Kaggle的入门介绍:通过竞赛磨练机器学习技能
2018年08月29日 由 yuxiangyu 发表
95642
0
在数据科学领域,可用的资源非常的多:从Datacamp到Udacity再到KDnuggets,在网上有很多可以在线学习数据科学的地方。但是,如果你是一个喜欢在实践中学习的人,那么Kaggle可能是让你通过实践数据科学项目提高自己的最佳地点。
Kaggle最初被称为机器学习竞赛的地方,它自称是“数据科学的家”,提供了很多数据科学的资源。本系列文章专注于竞赛,但值得指出Kaggle的主要方面:
- 数据集: 你可以免费下载和使用数以万计的不同类型和大小的数据集。如果你正在寻找有趣的数据来探索或测试你的建模技能,那么它一个好地方。
- 机器学习竞赛: 曾经是Kaggle的核心,这些建模技能的测试是学习尖端机器学习技术的好方法,它可以使用真实数据磨练你处理问题的能力。
- 学习: Jupyter Notebook中教授了一系列数据科学学习课程,涵盖SQL到深度学习。
- 讨论: 一个可以向Kaggle社区的数千名数据科学家提出问题和获取建议的地方。
- 内核(Kernels): 在Kaggle服务器上运行的在线编程环境,你可以在其中编写Python / R脚本或Jupyter notebook。这些内核完全免费运行(你甚至可以添加GPU)并且是一个很好的资源,因为你不必费心在自己的计算机上设置数据科学环境。内核可用于分析任何数据集,参与机器学习竞赛或完成学习。你可以复制和构建来自其他用户的已有的内核,并与社区共享你的内核以获得反馈。

总而言之,Kaggle是一个学习的好地方,无论是通过更传统的学习方式还是通过参加竞赛学习的方式。当我想了解最新的机器学习方法时,我可以去读一本书,但更可以去Kaggle上参加一个竞赛,看看人们如何在实践中使用它。对我来说,我觉得这种方法更有趣,也是一种更有效的教学方法。此外,社区非常支持并且总是愿意回答问题或者提供项目的反馈。
在本文中,我们将重点介绍Kaggle机器学习竞赛的起点: 家庭信用违约风险问题(the Home Credit Default Risk problem)。这是一个非常简单的竞赛,具有合理大小的数据集(不是哪个竞赛都是如此),这意味着我们可以完全使用Kaggle的内核进行竞赛。这大大降低了准入门槛,因为你不必操心计算机上的任何软件,甚至不必下载数据!只要你拥有Kaggle帐户和网络连接,就可以连接到内核并运行代码。
我打算在Kaggle和内核(Python Jupyter Notebook)上进行整个竞赛。你可以通过创建Kaggle帐户来复制内核,然后点击蓝色的Fork Notebook按钮。这将打开notebook在内核环境中进行编辑和运行。
竞赛文章:https://www.kaggle.com/willkoehrsen/start-here-a-gentle-introduction?utm_medium=blog&utm_source=wordpress&utm_campaign=gettingstarted-20180823
竞赛说明
家庭信用违约风险竞赛是一项标准的监督机器学习任务,目标是使用历史贷款申请数据来预测申请人是否会偿还贷款。在训练期间,我们为模型提供了特征(描述贷款申请的变量)以及标签(如果贷款得到偿还,则用二进制0表示,如果贷款没有得到偿还,则用1表示) 模型将学习从特征到标签的映射标签。然后,在测试期间,我们为模型提供新一批申请的特征,并要求它预测标签。
本次竞赛的所有数据都是结构化的,这场竞赛的所有数据都是结构化的,这意味着它存在于整齐的行和列中,就像电子表格一样。也意味着我们不需要使用任何卷积神经网络(它擅长处理图像数),而且它将为我们在真实数据集上提供很好的实践。
竞赛的主办方Home Credit是一家专注于为无银行存款人群提供服务的金融机构。预测申请的贷款是否会被偿还是一项重要的业务需求,Home Credit已经开发这项竞赛,希望Kaggle社区能够为此任务开发出有效的算法。本次竞赛遵循大多数Kaggle竞赛的总体思路:公司有数据和需要解决的问题,不去聘请内部数据科学家建立模型,而是提出了适度的奖励来吸引全世界的人来贡献解决方案。一个由数千名技术熟练的数据科学家组成的社区随后就这个问题进行研究,基本上不收取任何费用来提出最佳解决方案。就具有成本效益的商业计划而言,这是一个绝妙的主意!
Kaggle竞赛环境
当你去竞赛主页时,你会看到:
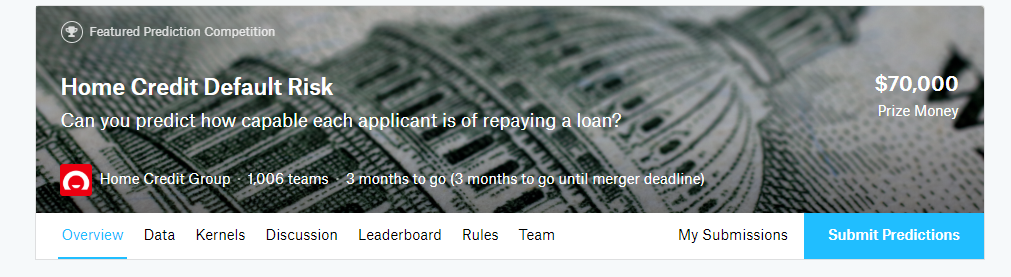
选项卡如下:
- Overview:对问题、评价标准、奖励和时间的简要描述
- Data: 所有竞赛所需的数据都不允许作为外部数据。你可以下载所有数据,但我们不需要这样做,因为我们使用可以连接到数据的Kaggle内核。
- Kernels: 你和其他竞争对手之前完成的工作。在我看来,这是竞赛最有价值的资源。你可以通读其他脚本和文档,然后复制代码(称为“分叉”)进行编辑和运行。
- Discussion: 另一个有用的资源,你可以从竞争主机和其他竞争对手中找到会话。这是一个问问题和从别人的答案中学习的好地方。
- Leaderboard: 可以看到谁在上面,或者你在哪里。
- Rules: 不是很有趣,但很好理解
- Team: 如果你决定组建团队,可以在此管理团队成员
- My Submissions: 查看你之前提交的内容,并选择最终用于竞赛的那个
向他人学习的重要性
尽管被称为竞赛,但是Kaggle机器学习项目应该被称为“协作项目”,因为主要目的不一定是赢,而是实践和向同行数据科学家学习。如果你能意识到战胜别人并不重要,重要的是提高自己的技能,你就会从比赛中收获更多。当你注册Kaggle时,你不仅获得了所有资源,还成为了数据科学家社区的一员。
通过努力成为社区的积极参与者,充分利用所有这些经验!从共享内核到在讨论论坛中提问。尽管让你的工作的公开可能会使你胆怯,但我们通过犯错,收到反馈和改进来学习,这样我们就不会再犯同样的错误了。每个人一开始都是新手,社区非常支持各种技能水平的数据科学家。
在这种心态下,我想强调的是,与他人讨论和构建他人代码不仅是可以接受的,而且是被鼓励的!在学校里,与他人合作被称为作弊,但在现实世界中,这被称为协作,是一项极其重要的技能。
将自己投入竞赛的一个很好的方法是找到一个较好排名的共享的内核,分叉内核,编辑它以尝试提高分数,然后运行它来查看结果。然后,将内核公开,以便其他人可以使用你的工作。 数据科学家不是站在巨人的肩膀上,而是以成千上万为了所有人的利益而公开工作的人作为后盾。
第一个notebook
现在,你对Kaggle的工作方式有了基本的了解,也了解了如何充分利用竞赛的理念,是时候开始了。在这里,我将简要概述一个Python Jupyter notebook,我把它放在内核中用于家庭信贷违约风险问题,但想要更多的受益,你需要将notebook分配到Kaggle并自己运行(你不要我必须下载或设置任何东西,所以我强烈建议你了解它)。
当你在内核中打开Notebook时,你将看到以下环境:
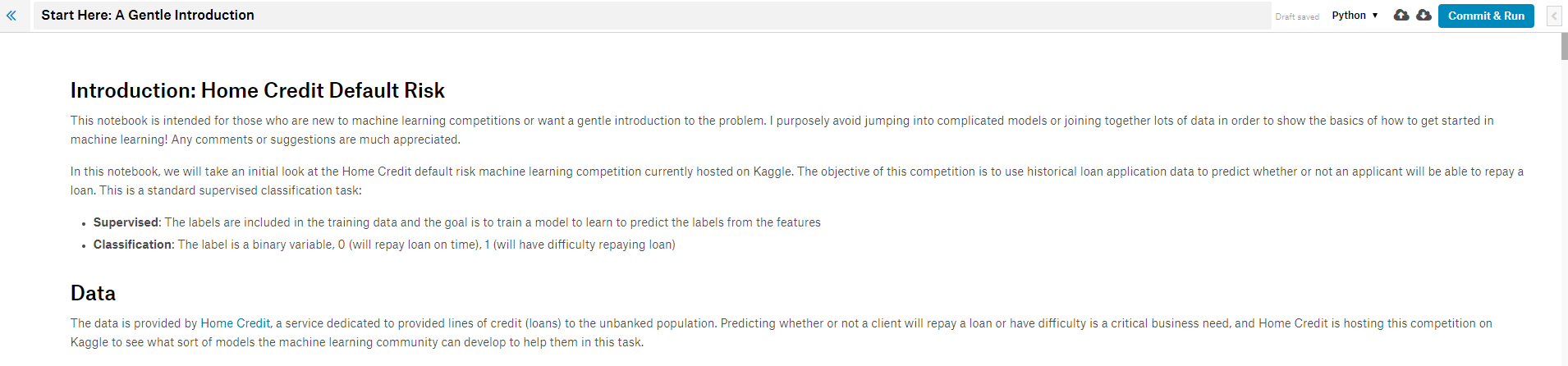
可以将其视为标准的Jupyter Notebook。你可以像在Jupyter中一样编写Python代码和文本(使用标记语法),并完全在Kaggle的服务器(云中)上运行代码。但是,Kaggle内核具有Jupyter Notebook中没有的一些独特功能。点击右上角的左箭头展开内核控制面板,调出三个标签(如果notebook不是全屏,那么这三个标签可能已经显示了)。
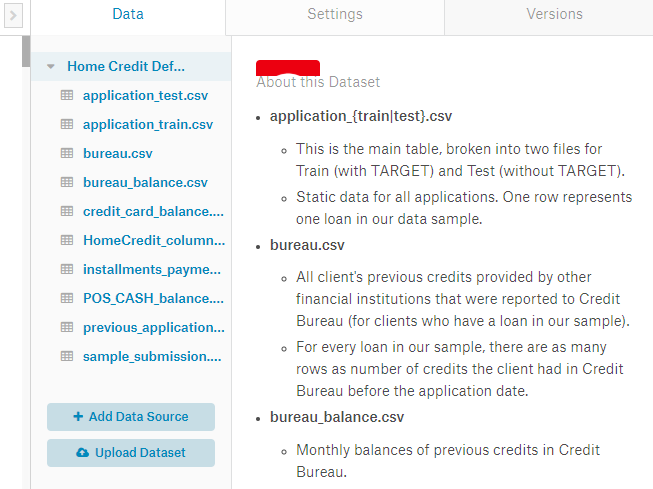
在data选项卡中,我们可以查看内核所连接的数据集。在这种情况下,我们拥有完整的竞赛数据。当然,我们也可以连接到Kaggle上的任何其他数据集或上传我们自己的数据并在内核中访问它。数据文件在../input/ 的目录中,代码如下:
import os
# List data files that are connected to the kernel
os.listdir('../input/')

连接到内核的文件可在../input/中找到
Settings选项卡允许我们控制内核的不同技术方向。在这里,我们可以在会话中添加GPU,更改可见性,并安装任何尚未在环境中使用的Python包。
最后,Versions选项卡可以让我们看到以前提交的代码的任何运行。我们可以查看对代码的更改,查看运行的日志文件,查看运行生成的notebook,以及下载从运行中输出的文件。
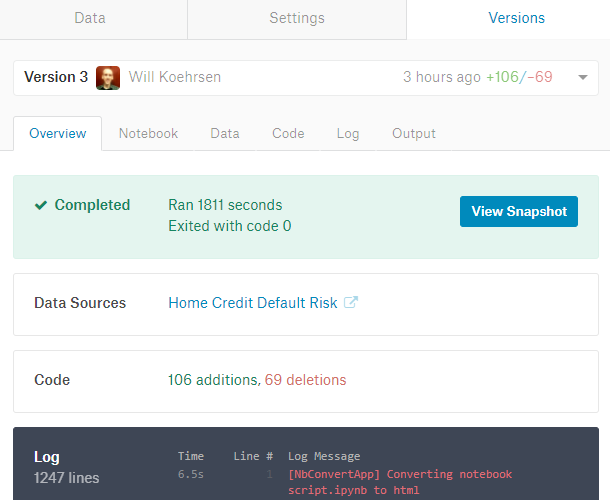
要运行整个notebook并记录新版本,请点击内核右上角的蓝色Commit&Run按钮。这将执行所有代码,向我们显示运行完成的notebook (如果有错误,则显示出现的错误),并保存在运行期间创建的所有文件。当我们提交notebook时,我们可以访问我们的模型所做的任何预测并提交它们进行评分。
介绍notebook大纲
第一个notebook旨在让你熟悉这个问题。我们开始的方式和任何数据科学问题一样:理解数据和任务。对于这个问题,有1个主要训练数据文件(包含标签),1个主要测试数据文件和6个额外的数据文件。在第一个notebook中,我们只使用主要数据,这将得到一个不错的分数,但后来的工作将必须包含所有数据(这样才更有竞争力)。
要理解数据,不要直接动手,首先花几分钟阅读问题文档,例如每个数据文件的列描述。因为有多个文件,我们需要知道它们是如何连接在一起的,尽管为了简单起见第一个notebook我们只使用主文件。阅读其他内核也可以帮助我们熟悉数据以及哪些变量是重要的。
一旦我们理解了数据和问题,我们就可以开始为机器学习任务构建它。这意味着处理分类变量(通过独热编码),填充缺失值(imputation),并将变量缩放到一个范围。我们可以进行探索性的数据分析,例如查找与标签的相关性,以及绘制这些关系。
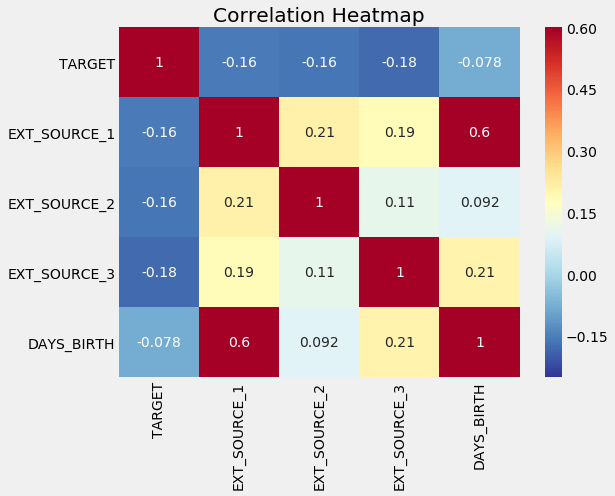
变量相关的热图
我们稍后可以使用这些关系来建模决策,例如包括要使用的哪些变量。(请参阅notebook 实施)。
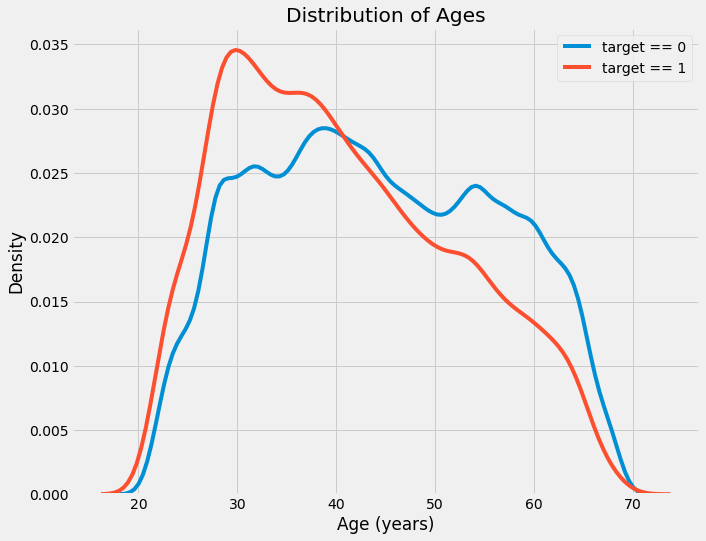
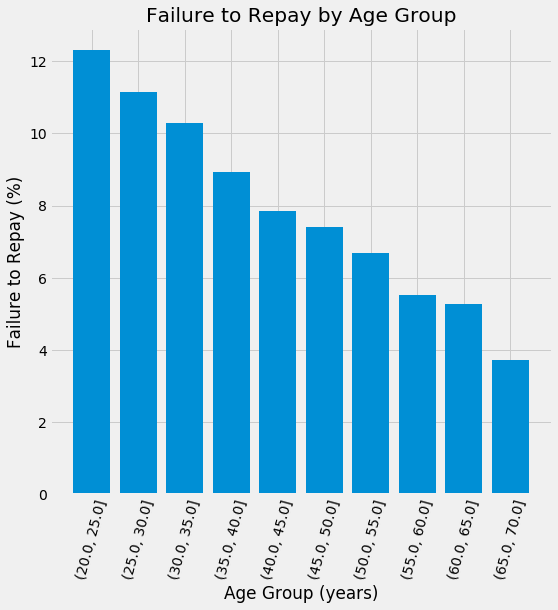
按标签显示的年龄分布(左)及按年龄组别划分的违约率(右)
当然,没有我最喜欢图(Pairs Plot),任何探索性数据分析都是不完整的。
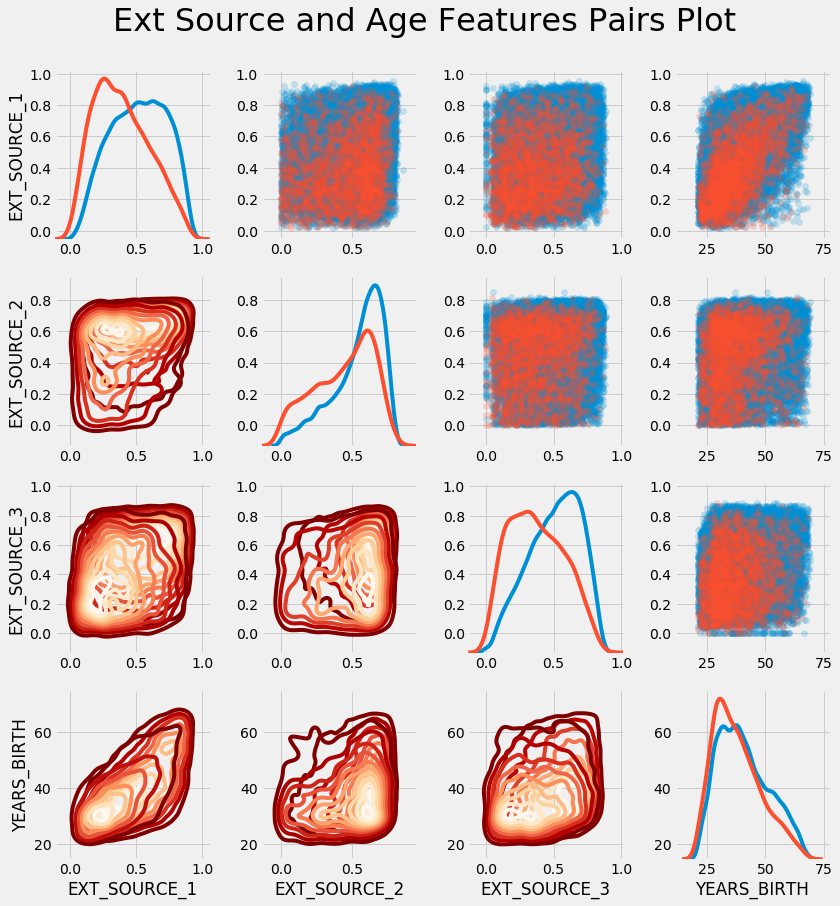
红色表示kde和散点图中未偿还的贷款
在彻底探索数据并确保机器学习可以接受这些数据之后,我们继续创建基线模型。但是,在我们完全进入建模阶段之前,我们必须了解竞赛的表现指标。在Kaggle竞赛中,一切都归结为单个数字,即测试数据的指标。
虽然使用二进制分类任务的准确性可能具有直观意义,但这是一个糟糕的选择, 因为我们正在处理类不平衡问题。因此提交的判定不是准确性而是根据ROC AUC(Receiver Operating Characteristic curve Area Under the Curve)。我建议让你对它进行研究,或者阅读notebook中的解释。至少要知道更高越好,随机模型得分为0.5,完美模型得分为1.0。为了计算ROC AUC,我们需要根据概率而不是二进制的0和1进行预测。 然后,ROC显示了将真实阳性概率率与假阳性概率为阈值的函数,据此,我们将实例分类为正。
通常我们喜欢做一个简单的基线预测,但是在这种情况下,我们已经知道对任务进行随机猜测的话ROC AUC为0.5。因此,对于我们的基线模型,我们将使用稍微复杂的方法,Logistic回归。这是一种流行的简单的二元分类算法,它将为未来的模型设置一个低标准(以便以后超过它)。
在实现逻辑回归之后,我们可以将结果保存为csv文件以进行提交。提交notebook时,我们编写的任何结果都将显示在Versions选项卡的Output 子选项卡中:
运行完整notebook的输出
在此选项卡中,我们可以将提交内容下载到我们的计算机,然后将其上传到竞赛中。在notebook 中,我们制作了四种不同模型,分数如下:
- Logistic回归:0.671
- 随机森林:0.678
- 具有构造特征的随机森林:0.678
- Light Gradient Boosting Machine:0.729
这些分数并没有让我们接近排行榜的顶端,但为未来的改进留下了空间!我们也得到了仅使用单一数据源可以获得的性能。
显然,Light Gradient Boosting Machine(使用LightGBM库)表现最佳。这个模型几乎赢得了每个结构化的Kaggle竞赛 (数据采用表格格式),如果我们想要真正的竞赛,可能需要使用这个模型的某种形式!
结论
本文主要展示了Kaggle竞赛的基本开端。并不是为了赢得胜利,而是为了向你展示如何进行机器学习竞赛的基础知识,以及一些让你开始实施的模型。
附:https://www.kaggle.com/willkoehrsen/start-here-a-gentle-introduction?utm_medium=blog&utm_source=wordpress&utm_campaign=gettingstarted-20180823




























