建立一个模型,帮助医生决定患者的首选治疗方案。在这种情况下,我们不仅要关心模型的准确性,还要关注模型对预测的确定程度。如果不确定性太高,医生应该将此考虑在内。
自驾车也是一个例子。当模型不确定道路上是否有行人时,我们可以使用此信息来减慢车速或触发警报,以使驾驶员接手。
不确定性也可以帮助我们摆脱数据实例。如果模型没有使用类似于手边样本的实例进行训练,那么如果它能够说“抱歉,我不知道”可能会更好。这可以避免谷歌在将非洲裔美国人误认为大猩猩时这样的尴尬错误。这种错误有时是由于训练集不够多样化产生的。
最后一次使用不确定性(也是本文的目标),是从业者调试模型的工具。我们稍后会深入研究这个问题,但首先,让我们谈谈不同类型的不确定性。
不确定性类型
有不同类型的不确定性和建模,每种都有用于不同的目的。
模型不确定性,AKA认知不确定性:假设有一个数据点,想知道哪种线性模型最能解释您的数据。没有好的方法可以在图片中不同的线之间进行选择 - 我们需要更多数据!
左侧:没有足够的数据导致高度不确定性。右边:给定更多数据不确定性降低
认知不确定性解释模型参数的不确定性。我们不确定哪种模型权重最好地描述数据,但是给定更多数据我们的不确定性会降低。这种不确定性在高风险应用和处理小型稀疏数据时非常重要。
举个例子,假设你想要建立一个能够获得动物图片的模型,并预测该动物是否会尝试吃掉你。假设你用狮子和长颈鹿的图片训练模型,现在它看到了一个僵尸。由于该模型没有在僵尸图片上进行过训练,因此不确定性很高。这种不确定性就是模型的结果,如果给出僵尸图片够多,不确定性就会减少。
数据不确定性,或者说偶发不确定性捕获观察中固有的噪声。有时世界本身就是随机的。在这种情况下,获取更多数据对我们没有帮助,因为噪声是数据固有的。
要理解这一点,让我们继续思考食肉动物模型。我们的模型可以识别图像中有狮子,因此你可能会被吃掉。但是,如果狮子现在不饿了怎么办?这种不确定性来自数据。另外,两条看起来相同的蛇,但其中一条是可能有毒,另一条则没有。
偶发不确定性分为两种类型:
- 同理不确定性:所有输入的不确定性都是相同的。
- 异方差的不确定性:不确定性取决于目前的具体输入。例如,对于预测图像“深度”的模型,预测无特征墙比具有强消失线的图像更高的不确定性。
测量的不确定性:另一个不确定性来源是测量本身。当测量结果有噪声时,不确定性会增加。在动物示例中,如果使用质量差的相机拍摄照片,则可能会损害模型的置信度;或者如果我们正逃离一只发狂的河马,我们只能处理模糊的图像。
有噪声的标签:通过监督学习,我们使用标签来训练模型。如果标签有噪音,则不确定性会增加。
有各种方法来模拟每种不确定性。这些我以后会介绍。现在,让我们假设我们有一个黑盒模型,它暴露了对预测的不确定性。我们如何使用它来调试模型?
让我们思考Taboola中的一个模型,它被用于预测用户点击内容推荐的可能性,也称为CTR(Click Through Rate)。
使用不确定性来调试模型
该模型具有许多由嵌入向量表示的分类特征。它可能难以学习稀有值的通用嵌入。解决此问题的常用方法是使用特殊的OOV(Out of Vocabulary)嵌入。
想想某个物品的广告商。所有罕见的广告商都共享相同的OOV嵌入,因此,从模型的角度来看,他们本质上就是一个广告商。这个OOV广告商有许多不同的商品,每个商品都有不同的CTR。如果我们仅使用广告商作为CTR的预测,我们就会得到OOV的高不确定性。
为了验证模型对OOV输出的高不确定性,我们取一个验证集,并转换所有广告商嵌入到OOV。接下来,我们检查了转换前后的不确定性。正如预期的那样,不确定性增加了。该模型能够了解到,如果给予信息丰富的广告商,它应该减少不确定性。
我们可以针对不同的特征重复这一点,并寻找在被OOV嵌入替换时导致低不确定性的特征。这些特征要么是无信息性的,要么是我们将它们提供给模型的方式并不理想。
我们甚至可以继续细分:某些广告商在不同商品的CTR之间存在较高的可变性,而另一些则有大致相同的CTR。我们希望该模型对第一类广告商具有更高的不确定性。因此,比较有用的分析是关注广告商中不确定性和CTR变异性之间的相关性。如果相关性不是正的,则意味着模型未能了解与每个广告商相关的不确定性。这个工具允许我们了解训练过程或模型架构中是否出现问题,这表明我们应该进一步调试它。
我们可以执行类似的分析,看看与特定项目相关的不确定性是否会减少了更多的我们展示它的次数(即向更多用户或更多地方显示)。同样,我们希望模型变得更加确定,如果不是 - 我们将进行调试!
另一个很酷的例子是标题特征:带有罕见词汇的独特标题应该会带来很高的模型不确定性。这是模型没有从那个领域所有可能标题看到很多例子的结果。然后我们使用其中一种标题对模型进行再训练,看看是否降低了整体的不确定性。然后我们将使用其中一个标题重新训练模型,并查看整个组的不确定性是否已降低。我们可以看到发生了什么:
等一下......通过将模型暴露给某些标题,它能够变得更好,对一些新标题更加确定。也许我们可以用它来某种方式鼓励探索新的物品?是的,我们可以(我们后续会出)!
结语
不确定性在许多领域都很重要。确定哪种不确定性类型更重要要根据特定的应用。一旦你了解了如何建模,就可以通过各种方式使用它们。在这篇文章中,我们讨论了如何使用它们来调试模型。在下一篇文章中,我们将讨论从模型中获得不确定性估计的不同方法。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
如何配置神经网络中的层数和节点数








广告


写评论取消
回复取消