











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






7分钟了解Facebook新AI的音乐风格迁移
2018年08月17日 由 yuxiangyu 发表
57202
0

想象一下:你的朋友为了听一首歌纠缠了你好几个星期,即使你告诉他们你不喜欢艾德·希兰(Ed Sheeran),神烦!他们一直纠缠你,声称“旋律使它伟大”。要是你能换一种形式来听这种旋律就好了,比如巴赫的管风琴协奏曲那样。
因此,Facebook的人工智能研究团队提出了一个音乐领域迁移系统,这个系统号称可以翻译“乐器,流派和风格”。如下视频:
[video width="640" height="360" mp4="https://www.atyun.com/uploadfile/2018/08/A-Universal-Music-Translation-Network.mp4"][/video]
我很震惊,这是非常令人印象深刻的东西。它改进了两个领域:领域转移和音频合成。领域迁移空间的最新进展在包含循环一致性(hehe)方面是一致的,如StarGAN(Choi等人,2017),CycleGAN(Zhu等人,2017),DiscoGAN(Kim等人,2017)),NounGAN(并不存在,但这些作者需要对他们的网络名称更具冒险精神!)。使用周期一致性损失的核心目标是鼓励网络保留所有与内容相关的信息,并专注于更改与领域相关的信息。
嗯,也许对你来说,这样说比较混乱。让我们拆开来讲。循环一致性概括了以下陈述:F(G(X))≈X,函数G(X)应该有一个对应的逆F(X),它近似地返回输入X。通过引入循环一致性损失可以鼓励这种情况,如下所示:
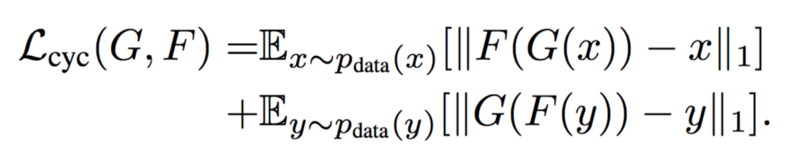
取在所有前向循环一致性x→G(x)→F(G(x))≈x和所有反向循环一致性的误差 y→F(y)→G(F(y))≈y。
现在,对于区分是领域相关的信息还是与内容相关的信息,这个有点难。在GAN的上下文中,领域信息是给定输入中确定其适合其这个领域的所有内容,而内容信息是关于图像的所有其他内容。例如,如果我们以下这样一辆汽车的图像:

我们有一个领域的集合,其中包括这样的汽车:{红色汽车,蓝色汽车,绿色汽车},我们得出结论,图像中所有与域相关的信息都是汽车的红色,而诸如汽车的形状、大灯的数量,背景等都是与内容相关的信息。
但FAIR团队的模型不是循环一致的,我们稍微费了一些时间来研究这个问题,不过,至少我们学到一些。由于使用了teacher forcing,FAIR团队的模型不是循环一致的 - 让我们稍微看看这在实践中意味着什么。
teacher forcing是强化学习的一种形式。在训练期间,模型输入由前一个时间步的地面真值输出组成。在训练期间看到的序列是地面真值,因此是准确的,但是对于生成的样本来说可能不是这样。因此,生成的样本序列远离训练期间看到的序列。
虽然,如果他们真的不想这样,他们也可能会实现循环一致性损失系数,如Kaneko et. al。Kaneko et. al没有使用自回归模型,这有一些非常有趣的意义,我稍后会讲。
该团队还为每个输出领域使用了一个解码器,因为单个解码器显然无法令人信服地在输出域范围内执行。
来看这个更有趣的部分,FAIR团队使用了WaveNet。具体来说,是对NSynth数据集的WaveNet变体的改编。FAIR系统的不同之处在于:使用多个解码器,解析领域混淆网络,以及使用音调增强来阻止网络惰性记忆数据。
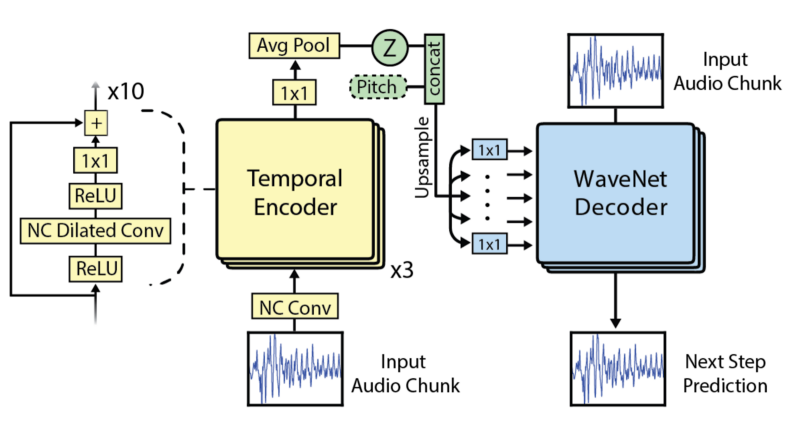
改编自“Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders”的WaveNet。
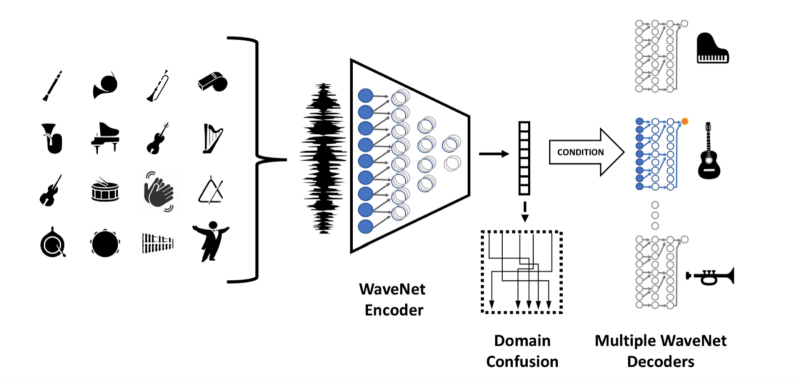
FAIR团队使用的实际模型。
让我们来看看这个领域混淆(domain confusion)。
论文“Domain-Adversarial Training of Neural Networks”描述了高效的领域迁移- 他们在当时达到了最先进的艺术表现,它们的原则是:“要实现有效的域名转移,预测必须根据无法区分训练(来源)和测试(目标)领域的特征做出。
FAIR团队使用对抗训练来做到这一点。WaveNet自动编码器是生成器,领域分类网络是鉴别器。将对抗性项添加到自动编码器的损失中可以鼓励自动编码器学习领域不变的潜在表示。这就是启用单个自动编码器的原因。
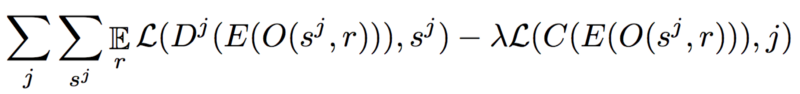
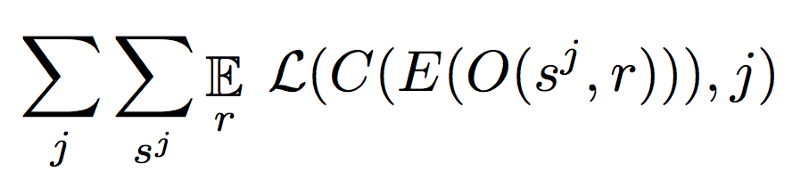
在上面的等式中可以看到很多东西,我们简要分析一下。
- L(y,y)是以元素方式应用于每个单独的y^和目标y的交叉熵损失。
- 解码器Dj是一种自回归模型,它取决于E的输出(共享编码器)。
- O(s ^ j,r)是应用于具有随机种子r的样本的增强函数。
- C是领域混淆网络,其被训练以最小化分类损失。
- λ:负责解析。它确保潜在表示中的所有神经元都在学习输入数据的不同内容。这是解析变分自动编码器的一个关键特性。
让我们来看看他们是如何训练的。
他们训练的领域代表了古典音乐中6种不同音色(音色:特定乐器的独特声音)和织体(织体:同时演奏的乐器和音符的数量)的传播。其中一个特别突出的结果是,自动编码器训练的嵌入和音高之间的相关性 - 相同音高的乐器余弦相似度在0.90-0.95范围内。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消