


















机器学习项目:使用Keras和tfjs构建血细胞分类模型
人工智能的应用非常广泛,尤其是在医疗领域。先进的人工智能工具可以帮助医生和实验室技术人员更准确地诊断疾病。例如,尼日利亚的一位医生可以使用这个工具从他根本不了解的血液样本中识别出一种疾病,这有助于他更好地理解疾病,从而可以更快地开发出治疗方法,这是人工智能民主化的一个优势,因为AI模型和工具可以在全世界范围内使用,尼日利亚的医生可以使用与麻省理工学院或世界上任何大学的研究学者使用的相同的工具和技术。
机器学习的主要问题:
机器学习是当今人工智能发展的主要组成部分。但民主化人工智能意味着建立一个允许任何人在世界各地使用相同的技术建立强大工具的基础设施。可能阻碍这点的两个主要问题是计算能力和训练数据集不可用。但这些问题正在被解决,比如:
- Kaggle(数据集的主页):数据集不可用是主要问题之一,但Kaggle是人们可以创建数据集并托管它们以供他人使用的最佳场所,人们已经使用这些工具构建了很多令人惊叹的东西。
- 谷歌合作实验室(colab):谷歌合作实验室是机器学习的主要驱动力,它允许任何拥有谷歌帐户的人访问GPU。如果没有这些GPU,很多人都无法训练需要大量计算的ML模型。
血细胞数据集
数据集就像数据科学家的金矿一样,如果数据集可用于特定问题,它可以减少工程团队所需的大量工作,因为不需要开发其他东西来收集和存储数据。几个月前我想到开发这个系统,Kaggle帮我获得了很多数据集。下面是我在Kaggle上找到的数据集,感谢Paul Mooney。
数据集:https://www.kaggle.com/paultimothymooney/blood-cells
数据集结构:数据集包含12,500个血细胞增强图像。数据集由4个类组成,如下所示:

血细胞数据集的类别
每个类包含3000个图像。该图显示了每个类的示例图像:
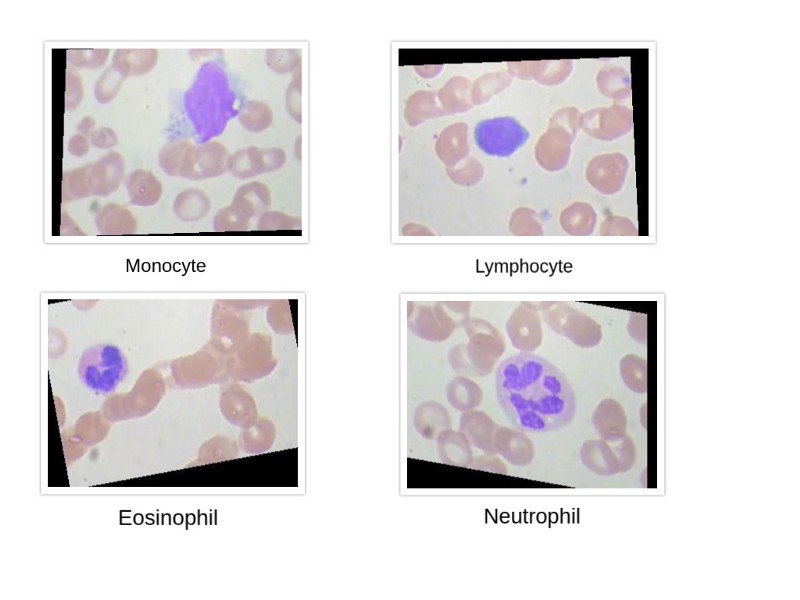
来自四个类的示例图像
我将每个图像的大小减小到(80x80x3),以便训练。
Kaggle要求在下载数据集之前登录,由于我们使用的是colab,不需要在本地计算机上下载数据集,直接将它拉到我们的google colab实例即可。
使用谷歌合作实验室
简单来说,谷歌colab提供了一个基于云的python notebook,其虚拟实例与GPU运行时相关联,谷歌colab的GPU运行时由NVIDIA k-80驱动,这是一款功能强大的GPU,价格昂贵。但是colab允许我们免费使用GPU而无需支付费用。实例的最长时间为12小时,12小时后实例将被销毁,新的实例将被创建,因此我们只能执行那些持续时间不超过12小时的计算。让我们看看我们如何使用colab来训练我们的神经网络。
使用Kaggle进行身份验证:
Kaggle CLI允许您下载数据集并将代码提交给竞赛。注册kaggle后,你可以下载包含所有凭证的kaggle.json文件,kaggle CLI使用这些凭证进行授权。
- 创建一个新单元格并创建一个名为.kaggle的隐藏目录,使用命令: !mkdir .kaggle
- 使用pip安装Kaggle CLI:在新单元格中 运行!pip install kaggle
- 下载数据集: !kaggle datasets download -d paulthimothymooney/blood-cells
- 确保下载的数据集中存在所有目录 :!ls dataset2-master/images
- 你应该看到3个目录:TEST,TEST_SIMPLE和TRAIN
- 目录TRAIN包含训练图像,我们将使用此目录图像进行训练。
预处理:
我们需要将图像加载为numpy数组并将其提供给我们正在训练的神经网络。我们将使用Keras构建神经网络,Keras提供了一个内置的ImageDataGenerator,它可以处理大多数预处理任务。
我们导入了开发模型所需的一些对象:
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Dropout, MaxPool2D, Flatten
from keras.preprocessing import image
keras.preprocessing提供了处理各种类型数据集所需的方法和对象。从image模块我们创建一个具有所有需配置的ImageDataGenerator。
generator = image.ImageDataGenerator(
rescale = 1./255,
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=10, # randomly rotate images in the range (degrees, 0 to 180)
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
vertical_flip=False)
如前所述,训练数据位于dataset2-master/images/TRAIN目录中,我们提供ImageDataGenerator的这条路径,以便我们所有的配置都应用于训练图像。
dataset = generator.flow_from_directory(
shuffle = True,
batch_size = 32,
target_size =(
80,80 ),directory ='dataset2-master / images / TRAIN'
)
这就是预处理,你可以通过减少或增加图像增强的效果来调整这些参数使其更适合,总有改进的余地。
CNN简介:
CNN(卷积神经网络)是一种神经网络,它包含一组卷积层和一个与之连接的前馈神经网络。卷积操作多年来一直用于图像处理。卷积操作的主要作用是从图像中提取边界,换句话说,它们可用于提取图像的重要特征,如果所谓的滤波值(Filter Value)已知,则任何人都无法识别任何图像的最佳滤波值,因为我们使用卷积和神经网络,梯度下降将自动优化滤波值以提取图像中最重要的特征。吴恩达的课程deeplearning.ai帮助你更好地理解这些网络的工作。
我们的网络:
此任务必须使用CNN,因为简单的前馈神经网络无法了解数据集的每个类中存在的独特特征。我们使用的CNN的架构如下所示:
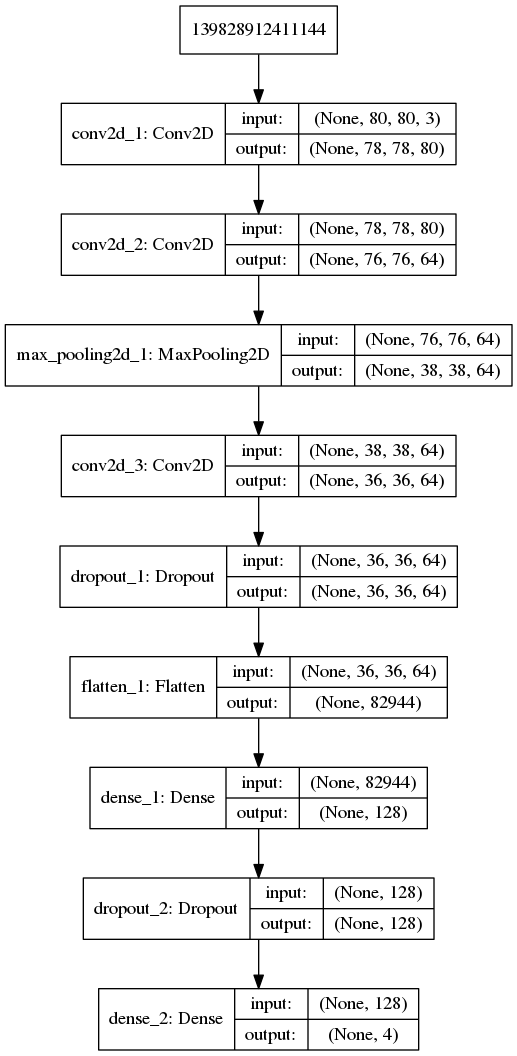
神经网络结构
我创建了一个函数model(),它返回一个序列模型,如下所示:
def model():
model = Sequential()
model.add(Conv2D(80, (3,3), strides = (1, 1), activation = 'relu'))
model.add(Conv2D(64, (3,3), strides = (1, 1), activation = 'relu', input_shape = (80, 80, 3)))
model.add(MaxPool2D(pool_size = (2,2)))
model.add(Conv2D(64, (3,3), strides = (1,1), activation = 'relu'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(4, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adadelta', metrics = ['accuracy'])
return model
最后我们训练模型:
nn = model()
nn.fit_generator(dataset,steps_per_epoch = None,epochs = 30,verbose = 1)
nn.save('Model.h5')
该模型经过30次的训练,获得了92.67%的准确性,这是一个很好的准确性,你可以添加更多层或执行超参数调整以提高准确性。
部署模型:
训练完成,我们需要将模型部署到生产环境中,以便每个人都可以使用它。有多种策略可用于部署机器学习系统。我想在客户端机器上运行完整的推理,所以我开始构建一个web应用程序来实现这一点。
设置必备的条件:
我们需要以下要求来构建客户端应用程序,该应用程序具有以下架构:
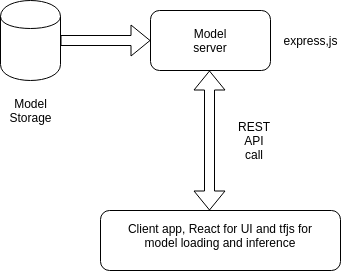
应用程序结构
安装节点和npm并设置环境,按相同顺序安装以下依赖项:
npm install -g create-react-app
create-react-app app_name
cd app_name
npm install --save @tensorflow/tfjs
//on server side:
mkdir server
cd server
npm init
//fill up the details, make sure package.json is created
npm install express --save
- 模型服务器:这是一个express.js REST端点,客户端可以通过发送REST GET请求来请求模型文件。(在服务器端)
let express = require('express')
let cors = require('cors')
let path = require('path')
var app = express()
let static_path = path.join(__dirname, 'ModelData/model_data')
app.use(cors())
app.use(express.static(static_path))
app.get('/model_metadata', (req, resp) => {
resp.sendFile(static_path+'/model.json')
})
app.listen(5443, () => console.log('Serving tfjs model on express API server'))- 模型存储:我们需要创建一个与tfjs兼容的模型,tensorflow提供了一个名为tensorflowjs的工具,它是一个包含实用程序的python工具包,我们可以使用pip命令来安装它:pip install tensorflowjs
完成后,我们可以使用tensorflowjs_converter使用以下命令将模型转换为tfjs格式:
$tensorflowjs_converter --input_format keras \
Model.h5 \
ModelData/model_data
// Model.h5 is the downloaded model after training, last argument is the target folder, where we need to store the model files.
转换后,它将创建一组名为shards的文件,它是通过基于层切片模型获得的,每个分片包含特定层的权重。使用切片非常有用,因为每个部分可以存储在不同的地方,并且可以在需要时下载,因此我们可以为我们的机器学习模型构建一个分布式存储。model.json是包含每片信息的文件。如果我们更改了切片的目录,我们可以修改此文件。在API调用中,我们只将model.json文件发送到客户端,tfjs将自动获取每个分片以,在客户端机器上组装一个模型。
最后一部分:客户端推理引擎的开发
在本节中,我不会过多地强调UI设计,而是强调推理部分,比如如何使用安装好的tfjs运行推理。转到react app目录。
- 创建一个模型容器类:我首先为我们的模型创建了一个包装类。此类的实例表示可以进行推理的模型。这个模型类的代码很好理解。
- 推理函数:我定义了一个可以取模型对象和输入图像源的函数,输入源可以是HTML img,也可以是URL,或图像的字节流。
代码如下所示:
var tensorflow = require('@tensorflow/tfjs')
class ModelContainer {
constructor(nn){
this.nn = nn
}
setWeights(weights){
//use json weights file
}
async loadFromURL(url){
console.log(url)
this.nn = await tensorflow.loadModel(url)
console.log(this.nn)
}
removeNetwork(){
this.nn = null
}
swapToNewObject(){
let new_nn = this.nn
this.nn = null
return new_nn
}
obtainMemorySafe(){
return this.swapToNewObject()
}
obtain(){
return this.nn
}
}
function runInference(modelContainer, imageData){
//perform a sawp, i.e obtain network object from container
imageData.style.width = "80px";
imageData.style.height = "80px";
let nn = modelContainer.obtainMemorySafe()
let pixels = tensorflow.fromPixels(imageData)
pixels = pixels.reshape([1, 80, 80, 3])
pixels.dtype = 'float32'
pixels = tensorflow.div(pixels, 255)
let predictions = nn.predict(pixels)
modelContainer.nn = nn
nn = null
return predictions.dataSync()
}
function afterPrediction(predictions){
//as of now
console.log(predictions)
}
export {ModelContainer, runInference, afterPrediction}- 初始化模型对象:我们现在必须创建包含推理模型的模型对象。
let modelCache = new ModelContainer (null);
modelCache.loadFromURL( 'http://192.168.0.105:5443/model_metadata')
- 运行推理:一旦我们有了一个模型对象,我们就可以随时运行推理。根据我设计的UI,只要用户点击predict按钮就应该执行推理。因此,运行预测的React组件部分如下所示:
() => {
let result = runInference(modelCache, document.getElementById('image_container'))
this.setState({
scores : this.computeScore(result),
show_result : true
})
}
}>Predict
//and computeScore function :
computeScore(predictions) {
let sum = 0;
for(var i = 0; i < predictions.length; i++) sum+=predictions[i]
//cumpute proportions
let proportions = []
for(var i = 0; i < predictions.length; i++){
let prop = (predictions[i] * 100)/sum
proportions.push(prop)
}
return {
EOSINOPHIL : proportions[0],
LYMPHOCYTE : proportions[1],
MONOCYTE : proportions[2],
NEUTROPHIL : proportions[3]
}
}
}
总结
这个项目对我来说真的很棒,我学会了如何使用谷歌colab在云上训练ML模型,我还学会了如何部署ML模型进行生产。这是一个开源项目,随时可以进行更改:
REPO URL: react-client(https://github.com/Narasimha1997/BloodCell-Identification-tfjs-client)
Cloud Notebook(适用于模型训练):training.ipynb(https://github.com/Narasimha1997/Blood-Cell-type-identification-using-CNN-classifier)









