











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






思必驰钱彦旻:语音识别发展现状(干货)
2016年12月08日 由 荟荟 发表
798939
0
智能语音交互的发展现状
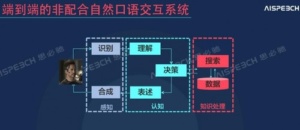
随着移动互联网和人工智能的发展,基于语音的交互已经越来越重要、也越来越普及。下面这张图中展示的是一个智能语音交互闭环的系统,包括前端的感知层面,也就是语音识别和语音合成,以及后端的理解决策层面,包括理解、决策、表述等各个模块。我们可以看到,在整个闭环系统中,语音识别作为整个闭环的入口,性能的好坏直接决定整个智能语音交互系统的用户满意度,其重要性可想而知。
过去三个月,在语音识别领域有几个大新闻:一个是今年10月,美国微软雷德蒙研究院在电话语音识别的标准库Switchboard上报道达到5.9%的错误率,我们要知道,在这个库上人类也只能达到大概5.9%,而机器的性能已经和人类基本达到了持平;第二个新闻是在今年9月,也就是国际语音通信联合会的最后一天报道的CHIME4国际多通道语音分离和识别大赛,你可以简单认为这是一个在限定词表和场景下的带噪的语音识别挑战赛,最好的系统性能报道达到了将近2%的错误率;第三个新闻可能大家更关心,是关于中文的,在刚刚过去的两周,百度、搜狗、讯飞进行了连续三场的发布会,他们各家都展示了语音交互相关的一些系统,并且有趣的是,他们均声称识别性能达到了97%。
看到这里,很多听众可能会问,语音识别的性能已经如此之高,对它进行研究还有价值吗?包括我自己的学生也会问我,钱老师,语音识别性能已经做得如此好了,我们还需要进一步研究吗?我们做这个课题还能毕业吗?
那我想问大家的是,语音识别真的解决了吗?这里我将以上三个big news背后的语音识别系统应用到的主要的技术罗列如下:

将以上三个系统背后的技术应用到我们真实的产品中,比如这里所列的apple的siri、google的google now、微软的cortana助手、亚马逊的echo,性能优会怎么样?我可以告诉大家,这里所列的很多技术都不能很好地工作。这是因为以上三个系统的相关技术都是针对特定的任务以及在特定的环境下进行过度调优的。
即使是一个研究比较成熟的英文的命令词识别系统,给它只要添加一点点的麻烦,比如用苏格兰口音的英语,它的性能就会急速的下降。所以,在这些非配合式的语音交互方面,语音识别的性能远远没有满足我们的要求。所谓的配合式,比如说要求你说普通话,要求你拿手持麦克风等等,我们要是没有这些条件,让你一个用户随便的进行一个自然语言的交流,它的系统能照样保持鲁棒性吗?所以,语音识别的路还很长。
传统语音识别如何实现?
语音识别是对语音内容进行提取的一把金钥匙,它的研究可以追溯到半个世纪以前。在本世纪初,基于语音识别的一些产品已经开始问世,最有代表性的是在2000年左右,美军用于伊拉克战场的语音翻译机。2011年apple在iphone4s上推出的siri语音助手,之后包括微软、谷歌、亚马逊,以及国内的百度、讯飞、思必驰等等也推出了各自基于语音交互的产品。国内外的研究机构很多,包括国外的微软、谷歌、IBM、亚马逊,以及国内的百度、讯飞、思必驰等等。学术界就更多了,包括老牌的剑桥、MIT、JHU,以及国内的清华大学、中国科大、上海交大等等。
语音识别历来是人工智能和机器学习中的十大经典难题之一,它的难点可以归结为三个不确定性——说话人、环境、设备。说话人方面,我们不同的人有不同的口音,来自不同的方言区,说话的时候又有不同的方式,同时我们在说话的时候运用不同的情感;我们真实的环境是非常复杂的,包括各种各样的噪声,包括汽车喇叭声、飞机的噪声、马路上人的声音,还有一些会场的回声等等;设备方面,我们可以用手持麦克风、领夹麦克风、耳戴麦克风、近场远场的麦克风等等。此外在真实的实际应用场景下,往往是这三个因素叠加在一起的,使得整个的影响变得更加的复杂,所以如何设计一套鲁棒的性能好的语音识别系统,来很好的处理这些不确定性,也是非常具有挑战性的。
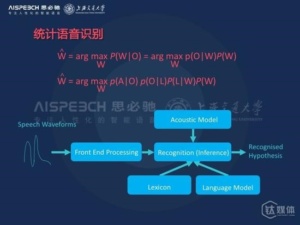
统计语音识别,如果从数学上来定义,可以归结为如下图的概率公式。这里的P(W|O)给定你观测到的语音,来得到最大的词序列。通过公式展开,这个概率可以归为两个概率,也就是P(O|W)和P(W),对应到我们语音识别中的声学模型和语言模型。当然这个概率可以进一步的分解,分解成如下的四个概率,这四个概率在语音识别系统的设计上也对应到如下框图中的四个模块,其中P(A|O)是前端语音信号处理模块,P(O|L)是声学模型模块,P(L|W)的字典模块,P(W)是语言模型。在这四个模块下,通过一个解码的过程得到最终的语音识别结果。
下面我们来说说四个概率模型:
第一个概率模型是特征提取P(A|O)。特征提取是所有的模式识别问题的第一步,如何从一个原始的信号中提取具有更具有鉴别性、区分性的特征是非常关键的,原始的语音模型信号冗余度比较大,所以我们必须对它进行特征的抽取。一旦特征提取的模式确定下来之后,其实这个概率模型我们也可以简单的将它理解成一个确定化的模型。

第二个概率模型是声学模型P(O|L),它可以描述不同声音之间的各种不同特性,是语音识别四个模块中最关键的技术之一。据我所知,大部分公司中的语音组以及研究机构的语音组声学模型的小组肯定是所有的team中最大的。这也可以看到它的重要性,概率模型P(O|L)用于刻划不同语音单元之间的特性,比如说音素、音节、词字等等,在语音识别发展的过去二三十年,HMM模型被广泛的采用,并占据统治地位。

第三个概率模型是字典模型P(L|W)。字典模型为声学模型以及后面要介绍的语言模型之间构建了一个桥梁,它在词和声学单元之间定义了一个映射,它可以是一个确定化的模型,也可以是一个概率模型,举一个简单的例子,tomato我们可以有两种发音,一种是英式,一种是美式,如果假设我们现在是在美国,那我们可以很有理由的相信,现在使用tomato的概率比tomato高,所以我们将tomato赋予概率5.55,tomato概率赋予5.45。

第四个概率模型是语言模型P(W)。语言模型是在给定历史的情况下预测下一个词的概率,它可以很好的引导搜索算法,消除声学单元之间的混淆性,特别是那些声学层相似的单元。举的一个例子,great wine 和grey twine如果没有语言模型,在纯声学音素层面,把这两个字串写成两个音素串是完全一模一样的,所以在这种情况下,我们仅靠声学去区分是不可行的,在这种情况下语言模型就变得很重要,你想第一个组合Great wine是一种正常的搭配,grey twine第二种组合是不会存在的。

语言模型的具体的应用有很多种,包括之前的那种上下文自由语法,你可以简单认为他是一种特殊的比较简单的语言模型,到后来过去的二三十年中一直占据统治地位的N-gram语言模型,以及在近几年比较火的基于深度学习方法,基于神经网络的语言模型,但是由于一些应用上的局限性,据我所知目前在大部分公司或者是研究组性能最好的商用的语音识别系统采用的语言模型还是N-gram的语言模型。
在这四个概率模型建模的基础上,我们可以在一个庞大的搜索网络上进行搜索和解码,下图是一个简单搜索网络的示意。当然我们在实际的应用中,搜索网络要比这个复杂成千上万倍,在这四个概率的引导下,我们通过我们的最优化的方法将最后的识别结果给找出来,根据相关算法的不同可以分为如下的种类,包括动态的、静态的解码器,以及深度优先或者广度优先,以及单便利和多便利解码器等等,目前大部分商用系统采用的是静态的、广度优先的、多便利解码算法。

到这里我已经把传统语音识别的几个重要模块给介绍完了,当然每个模块其实就是一个很大的课题,可以做很多的研究。
基于深度学习的语音识别
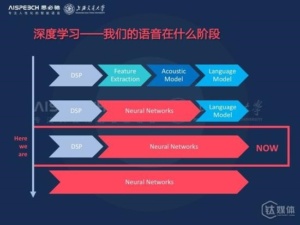
传统的语音识别需要经过前端的信号处理、特征特区、声学模型、语言模型等等各个模块的优化,来实现整个系统的识别。深度学习出来以后主要做了哪些工作呢?

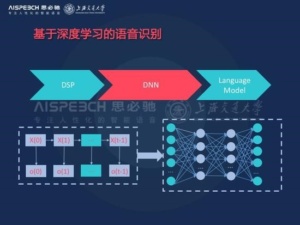
下图是基于深度学习的第一代的语音识别系统,我们可以看到,它是将传统的特征特区模块和声学建模模块完成了我们这里的DNN这部分,它将传统的声学模型中基于浅层的高斯混合模型替换成了我们现在的深度神经网络模型,通过深度神经网络模型的多层的非线性建模能力直接预测状态之间的分布函数,同时他不需要像传统方法一样进行基于人工的细致调节的特征的特区,他通过自身的深度模型的特征引擎能力,就可以从比较原始的语音信号中提取中比较具有鉴别能力的特征。
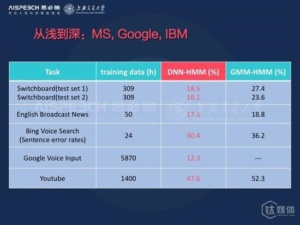
语音识别是深度学习方法第一个成功的任务,下图我们列出了在2011年以后,深度学习方法提出来以后,包括微软、谷歌,IBM,在各个语音识别任务上的性能对比,包括电话信道、广播信道,谷歌的移动信道包括像Yoube这种复杂的语音数据上,中间的那列红色的就是基于深度学习方法之后的词的错误率,最右边那列是传统方法的错误率,我们可以看到基于深度学习方法新的语音识别策略都得到大幅的性能提升。
从2011年到现在,五年过去了,深度学习方法又得到了进一步的发展。
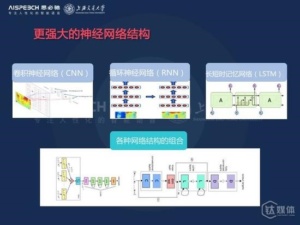
更强大的深度神经网络也被应用于语音识别,包括这里所列的卷积神经网络,它可以对平移不变性和局部刻划进行很好的建模,此外对长时信息建模能力比较强的递归神经网络,以及在这个基础上派生出来的长短时记忆模型等等,此外在这些模型的基础上各种组合模型也被提出,包括谷歌提出CLD模型,也就是所谓的卷积神经网络加上递归神经网络加上全连接网络的神经网络组合模式,它可以利用各个神经网络的优势可以进一步的提升性能。
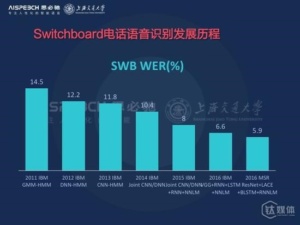
下图是在电话语音识别库上,从2011年到2016年,随着深度学习的发展,语音识别的进展。第一列是IBM在2011年的时候基于传统方法的最好的系统性能,那时候大概错误率14.5,随着这几年的发展我们慢慢的从14.5做到了将近10到去年8%的错误率,在今年刚刚过去的9月国际语音通讯联盟大会上IBM报道6.6的错误率,但是在过去不到一个月,微软雷德蒙研究院就报道了一个5.9%的错误率。可以说这几年的发展是飞速的,这个识别结果在2015年前或者说是不可想象的。
大家知道,电话语音数据库在上世纪90年代中刚推出来的时候,它的识别性能识别错误率几乎是100%,也就是说,你说一句话100%都是错误的,一个字都没对,我们可以看到经过20年的进展,特别是这五年的进展,识别性能已经达到了一个几乎跟人类持平的水平。
国内语音识别的技术方案
这是我是根据各个公开发表的文献可查的总结了几家所有的语音识别技术方案,包括百度、科大讯飞、思必驰,这三家基本上代表了业界语音识别研究的最高水平,因为百度有百度深度研究院,讯飞和中国科学技术大学也有联合实验室,思必驰和我们上海交大也有联合实验室。
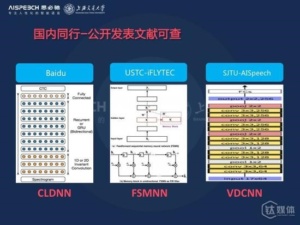
百度使用的是一个所谓CLD的模型,就是刚才我前面所说的准基神经网络加递归神经网络加全连接神经网络组合的模型;科大讯飞采用的是一个所谓FSMNN的一个模型,你可以简单的理解成它介于递归和前馈经网络的之间的模型,它可以既像递归神经网络一样,对长时信息进行很好的建模,同时又用前馈神经网络快速计算的一个优势;而我们思必驰和上海交大采用的是一个叫极深卷积神经网络的模型,它通过很小的卷积层和迟化层,将传统应用于语音识别的浅层卷积神经网络扩展到十层以上,这样他就可以对局部的信息进行更加精细的建模得到很好的系统性能。
语音识别面临的困境
在过去的五年中,基于深度学习方法,语音识别确实得到了一个飞速的发展,但是语音识别目前还面临着很多的困境,包括噪声鲁棒性、多类复杂性、低数据资源、多语言特性、低计算资源等等,我将简单的介绍几个困境。
1.噪声鲁棒性
做声环境下的鲁棒语音识别一直是语音识别大规模应用的主要绊脚石,我们如何在一些噪声场景比较大的情况下,比如说我们的马路、咖啡厅,公共汽车,飞机场,以及会议室,大巴上等等,使得得到很高的识别精度,这是非常具有挑战性的。
针对这个困境,我们上海交大和思必驰推出了一些解决策略,包括环境感知的深度模型以及神经网络的快速自适应方法,它使得我们一般的深度模型可以对环境进行一个实时的感知和自适应调整,来提高实现系统性能,就像人耳一样。另外我们也将极深卷积神经网络用于抗噪的语音识别得到巨大的系统性能的提升,在这个方面,我们在今年在语音处理的权威期刊IEEE/ACM Transactions on Audio, Speech and Language Processing上发表了三篇期刊论文,大家有兴趣的话也可以下载翻阅。这里值得一提的是其中两个成果,一个成果是登上了IEEE/ACM Transactions on ASLP第11、12期的封面,另一个成果也上了这个期刊在近几个月统计的最流行杂志的榜首。
下面我给大家看一下在语音识别的著名的数据库,噪声数据库Aurora4世界最高水平的几个研究机构的系统性能的对比,最左边是剑桥大学在2012年深度学习方法出来以前最好的系统是13.4%的一个错误率,然后经过这几年的优化,包括微软2013年发表的12.4%的错误率,到2014年IBM大概达到10%的错误率,科大讯飞去年也是在2015年发表了一个是10.3%,也是在10%左右,我们去年年底也得到9.7%的错误率,我们可以看到在今年以前,大部分的研究机构最好的识别性能错别率也在10%左右。
今年上半年,英国爱丁堡大学得到一个比较好的结果是8.7%的错误率,但是在两三个月以后,在今年的六七月份,我们达到了7.1%的错误率。我们在抗噪语音识别上得到飞速的进展。
2.多类复杂性
过去的大部分语音识别系统的设计主要是针对一些单一环境、单一场景下进行设计的,如何做多类别复杂场景下的通用的语音识别是非常困难的,比如说在Youtube或者BBC上的一些数据,可以来自各种各样的语境和场景,有新闻广播、新闻采访、音乐会、访谈、电影等等,如何在多预警下做成一个通用的鲁棒的语音识别性能呢,是比较有挑战性的。
在这个方面我们去年参加了由英国BBC公司和EPSRC主办的MGB挑战赛,其中我们在四个单向上均列世界第一,且每个单向的成绩均大幅领先第二名,涉及语音识别、说话人分割聚类、标注对齐、时序渐进语音识别等技术,处于行业领域地位。
3.低数据资源与多语言
目前大部分语音识别的研究和应用,主要是基于一些大语种,比如说英语、汉语、阿拉伯语和法语等等,我们知道世界上一共有6900多种语言,如何快速的实现一套基于任何语言的语言识别系统是非常困难的,它也具有重大的战略意义。包括美国IARPA这几年的Babel计划,以及之前DARPA的GALE计划,考虑到中国的国情我们有56个民族,所以构建一套多语言低数据资源下的语音识别系统是非常关键和具有实际价值的。
在这个方面我们也在公开相同的数据环境下,搭建了相关系统,下图是我们和美国约翰霍普金斯大学的性能对比,我们在相同数据集合上取得了一个更优的一个策略。
4.低计算资源
目前大部分的语音识别的应用,包括我们手机上看到的一些app的应用,这些语音识别背后都是基于云端的在线的一些语音识别的服务。如何在离线的环境下,基于一些有限的硬件资源做一些低功耗的离线的实时的大智慧的连续性识别是非常困难的,但是如果这个困境能解决,也是可以将语音识别真正走向千家万户,有巨大的推动作用的。
在这个方面我们也提出了解决策略,我们通过用连接时续模型去取代隐含马尔科夫模型,将系统性能在速度上提升了7倍多,同时我们将传统的基于帧同步的解码方案替换成音素同步解码方案,将系统的实时率进一步提升到20倍,相关的方法我们也今年发表在IEEE/ACM Transactions on ASLP的期刊上。下面有相关的论文的介绍,大家也可以下载。

几个有用的开源工具、参考书
1.Kaldi语音识别开源软件
它是由约翰霍普金斯Dan Povey领导的,由九家著名语音机构13人核心工作组历时两年开发完成的语音识别开源软件,我也是这13人核心工作组中唯一来自亚洲的成员,当时我在清华大学,现在是在上海交通大学工作。然后这套工具包自2011年发布以来,下载量已经超过了两万多次,合著的论文目前也已经被引用一千多次。
Kaldi的影响是巨大的,他是第一个完全用C++编写的,基于加权有限状态及理论的语音识别开源软件,它的模块化与高度可扩展性设计,详细的说明文档,完备公开的实力教程,也使得它受广大开发者喜好的一个主要的原因。他目前被业界广泛采用作为标准工具,包括学术界的MIT、CMU、GHU、剑桥,国内的清华、上海交大等等,工业界包括微软、谷歌、IBM,Facebook等等,它的推出也极大推进整个语音识别领域的发展。
2.HTK-Hiddden Markov模型工具包
它是语音识别历史上第一个开源的工具包,由剑桥大学的两位教授,一个是剑桥大学的前副校长Steve Young,还有一个是剑桥大学智能语音实验室的主任Phil Woodland教授领导开发的一个开源软件工具包,这两位也是英国皇家工程院的院士。Phil Woodland教授也是我当时在剑桥做博士后研究时候的合作导师。
HTK目前有十多万的注册用户,引用次数也超过了五千多次,它所构建的系统连续蝉联了美国INST和DARPA评测的冠军,可以说在深度学习出来以前,基于HTK的一些系统统治了语音识别将近20年。这里值得一提比较有趣的事情是前面开源工具包Kaldi的作者是Dan Povey,其中Dan Povey又是这个HTK工具包Phil Woodland教授的学生,所以我们可以说,老师开发了第一代语音识别开源软件,学生开发了第二代语音识别开源软件。
在去年,HTK针对深度学习方法,也发布了它的3.5版本,它可以对通用的神经网络结构进行支持,此外还包括基于神经网络的自适应技术,基于神经网络的鉴别性训练方法等等,其他包括准基神经网络,GRU,LSTM等等也在发布的计划中,使用HTK3.5所构建的系统在这两年也获得多个世界性评测的冠军,其中我在前面两年也参与了如下的一些工作:包括2014年DARPA-BOLT的冠军,2014年IARPA-Babel的冠军,2015年IARPA-Babel的冠军,以及2015年EPSRC-MGB的冠军,还有今年的IARPA-Babel的亚军等等。我也参与了其中几个比赛系统的构建。
3.CUED-RNNLM
这是一套语言模型的开源工具软件,也是由剑桥大学开发去年发布的,我也是合著者之一。它是对递归神经网络的语言模型进行了一个很好的支持,相比之前捷克布尔诺理工发布的RNNLM版本,它可以很好的用GPU进行加速训练,同时它又可以支持快速的训练和评估的算法和自适应技术。此外这套工具包又对HTK和Kaldi两套开源软件进行了很好的适配,可以对两个系统的Lattice进行重打分和重新解码计算,这套开源工具包也被剑桥应用于近期的各个比赛的系统,得到了很好的一个成绩。
· 一些开源的深度学习的工具
目前比较流行的使用范围比较广的,包括微软的CNTK,谷歌的Tensorflow,以及由DMLC维护的mxnet等等,还有之前包括来自蒙特利尔大学的Theano,来自伯克利的Caffe以及来自NYU的Torch等等。每套工具都有各自的优势,不能说孰优孰劣,这完全根据大家的各自的兴趣以及开发的语言的喜欢去选择。
这里我想重点介绍的是微软的CNTK,也是目前我们上海交大和思必驰所使用的一套深度学习的开源软件。它是由微软的雷德蒙研究院黄学东博士领导开发的一套计算网络工具包,它可以很好的支持对各种神经网络,对各种新奇算法训练的支持,此外在CNTK对Theano、Tensorflow、torch和Caffe等等的计算速度的对比方面,CNTK无论在单GPU,或是单机多卡的情况下,还是多机多卡的情况下,在速度上都有一个明显的性能的优势。
《语音识别实践》

这是由美国微软雷德蒙研究院首席科学家俞栋老师和邓力老师撰写的一本关于深度学习和语音识别相结合的书籍,同时这本书中又对深度学习和语音识别在一些产品级应用上的一些细节做了一些案例的介绍,它的英文版已经与去年由斯普林格出版社正式出版。此外我和俞凯教授两个人对这本英文版进行了翻译,中文译本于今年由电子工业出版社出版,大家也可以在京东或者亚马逊上进行购买。
思必驰和上海交大联合实验室
思必驰是国内为数不多的拥有完整知识产权的语音公司,从纵向上看,它是国内仅有的两家拥有全面的语音技术的公司之一,我们从2007年剑桥创立至今已经走过了近十年,从基本的大数据开始做积累,从识别引擎开始做,慢慢做到语音合成,再到语音识别++,再到现在整体的语音交互系统,我们在语音这条路上不断的深入下去,在2015年的年初,思必驰也首个提出了认知智能概念层次。
从横向上看,思必驰是目前国内唯一一家只针对智能硬件领域提供语音支持的公司,我们只针对智能车载、家居、机器人三个领域提供解决方案,保证技术的垂直性和适用性,我们自己不做2C的产品,但是向企业提供纯软的解决方案和软硬一体化的解决方案。我们是一个技术型的AI公司,尽量根据客户的不同需求去提供各种实用且合适的语音方案。纯软的解决方案,即我们的AIOS,思必驰人工智能操作系统,去年10月也率先推出了AIOS for Car,在后端市场上占有率达到60%,其中智能后视镜在70%左右,HUD车载占据了大概80%,同时和小鹏汽车、智车优行等互联网汽车也签署了合作。此外我们还有软硬一体化的解决方案,包括国内首款量产的环形6+1远场麦克风阵列,四麦线性方案,以及和君正、庆科合作推出带语音功能的芯片模组。
思必驰目前已经快速成长为这个领域的No.1,目前思必驰的业务合作领域主要专注在智能硬件领域,包括车载、家居、机器人。目前在智能车载中,思必驰还主要是在后装市场,是阿里YunOS的唯一战略合作伙伴,所有用YunOS的车载产品都用的是思必驰语音,思必驰目前后装市场占有率是第一,60%左右,智能后视镜领域约为70%,HUD约为80%。在智能家居领域,包括音箱、电视、空调、油烟机等等,以及前两天小米刚发布的小米音箱也是我们最新的合作案例,今年年底或明年年初,我们还有几款重要的合作客户产品要上市,敬请大家期待。在家居领域,思必驰还有上升空间,目前在第二。而智能机器人领域,由于生态尚早,现在机器人产品龙蛇混杂,但未来潜力大,我们主要是在与服务型机器人合作,塑造典型的精品案例,包括大华小乐机器人、360小巴迪、东方网力、金刚蚁的小忆机器人、小萝卜机器人等,都是我们的合作案例。
我们除了在不断深入语音技术研发以外,还在做的一件事情就是打通整个后端服务,从导航到音乐,到资讯搜索,到个人管家甚至O2O,通过语音交互,让用户和第三方内容无缝链接起来,提供一站式的产业化服务,配合合作客户一起打造更实用,更有趣的人机交互体验,在未来很长一段时间内,这都将是我们坚持不变的理念和方向。
随着移动互联网和人工智能的发展,基于语音的交互已经越来越重要、也越来越普及。下面这张图中展示的是一个智能语音交互闭环的系统,包括前端的感知层面,也就是语音识别和语音合成,以及后端的理解决策层面,包括理解、决策、表述等各个模块。我们可以看到,在整个闭环系统中,语音识别作为整个闭环的入口,性能的好坏直接决定整个智能语音交互系统的用户满意度,其重要性可想而知。
过去三个月,在语音识别领域有几个大新闻:一个是今年10月,美国微软雷德蒙研究院在电话语音识别的标准库Switchboard上报道达到5.9%的错误率,我们要知道,在这个库上人类也只能达到大概5.9%,而机器的性能已经和人类基本达到了持平;第二个新闻是在今年9月,也就是国际语音通信联合会的最后一天报道的CHIME4国际多通道语音分离和识别大赛,你可以简单认为这是一个在限定词表和场景下的带噪的语音识别挑战赛,最好的系统性能报道达到了将近2%的错误率;第三个新闻可能大家更关心,是关于中文的,在刚刚过去的两周,百度、搜狗、讯飞进行了连续三场的发布会,他们各家都展示了语音交互相关的一些系统,并且有趣的是,他们均声称识别性能达到了97%。
看到这里,很多听众可能会问,语音识别的性能已经如此之高,对它进行研究还有价值吗?包括我自己的学生也会问我,钱老师,语音识别性能已经做得如此好了,我们还需要进一步研究吗?我们做这个课题还能毕业吗?
那我想问大家的是,语音识别真的解决了吗?这里我将以上三个big news背后的语音识别系统应用到的主要的技术罗列如下:
将以上三个系统背后的技术应用到我们真实的产品中,比如这里所列的apple的siri、google的google now、微软的cortana助手、亚马逊的echo,性能优会怎么样?我可以告诉大家,这里所列的很多技术都不能很好地工作。这是因为以上三个系统的相关技术都是针对特定的任务以及在特定的环境下进行过度调优的。
即使是一个研究比较成熟的英文的命令词识别系统,给它只要添加一点点的麻烦,比如用苏格兰口音的英语,它的性能就会急速的下降。所以,在这些非配合式的语音交互方面,语音识别的性能远远没有满足我们的要求。所谓的配合式,比如说要求你说普通话,要求你拿手持麦克风等等,我们要是没有这些条件,让你一个用户随便的进行一个自然语言的交流,它的系统能照样保持鲁棒性吗?所以,语音识别的路还很长。
传统语音识别如何实现?
语音识别是对语音内容进行提取的一把金钥匙,它的研究可以追溯到半个世纪以前。在本世纪初,基于语音识别的一些产品已经开始问世,最有代表性的是在2000年左右,美军用于伊拉克战场的语音翻译机。2011年apple在iphone4s上推出的siri语音助手,之后包括微软、谷歌、亚马逊,以及国内的百度、讯飞、思必驰等等也推出了各自基于语音交互的产品。国内外的研究机构很多,包括国外的微软、谷歌、IBM、亚马逊,以及国内的百度、讯飞、思必驰等等。学术界就更多了,包括老牌的剑桥、MIT、JHU,以及国内的清华大学、中国科大、上海交大等等。
语音识别历来是人工智能和机器学习中的十大经典难题之一,它的难点可以归结为三个不确定性——说话人、环境、设备。说话人方面,我们不同的人有不同的口音,来自不同的方言区,说话的时候又有不同的方式,同时我们在说话的时候运用不同的情感;我们真实的环境是非常复杂的,包括各种各样的噪声,包括汽车喇叭声、飞机的噪声、马路上人的声音,还有一些会场的回声等等;设备方面,我们可以用手持麦克风、领夹麦克风、耳戴麦克风、近场远场的麦克风等等。此外在真实的实际应用场景下,往往是这三个因素叠加在一起的,使得整个的影响变得更加的复杂,所以如何设计一套鲁棒的性能好的语音识别系统,来很好的处理这些不确定性,也是非常具有挑战性的。
统计语音识别,如果从数学上来定义,可以归结为如下图的概率公式。这里的P(W|O)给定你观测到的语音,来得到最大的词序列。通过公式展开,这个概率可以归为两个概率,也就是P(O|W)和P(W),对应到我们语音识别中的声学模型和语言模型。当然这个概率可以进一步的分解,分解成如下的四个概率,这四个概率在语音识别系统的设计上也对应到如下框图中的四个模块,其中P(A|O)是前端语音信号处理模块,P(O|L)是声学模型模块,P(L|W)的字典模块,P(W)是语言模型。在这四个模块下,通过一个解码的过程得到最终的语音识别结果。
下面我们来说说四个概率模型:
第一个概率模型是特征提取P(A|O)。特征提取是所有的模式识别问题的第一步,如何从一个原始的信号中提取具有更具有鉴别性、区分性的特征是非常关键的,原始的语音模型信号冗余度比较大,所以我们必须对它进行特征的抽取。一旦特征提取的模式确定下来之后,其实这个概率模型我们也可以简单的将它理解成一个确定化的模型。
第二个概率模型是声学模型P(O|L),它可以描述不同声音之间的各种不同特性,是语音识别四个模块中最关键的技术之一。据我所知,大部分公司中的语音组以及研究机构的语音组声学模型的小组肯定是所有的team中最大的。这也可以看到它的重要性,概率模型P(O|L)用于刻划不同语音单元之间的特性,比如说音素、音节、词字等等,在语音识别发展的过去二三十年,HMM模型被广泛的采用,并占据统治地位。
第三个概率模型是字典模型P(L|W)。字典模型为声学模型以及后面要介绍的语言模型之间构建了一个桥梁,它在词和声学单元之间定义了一个映射,它可以是一个确定化的模型,也可以是一个概率模型,举一个简单的例子,tomato我们可以有两种发音,一种是英式,一种是美式,如果假设我们现在是在美国,那我们可以很有理由的相信,现在使用tomato的概率比tomato高,所以我们将tomato赋予概率5.55,tomato概率赋予5.45。
第四个概率模型是语言模型P(W)。语言模型是在给定历史的情况下预测下一个词的概率,它可以很好的引导搜索算法,消除声学单元之间的混淆性,特别是那些声学层相似的单元。举的一个例子,great wine 和grey twine如果没有语言模型,在纯声学音素层面,把这两个字串写成两个音素串是完全一模一样的,所以在这种情况下,我们仅靠声学去区分是不可行的,在这种情况下语言模型就变得很重要,你想第一个组合Great wine是一种正常的搭配,grey twine第二种组合是不会存在的。
语言模型的具体的应用有很多种,包括之前的那种上下文自由语法,你可以简单认为他是一种特殊的比较简单的语言模型,到后来过去的二三十年中一直占据统治地位的N-gram语言模型,以及在近几年比较火的基于深度学习方法,基于神经网络的语言模型,但是由于一些应用上的局限性,据我所知目前在大部分公司或者是研究组性能最好的商用的语音识别系统采用的语言模型还是N-gram的语言模型。
在这四个概率模型建模的基础上,我们可以在一个庞大的搜索网络上进行搜索和解码,下图是一个简单搜索网络的示意。当然我们在实际的应用中,搜索网络要比这个复杂成千上万倍,在这四个概率的引导下,我们通过我们的最优化的方法将最后的识别结果给找出来,根据相关算法的不同可以分为如下的种类,包括动态的、静态的解码器,以及深度优先或者广度优先,以及单便利和多便利解码器等等,目前大部分商用系统采用的是静态的、广度优先的、多便利解码算法。
到这里我已经把传统语音识别的几个重要模块给介绍完了,当然每个模块其实就是一个很大的课题,可以做很多的研究。
基于深度学习的语音识别
传统的语音识别需要经过前端的信号处理、特征特区、声学模型、语言模型等等各个模块的优化,来实现整个系统的识别。深度学习出来以后主要做了哪些工作呢?
下图是基于深度学习的第一代的语音识别系统,我们可以看到,它是将传统的特征特区模块和声学建模模块完成了我们这里的DNN这部分,它将传统的声学模型中基于浅层的高斯混合模型替换成了我们现在的深度神经网络模型,通过深度神经网络模型的多层的非线性建模能力直接预测状态之间的分布函数,同时他不需要像传统方法一样进行基于人工的细致调节的特征的特区,他通过自身的深度模型的特征引擎能力,就可以从比较原始的语音信号中提取中比较具有鉴别能力的特征。
语音识别是深度学习方法第一个成功的任务,下图我们列出了在2011年以后,深度学习方法提出来以后,包括微软、谷歌,IBM,在各个语音识别任务上的性能对比,包括电话信道、广播信道,谷歌的移动信道包括像Yoube这种复杂的语音数据上,中间的那列红色的就是基于深度学习方法之后的词的错误率,最右边那列是传统方法的错误率,我们可以看到基于深度学习方法新的语音识别策略都得到大幅的性能提升。
从2011年到现在,五年过去了,深度学习方法又得到了进一步的发展。
更强大的深度神经网络也被应用于语音识别,包括这里所列的卷积神经网络,它可以对平移不变性和局部刻划进行很好的建模,此外对长时信息建模能力比较强的递归神经网络,以及在这个基础上派生出来的长短时记忆模型等等,此外在这些模型的基础上各种组合模型也被提出,包括谷歌提出CLD模型,也就是所谓的卷积神经网络加上递归神经网络加上全连接网络的神经网络组合模式,它可以利用各个神经网络的优势可以进一步的提升性能。
下图是在电话语音识别库上,从2011年到2016年,随着深度学习的发展,语音识别的进展。第一列是IBM在2011年的时候基于传统方法的最好的系统性能,那时候大概错误率14.5,随着这几年的发展我们慢慢的从14.5做到了将近10到去年8%的错误率,在今年刚刚过去的9月国际语音通讯联盟大会上IBM报道6.6的错误率,但是在过去不到一个月,微软雷德蒙研究院就报道了一个5.9%的错误率。可以说这几年的发展是飞速的,这个识别结果在2015年前或者说是不可想象的。
大家知道,电话语音数据库在上世纪90年代中刚推出来的时候,它的识别性能识别错误率几乎是100%,也就是说,你说一句话100%都是错误的,一个字都没对,我们可以看到经过20年的进展,特别是这五年的进展,识别性能已经达到了一个几乎跟人类持平的水平。
国内语音识别的技术方案
这是我是根据各个公开发表的文献可查的总结了几家所有的语音识别技术方案,包括百度、科大讯飞、思必驰,这三家基本上代表了业界语音识别研究的最高水平,因为百度有百度深度研究院,讯飞和中国科学技术大学也有联合实验室,思必驰和我们上海交大也有联合实验室。
百度使用的是一个所谓CLD的模型,就是刚才我前面所说的准基神经网络加递归神经网络加全连接神经网络组合的模型;科大讯飞采用的是一个所谓FSMNN的一个模型,你可以简单的理解成它介于递归和前馈经网络的之间的模型,它可以既像递归神经网络一样,对长时信息进行很好的建模,同时又用前馈神经网络快速计算的一个优势;而我们思必驰和上海交大采用的是一个叫极深卷积神经网络的模型,它通过很小的卷积层和迟化层,将传统应用于语音识别的浅层卷积神经网络扩展到十层以上,这样他就可以对局部的信息进行更加精细的建模得到很好的系统性能。
语音识别面临的困境
在过去的五年中,基于深度学习方法,语音识别确实得到了一个飞速的发展,但是语音识别目前还面临着很多的困境,包括噪声鲁棒性、多类复杂性、低数据资源、多语言特性、低计算资源等等,我将简单的介绍几个困境。
1.噪声鲁棒性
做声环境下的鲁棒语音识别一直是语音识别大规模应用的主要绊脚石,我们如何在一些噪声场景比较大的情况下,比如说我们的马路、咖啡厅,公共汽车,飞机场,以及会议室,大巴上等等,使得得到很高的识别精度,这是非常具有挑战性的。
针对这个困境,我们上海交大和思必驰推出了一些解决策略,包括环境感知的深度模型以及神经网络的快速自适应方法,它使得我们一般的深度模型可以对环境进行一个实时的感知和自适应调整,来提高实现系统性能,就像人耳一样。另外我们也将极深卷积神经网络用于抗噪的语音识别得到巨大的系统性能的提升,在这个方面,我们在今年在语音处理的权威期刊IEEE/ACM Transactions on Audio, Speech and Language Processing上发表了三篇期刊论文,大家有兴趣的话也可以下载翻阅。这里值得一提的是其中两个成果,一个成果是登上了IEEE/ACM Transactions on ASLP第11、12期的封面,另一个成果也上了这个期刊在近几个月统计的最流行杂志的榜首。
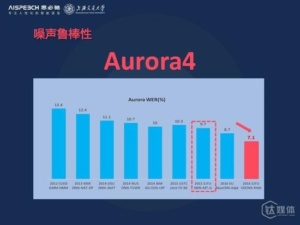
下面我给大家看一下在语音识别的著名的数据库,噪声数据库Aurora4世界最高水平的几个研究机构的系统性能的对比,最左边是剑桥大学在2012年深度学习方法出来以前最好的系统是13.4%的一个错误率,然后经过这几年的优化,包括微软2013年发表的12.4%的错误率,到2014年IBM大概达到10%的错误率,科大讯飞去年也是在2015年发表了一个是10.3%,也是在10%左右,我们去年年底也得到9.7%的错误率,我们可以看到在今年以前,大部分的研究机构最好的识别性能错别率也在10%左右。
今年上半年,英国爱丁堡大学得到一个比较好的结果是8.7%的错误率,但是在两三个月以后,在今年的六七月份,我们达到了7.1%的错误率。我们在抗噪语音识别上得到飞速的进展。
2.多类复杂性
过去的大部分语音识别系统的设计主要是针对一些单一环境、单一场景下进行设计的,如何做多类别复杂场景下的通用的语音识别是非常困难的,比如说在Youtube或者BBC上的一些数据,可以来自各种各样的语境和场景,有新闻广播、新闻采访、音乐会、访谈、电影等等,如何在多预警下做成一个通用的鲁棒的语音识别性能呢,是比较有挑战性的。
在这个方面我们去年参加了由英国BBC公司和EPSRC主办的MGB挑战赛,其中我们在四个单向上均列世界第一,且每个单向的成绩均大幅领先第二名,涉及语音识别、说话人分割聚类、标注对齐、时序渐进语音识别等技术,处于行业领域地位。
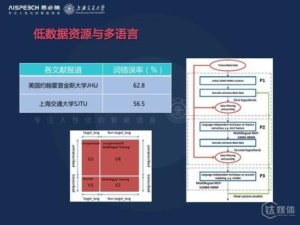
3.低数据资源与多语言
目前大部分语音识别的研究和应用,主要是基于一些大语种,比如说英语、汉语、阿拉伯语和法语等等,我们知道世界上一共有6900多种语言,如何快速的实现一套基于任何语言的语言识别系统是非常困难的,它也具有重大的战略意义。包括美国IARPA这几年的Babel计划,以及之前DARPA的GALE计划,考虑到中国的国情我们有56个民族,所以构建一套多语言低数据资源下的语音识别系统是非常关键和具有实际价值的。
在这个方面我们也在公开相同的数据环境下,搭建了相关系统,下图是我们和美国约翰霍普金斯大学的性能对比,我们在相同数据集合上取得了一个更优的一个策略。
4.低计算资源
目前大部分的语音识别的应用,包括我们手机上看到的一些app的应用,这些语音识别背后都是基于云端的在线的一些语音识别的服务。如何在离线的环境下,基于一些有限的硬件资源做一些低功耗的离线的实时的大智慧的连续性识别是非常困难的,但是如果这个困境能解决,也是可以将语音识别真正走向千家万户,有巨大的推动作用的。
在这个方面我们也提出了解决策略,我们通过用连接时续模型去取代隐含马尔科夫模型,将系统性能在速度上提升了7倍多,同时我们将传统的基于帧同步的解码方案替换成音素同步解码方案,将系统的实时率进一步提升到20倍,相关的方法我们也今年发表在IEEE/ACM Transactions on ASLP的期刊上。下面有相关的论文的介绍,大家也可以下载。
几个有用的开源工具、参考书
1.Kaldi语音识别开源软件
它是由约翰霍普金斯Dan Povey领导的,由九家著名语音机构13人核心工作组历时两年开发完成的语音识别开源软件,我也是这13人核心工作组中唯一来自亚洲的成员,当时我在清华大学,现在是在上海交通大学工作。然后这套工具包自2011年发布以来,下载量已经超过了两万多次,合著的论文目前也已经被引用一千多次。
Kaldi的影响是巨大的,他是第一个完全用C++编写的,基于加权有限状态及理论的语音识别开源软件,它的模块化与高度可扩展性设计,详细的说明文档,完备公开的实力教程,也使得它受广大开发者喜好的一个主要的原因。他目前被业界广泛采用作为标准工具,包括学术界的MIT、CMU、GHU、剑桥,国内的清华、上海交大等等,工业界包括微软、谷歌、IBM,Facebook等等,它的推出也极大推进整个语音识别领域的发展。
2.HTK-Hiddden Markov模型工具包
它是语音识别历史上第一个开源的工具包,由剑桥大学的两位教授,一个是剑桥大学的前副校长Steve Young,还有一个是剑桥大学智能语音实验室的主任Phil Woodland教授领导开发的一个开源软件工具包,这两位也是英国皇家工程院的院士。Phil Woodland教授也是我当时在剑桥做博士后研究时候的合作导师。
HTK目前有十多万的注册用户,引用次数也超过了五千多次,它所构建的系统连续蝉联了美国INST和DARPA评测的冠军,可以说在深度学习出来以前,基于HTK的一些系统统治了语音识别将近20年。这里值得一提比较有趣的事情是前面开源工具包Kaldi的作者是Dan Povey,其中Dan Povey又是这个HTK工具包Phil Woodland教授的学生,所以我们可以说,老师开发了第一代语音识别开源软件,学生开发了第二代语音识别开源软件。
在去年,HTK针对深度学习方法,也发布了它的3.5版本,它可以对通用的神经网络结构进行支持,此外还包括基于神经网络的自适应技术,基于神经网络的鉴别性训练方法等等,其他包括准基神经网络,GRU,LSTM等等也在发布的计划中,使用HTK3.5所构建的系统在这两年也获得多个世界性评测的冠军,其中我在前面两年也参与了如下的一些工作:包括2014年DARPA-BOLT的冠军,2014年IARPA-Babel的冠军,2015年IARPA-Babel的冠军,以及2015年EPSRC-MGB的冠军,还有今年的IARPA-Babel的亚军等等。我也参与了其中几个比赛系统的构建。
3.CUED-RNNLM
这是一套语言模型的开源工具软件,也是由剑桥大学开发去年发布的,我也是合著者之一。它是对递归神经网络的语言模型进行了一个很好的支持,相比之前捷克布尔诺理工发布的RNNLM版本,它可以很好的用GPU进行加速训练,同时它又可以支持快速的训练和评估的算法和自适应技术。此外这套工具包又对HTK和Kaldi两套开源软件进行了很好的适配,可以对两个系统的Lattice进行重打分和重新解码计算,这套开源工具包也被剑桥应用于近期的各个比赛的系统,得到了很好的一个成绩。
· 一些开源的深度学习的工具
目前比较流行的使用范围比较广的,包括微软的CNTK,谷歌的Tensorflow,以及由DMLC维护的mxnet等等,还有之前包括来自蒙特利尔大学的Theano,来自伯克利的Caffe以及来自NYU的Torch等等。每套工具都有各自的优势,不能说孰优孰劣,这完全根据大家的各自的兴趣以及开发的语言的喜欢去选择。
这里我想重点介绍的是微软的CNTK,也是目前我们上海交大和思必驰所使用的一套深度学习的开源软件。它是由微软的雷德蒙研究院黄学东博士领导开发的一套计算网络工具包,它可以很好的支持对各种神经网络,对各种新奇算法训练的支持,此外在CNTK对Theano、Tensorflow、torch和Caffe等等的计算速度的对比方面,CNTK无论在单GPU,或是单机多卡的情况下,还是多机多卡的情况下,在速度上都有一个明显的性能的优势。
《语音识别实践》
这是由美国微软雷德蒙研究院首席科学家俞栋老师和邓力老师撰写的一本关于深度学习和语音识别相结合的书籍,同时这本书中又对深度学习和语音识别在一些产品级应用上的一些细节做了一些案例的介绍,它的英文版已经与去年由斯普林格出版社正式出版。此外我和俞凯教授两个人对这本英文版进行了翻译,中文译本于今年由电子工业出版社出版,大家也可以在京东或者亚马逊上进行购买。
思必驰和上海交大联合实验室
思必驰是国内为数不多的拥有完整知识产权的语音公司,从纵向上看,它是国内仅有的两家拥有全面的语音技术的公司之一,我们从2007年剑桥创立至今已经走过了近十年,从基本的大数据开始做积累,从识别引擎开始做,慢慢做到语音合成,再到语音识别++,再到现在整体的语音交互系统,我们在语音这条路上不断的深入下去,在2015年的年初,思必驰也首个提出了认知智能概念层次。
从横向上看,思必驰是目前国内唯一一家只针对智能硬件领域提供语音支持的公司,我们只针对智能车载、家居、机器人三个领域提供解决方案,保证技术的垂直性和适用性,我们自己不做2C的产品,但是向企业提供纯软的解决方案和软硬一体化的解决方案。我们是一个技术型的AI公司,尽量根据客户的不同需求去提供各种实用且合适的语音方案。纯软的解决方案,即我们的AIOS,思必驰人工智能操作系统,去年10月也率先推出了AIOS for Car,在后端市场上占有率达到60%,其中智能后视镜在70%左右,HUD车载占据了大概80%,同时和小鹏汽车、智车优行等互联网汽车也签署了合作。此外我们还有软硬一体化的解决方案,包括国内首款量产的环形6+1远场麦克风阵列,四麦线性方案,以及和君正、庆科合作推出带语音功能的芯片模组。
思必驰目前已经快速成长为这个领域的No.1,目前思必驰的业务合作领域主要专注在智能硬件领域,包括车载、家居、机器人。目前在智能车载中,思必驰还主要是在后装市场,是阿里YunOS的唯一战略合作伙伴,所有用YunOS的车载产品都用的是思必驰语音,思必驰目前后装市场占有率是第一,60%左右,智能后视镜领域约为70%,HUD约为80%。在智能家居领域,包括音箱、电视、空调、油烟机等等,以及前两天小米刚发布的小米音箱也是我们最新的合作案例,今年年底或明年年初,我们还有几款重要的合作客户产品要上市,敬请大家期待。在家居领域,思必驰还有上升空间,目前在第二。而智能机器人领域,由于生态尚早,现在机器人产品龙蛇混杂,但未来潜力大,我们主要是在与服务型机器人合作,塑造典型的精品案例,包括大华小乐机器人、360小巴迪、东方网力、金刚蚁的小忆机器人、小萝卜机器人等,都是我们的合作案例。
我们除了在不断深入语音技术研发以外,还在做的一件事情就是打通整个后端服务,从导航到音乐,到资讯搜索,到个人管家甚至O2O,通过语音交互,让用户和第三方内容无缝链接起来,提供一站式的产业化服务,配合合作客户一起打造更实用,更有趣的人机交互体验,在未来很长一段时间内,这都将是我们坚持不变的理念和方向。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消