


















机器学习项目:建立一个酒店推荐引擎
所有在线旅行社都在争先恐后地满足亚马逊和网飞(Netflix)设定的AI驱动的个性化标准。此外,在线旅游已经成为一个竞争激烈的领域,品牌试图通过推荐,对比,匹配和分享来吸引我们的注意力(和钱包)。
在本文中,我们的目标是为在Expedia上搜索预定酒店的用户创建最佳的酒店推荐。我们将此问题建模为多类别的分类问题,并构建SVM和决策树集成的方法,根据用户的搜索细节,预测用户可能预定酒店的簇(cluster)。
数据
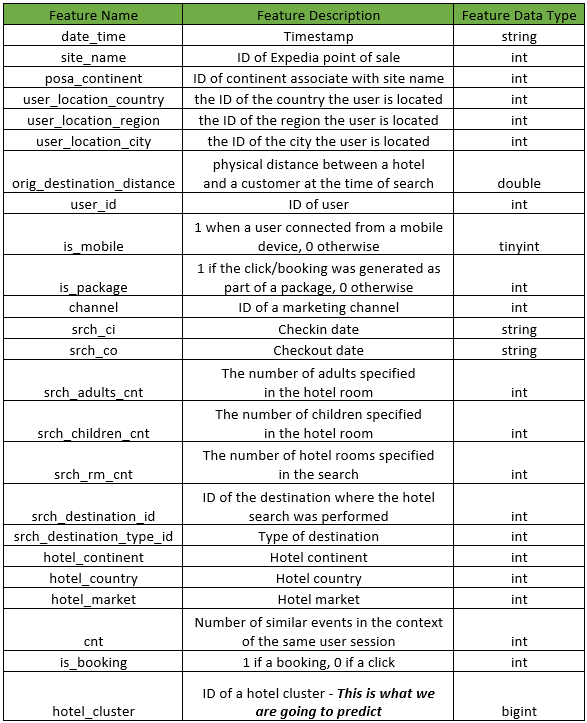
数据是匿名的,几乎所有字段都是数字格式。数据集可以在Kaggle上找到(链接在文末),我们将使用train.csv捕获用户行为的日志,destination.csv包含包含用户对酒店评论的相关信息。
下面的图提供了train.csv的概要:
下面的图提供了destinations.csv的概要:

import datetime
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
from sklearn import svm
为了能够在本地处理,我们随机抽取样本为记录的1%。然后,我们有241,179条记录。
df = pd.read_csv('train.csv.gz',sep =',')。dropna()
dest = pd.read_csv('destinations.csv.gz')
df = df.sample(frac = 0.01,random_state = 99)
df.shape
(241179,24)
EDA
目标是根据用户搜索中的信息预测用户将预订哪个hotel_cluster。共有100个簇。换句话说,我们正在处理100个类的分类问题。
plt.figure(figsize =(12,6))
sns.distplot(df ['hotel_cluster'])
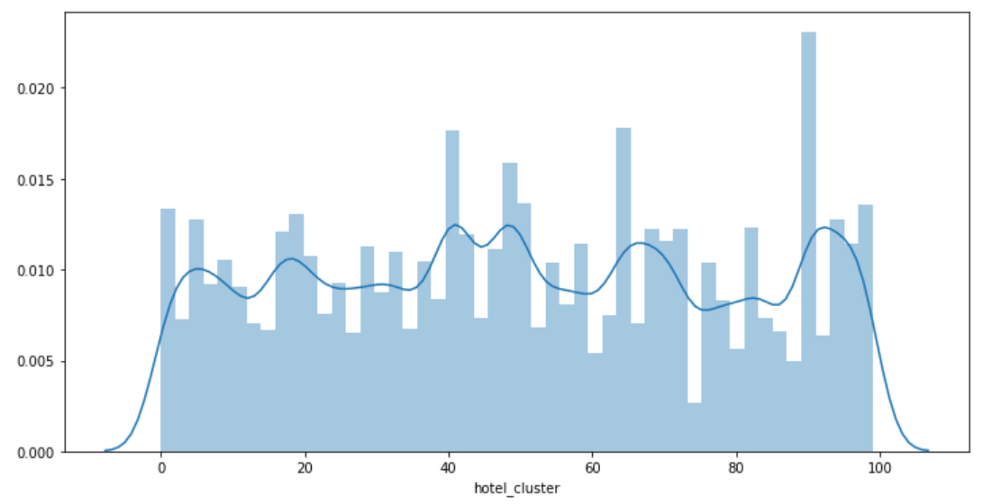
数据非常好地分布在所有100个簇上,并且数据是偏态的。
特征工程
日期时间,签入日期和签出日期列不能直接使用,我们将从中提取年份和月份。首先,我们定义了几个函数来实现它,我们还定义了一个合并destination.csv的函数。
from datetime import datetime
def get_year(x):
if x is not None and type(x) is not float:
try:
return datetime.strptime(x, '%Y-%m-%d').year
except ValueError:
return datetime.strptime(x, '%Y-%m-%d %H:%M:%S').year
else:
return 2013
pass
def get_month(x):
if x is not None and type(x) is not float:
try:
return datetime.strptime(x, '%Y-%m-%d').month
except:
return datetime.strptime(x, '%Y-%m-%d %H:%M:%S').month
else:
return 1
pass
def left_merge_dataset(left_dframe, right_dframe, merge_column):
return pd.merge(left_dframe, right_dframe, on=merge_column, how='left')
处理date_time列:
df['date_time_year'] = pd.Series(df.date_time, index = df.index)
df['date_time_month'] = pd.Series(df.date_time, index = df.index)
from datetime import datetime
df.date_time_year = df.date_time_year.apply(lambda x: get_year(x))
df.date_time_month = df.date_time_month.apply(lambda x: get_month(x))
del df['date_time']
处理srch_ci列:
df['srch_ci_year'] = pd.Series(df.srch_ci, index=df.index)
df['srch_ci_month'] = pd.Series(df.srch_ci, index=df.index)
# convert year & months to int
df.srch_ci_year = df.srch_ci_year.apply(lambda x: get_year(x))
df.srch_ci_month = df.srch_ci_month.apply(lambda x: get_month(x))
# remove the srch_ci column
del df['srch_ci']
处理srch_co列:
df['srch_co_year'] = pd.Series(df.srch_co, index=df.index)
df['srch_co_month'] = pd.Series(df.srch_co, index=df.index)
# convert year & months to int
df.srch_co_year = df.srch_co_year.apply(lambda x: get_year(x))
df.srch_co_month = df.srch_co_month.apply(lambda x: get_month(x))
# remove the srch_co column
del df['srch_co']
初步分析
在创建新特征并删除无用的特征之后,我们想知道是否有任何与hotel_cluster相关的内容。这可以让我们了解是否应该更加关注某些特定的特征。
df.corr()[ “hotel_cluster”]。sort_values()
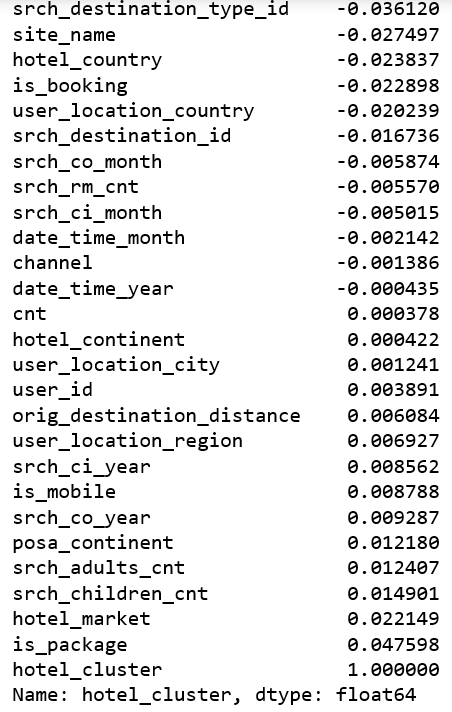
没有列与hotel_cluster线性相关,这意味着对特征之间的线性关系建模的方法可能不适合该问题。
策略
经过简单的谷歌搜索,不难发现,对于已知的搜索目的地组合,酒店所在国家,酒店的行情肯定有助于找到酒店簇。我们这样做:
pieces = [df.groupby(['srch_destination_id','hotel_country','hotel_market','hotel_cluster'])['is_booking'].agg(['sum','count'])]
agg = pd.concat(pieces).groupby(level=[0,1,2,3]).sum()
agg.dropna(inplace=True)
agg.head()

agg ['sum_and_cnt'] = 0.85 * agg ['sum'] + 0.15 * agg ['count']
agg = agg.groupby(level = [0,1,2])。apply(lambda x:x.astype( float)/x.sum())
agg.reset_index(inplace = True)
agg.head()
agg_pivot = agg.pivot_table(index = ['srch_destination_id','hotel_country','hotel_market'],columns ='hotel_cluster',values ='sum_and_cnt')。reset_index()
agg_pivot.head()

合并目标表和新创建的聚合数据透视表。
df = pd.merge(df,dest,how ='left',on ='srch_destination_id')
df = pd.merge(df,agg_pivot,how ='left',on = ['srch_destination_id','hotel_country',' hotel_market'])
df.fillna(0,
inplace = True)df.shape
(241179,276)
实现算法
我们只关注预订活动。
df = df.loc [df ['is_booking'] == 1]
获取特征和标签。
X = df.drop(['user_id', 'hotel_cluster', 'is_booking'], axis=1)
y = df.hotel_cluster
随机森林分类器
我们通过k折交叉验证报告性能度量,而Pipeline可以更轻松地组成估计量。
clf = make_pipeline(preprocessing.StandardScaler(),RandomForestClassifier(n_estimators = 273,max_depth = 10,random_state = 0))
np.mean(cross_val_score(clf,X,y,cv = 10))
0.24865023372782996
SVM分类器
SVM非常耗时。但是,我们取得的成绩更好。
from sklearn import svm
clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(decision_function_shape='ovo'))
np.mean(cross_val_score(clf, X, y, cv=10))
0.3228727137315005
Github:https://github.com/susanli2016/Machine-Learning-with-Python/blob/master/Hotel%20recommendation.ipynb
数据集:https://www.kaggle.com/c/expedia-hotel-recommendations/data









