











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用Scikit-Learn进行命名实体识别和分类(NERC)
2018年08月30日 由 yuxiangyu 发表
65803
0

命名实体识别和分类(NERC)是识别名称等信息单元的过程(包括人员,组织和位置名称),以及包括非结构化文本中的时间,日期,钱和百分比表达式等数值表达式。目标是开发实用且与域无关的技术,以便自动高精度地检测命名实体。
上周,我们介绍了NLTK和SpaCy中的命名实体识别(NER)。今天,我们更进一步,使用Scikit-Learn的一些库训练NER的机器学习模型。让我们开始吧!
数据
数据是IOB和POS标签注释的特征设计语料库(底部链接给出)。我们可以快速浏览前几行数据。
有关实体的基本信息:
- geo =区域实体(Geographical Entity)
- org =组织(Organization)
- per =人(Person)
- gpe =地缘政治实体(Geopolitical Entity)
- tim =时间指示器(Time indicator)
- art =人工制品(Artifact)
- eve =事件(Event)
- nat =自然现象(Natural Phenomenon)
Inside–outside–beginning(标记)
IOB (Inside–outside–beginning)是用于标记标志的通用标记格式。
- I-标签前的前缀表示标签位于块内。
- B-标签前的前缀表示标签是块的开头。
- O标记表示标志不属于任何块(outside)。
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.linear_model import Perceptron
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
整个数据集不能装入一台计算机的内存中,因此我们选择前100,000个记录,并使用外存学习算法(Out-of-core learning algorithm)来有效地获取和处理数据。
df = pd.read_csv('ner_dataset.csv',encoding =“ISO-8859-1”)
df = df [:100000]
df.head()
df.isnull().sum()

数据预处理
我们注意到“Sentence#”列中有很多NaN值,我们用前面的值填充NaN。
df = df.fillna(method ='ffill')
df ['Sentence#']。nunique(),df.Word.nunique(),df.Tag.nunique()
(4544,10922,17)
我们有4,544个句子,其中包含10,922个独特单词并标记为17个标签。
标签分布不均匀。
df.groupby('Tag').size().reset_index(name='counts')
以下代码使用DictVectorizer将文本转换为向量,然后拆分为训练和测试集。
X = df.drop('Tag',axis = 1)
v = DictVectorizer(sparse = False)
X = v.fit_transform(X.to_dict('records'))
y = df.Tag.values
classes = np.unique(y)
classes = classes.tolist()
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.33,random_state = 0)
X_train.shape,y_train.shape
((67000,15507),(67000,))
外存算法
我们将尝试一些外存算法,这些算法旨在处理太大而无法存入的单个计算机内存的数据(partial_fit 方法)。
感知机
per = Perceptron(verbose=10, n_jobs=-1, max_iter=5)
per.partial_fit(X_train, y_train, classes)

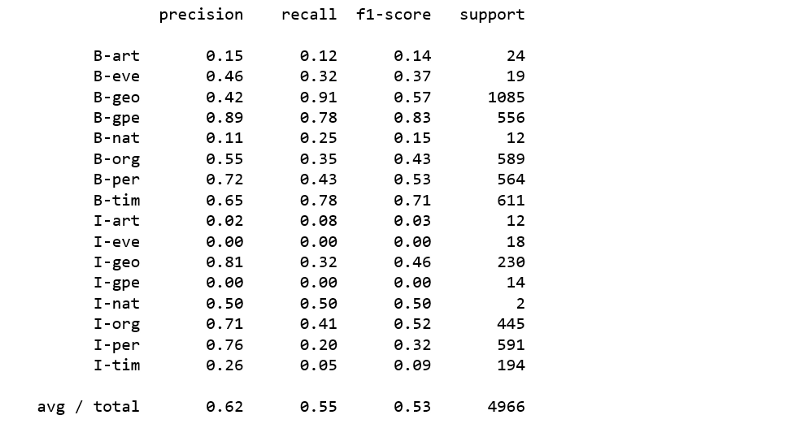
因为标签“O”(outside)是最常见的标签,它会使我们的结果看起来比实际更好。因此,当我们评估分类指标时,我们会删除标记“O”。
new_classes = classes.copy()
new_classes.pop()
new_classes

print(classification_report(y_pred = per.predict(X_test),y_true = y_test,labels = new_classes))
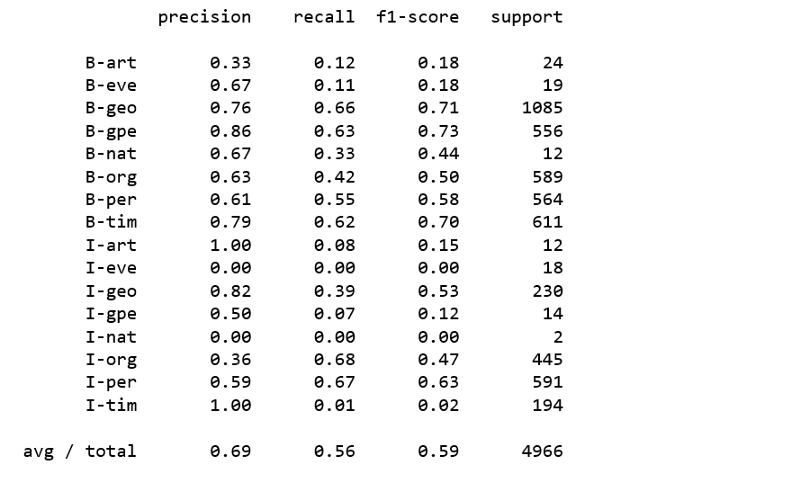
具有SGD训练的线性分类器
sgd = SGDClassifier()
sgd.partial_fit(X_train,y_train,classes)

print(classification_report(y_pred = sgd.predict(X_test),y_true = y_test,labels = new_classes))
用于多项模型的朴素贝叶斯分类器
nb =
MultinomialNB (alpha = 0.01)nb.partial_fit(X_train,y_train,classes)
print(classification_report(y_pred = nb.predict(X_test),y_true = y_test,labels = new_classes))
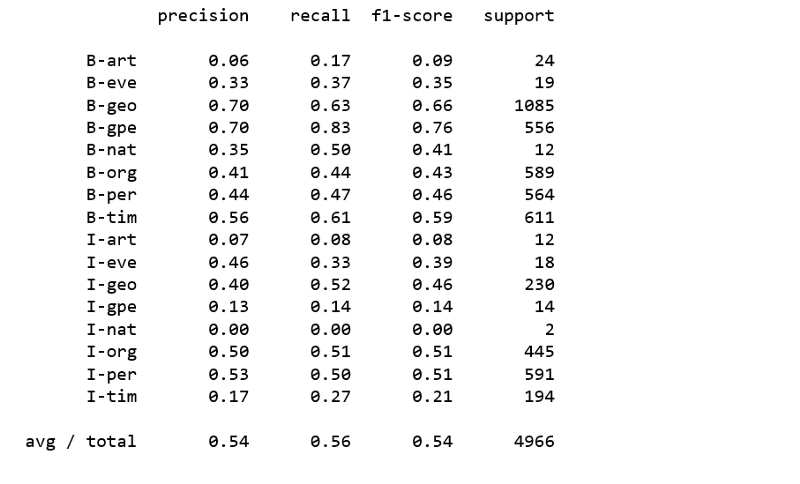
Passive Aggressive分类器
pa = PassiveAggressiveClassifier()
pa.partial_fit(X_train,y_train,classes)

print(classification_report(y_pred = pa.predict(X_test),y_true = y_test,labels = new_classes))
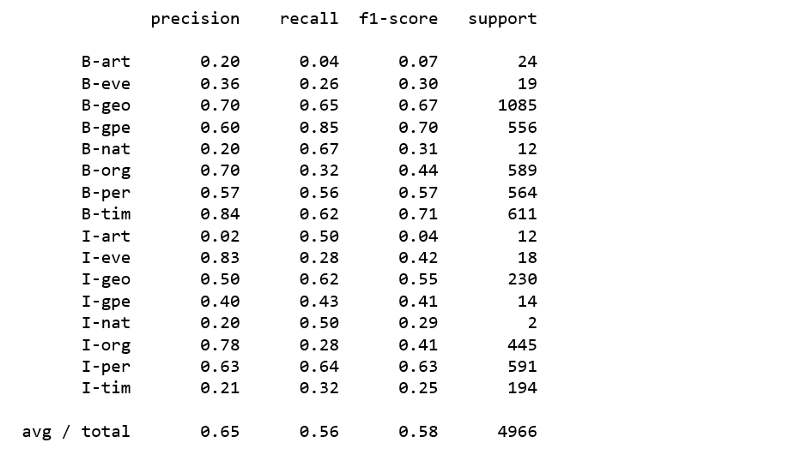
上述分类器均未产生令人满意的结果。显然,使用常规分类器对命名实体进行分类并不容易。
条件随机场(CRF)
CRF通常用于标记或解析序列数据,例如自然语言处理,并且CRF查找POS标记、命名实体识别等应用。
sklearn-crfsuite
我们将使用sklearn-crfsuite在我们的数据集上训练用于命名实体识别的CRF模型。
import sklearn_crfsuite
from sklearn_crfsuite import scorers
from sklearn_crfsuite import metrics
from collections import Counter
以下代码用于检索带有POS和标签的句子。
class SentenceGetter(object):
def __init__(self, data):
self.n_sent = 1
self.data = data
self.empty = False
agg_func = lambda s: [(w, p, t) for w, p, t in zip(s['Word'].values.tolist(),
s['POS'].values.tolist(),
s['Tag'].values.tolist())]
self.grouped = self.data.groupby('Sentence #').apply(agg_func)
self.sentences = [s for s in self.grouped]
def get_next(self):
try:
s = self.grouped['Sentence: {}'.format(self.n_sent)]
self.n_sent += 1
return s
except:
return None
getter = SentenceGetter(df)
sentences = getter.sentences
特征提取
接下来,我们提取更多特征(单词构成,简化的POS标签,下部/标题/上部标志,附近词的特征)并将它们转换为sklearn-crfsuite格式 - 每个句子应转换为词典列表。以下代码取自sklearn-crfsuites官网。
def word2features(sent, i):
word = sent[i][0]
postag = sent[i][1]
features = {
'bias': 1.0,
'word.lower()': word.lower(),
'word[-3:]': word[-3:],
'word[-2:]': word[-2:],
'word.isupper()': word.isupper(),
'word.istitle()': word.istitle(),
'word.isdigit()': word.isdigit(),
'postag': postag,
'postag[:2]': postag[:2],
}
if i > 0:
word1 = sent[i-1][0]
postag1 = sent[i-1][1]
features.update({
'-1:word.lower()': word1.lower(),
'-1:word.istitle()': word1.istitle(),
'-1:word.isupper()': word1.isupper(),
'-1:postag': postag1,
'-1:postag[:2]': postag1[:2],
})
else:
features['BOS'] = True
if i < len(sent)-1:
word1 = sent[i+1][0]
postag1 = sent[i+1][1]
features.update({
'+1:word.lower()': word1.lower(),
'+1:word.istitle()': word1.istitle(),
'+1:word.isupper()': word1.isupper(),
'+1:postag': postag1,
'+1:postag[:2]': postag1[:2],
})
else:
features['EOS'] = True
return features
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
return [label for token, postag, label in sent]
def sent2tokens(sent):
return [token for token, postag, label in sent]
拆分训练和测试集
X = [sent2features(s) for s in sentences]
y = [sent2labels(s) for s in sentences]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
训练CRF模型
crf = sklearn_crfsuite.CRF(
algorithm ='lbfgs',
c1 = 0.1,
c2 = 0.1,
max_iterations = 100,
all_possible_transitions = True
)
crf.fit(X_train,y_train)

评估
y_pred = crf.predict(X_test)
print(metrics.flat_classification_report(y_test,y_pred,labels = new_classes))
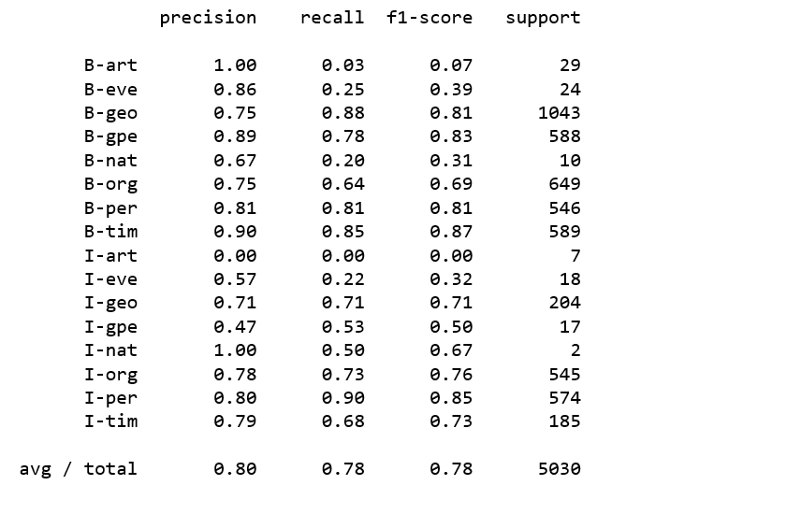
这种方式更好!我们将坚持sklearn-crfsuite并继续探索!
我们的分类器学到了什么?
def print_transitions(trans_features):
for (label_from, label_to), weight in trans_features:
print("%-6s -> %-7s %0.6f" % (label_from, label_to, weight))
print("Top likely transitions:")
print_transitions(Counter(crf.transition_features_).most_common(20))
print("\nTop unlikely transitions:")
print_transitions(Counter(crf.transition_features_).most_common()[-20:])
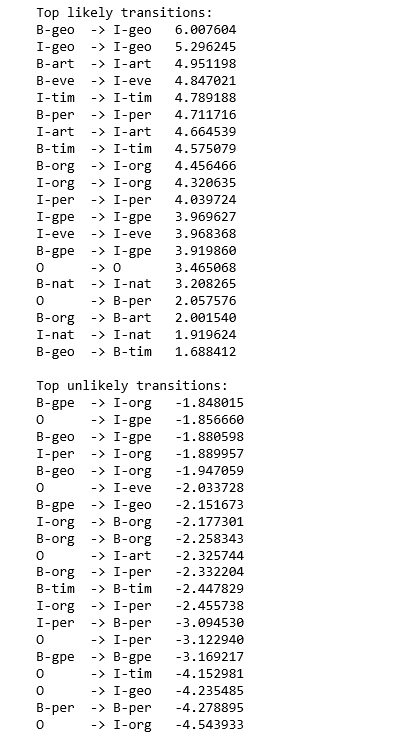
解释:很可能区域实体开头(B-geo)后面跟着内部区域实体(I-geo)的标志,但是从带有其他标签的标志转移到组织名称内部(I-org)会受到严厉惩罚。
检查状态特征
def print_state_features(state_features):
for (attr, label), weight in state_features:
print("%0.6f %-8s %s" % (weight, label, attr))
print("Top positive:")
print_state_features(Counter(crf.state_features_).most_common(30))
print("\nTop negative:")
print_state_features(Counter(crf.state_features_).most_common()[-30:])

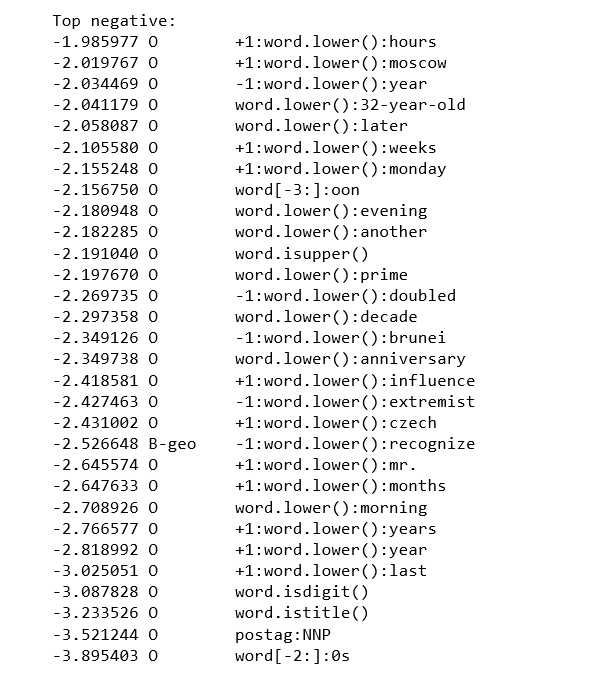
观察:
1)5.183603 B-tim word[-3]:day该模型得知如果附近的单词是“day”,则该标志可能是时间指示器的一部分。
2)3.370614 B-per word.lower():president该模型学到标志“president”可能位于人名的开头。
3)-3.521244 O postag:NNP该模型了解到专有名词通常是实体。
4)-3.087828 O word.isdigit()数字可能是实体。
5)-3.233526 O word.istitle()大写单词可能是实体。
ELI5
ELI5是一个Python包,可以检查sklearn_crfsuite.CRF模型的权重。
检查模型重量
import eli5
eli5.show_weights(crf,top = 10)
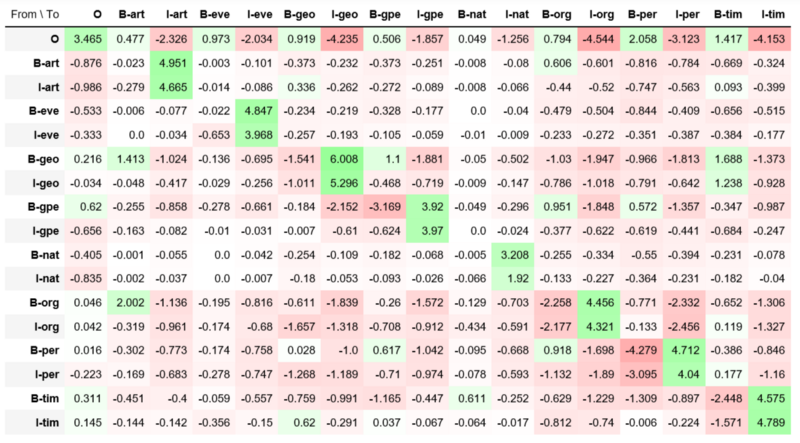
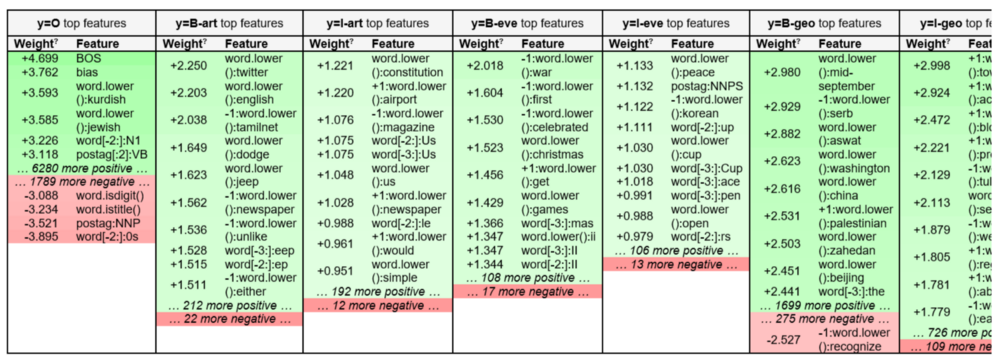
观察:
- I-entity必须跟着B-entity,例如I-geo跟着B-geo,I-org跟着B-org,I-per跟着B-per等等。
- 我们还可以看到,在这个数据集中,在组织名称后面有一个人并不常见(B-org - > I-per具有较大的负权重)。
- 该模型为不可能的过度学习了大的负权重,如O - > I-geo,O - > I-org和O - > I-tim等等。
为便于阅读,我们只检查一部分标签。
eli5.show_weights(crf,top = 10,targets = ['O','B-org','I-per'])
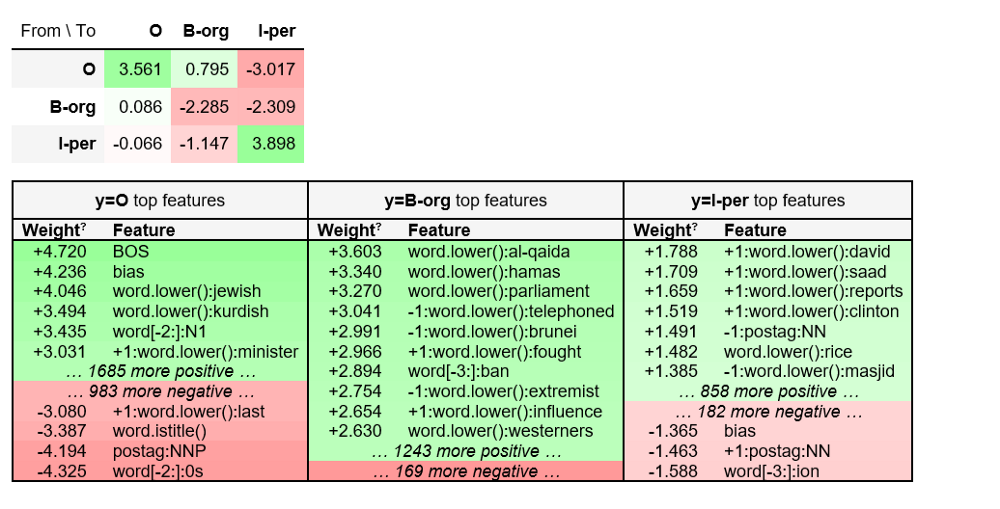
或者只检查所有标签的部分特征。
eli5.show_weights(crf,top = 10,feature_re ='^ word \ .is',
horizontal_layout = False,show = ['targets'])



源代码可以在Github找到。
Github:https://github.com/susanli2016/NLP-with-Python/blob/master/NER_sklearn.ipynb
数据:https://www.kaggle.com/abhinavwalia95/how-to-loading-and-fitting-dataset-to-scikit/data

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消