











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用多种工具组合进行分布式超参数优化
2018年08月31日 由 yuxiangyu 发表
470209
0
在这篇文章中,我介绍如何使用工具组合来加速超参数优化任务。这里提供了Ubuntu的说明,但可以合理地应用于任何*nix系统。
什么是超参数优化?
超参数优化(HO)是一种为机器学习任务选择最佳参数的方法。这些参数包括:
- 层数
- 学习率
- 批量大小
- 层的类型
- Dropout
- 优化算法(SGD,Adam,rmsprop等)
对于任何给定的问题,什么样的网络配置最适合于给定的任务可能不那么明显,因此我们可以使用超参数优化,通过智能地迭代你想要优化的参数的搜索空间来为我们决定。Hyperopt使用Tree-Structure Parzen估计器,非常擅长快速确定最佳参数集。它的工作原理是运行和评估模型,返回损失分数,然后运行另一个参数略有不同的模型,旨在最大限度地减少误差分数。对你来说困难的部分是为你的问题设计一个搜索空间,这可能非常大。为了节省时间,我们可以在任意数量的机器上同时运行这些模型,甚至让每台机器运行多个模型(前提是它有足够的内核)。
幸运的是,有些python库可以帮助我们完成所有这些工作!
要求
你会需要:
- 安装了以下Python包
- theano,tensorflow或tensorflow-gpu
- hyperopt
- hyperas
- pymongo
- PSSH
- 安装了以上所有的几台机器
- 一个带有jobs数据库的Mongodb实例
我强烈建议使用pyenv来使用最新版本的python,并防止我们安装的包与系统包冲突。如果你可以访问所有计算机可用的网络驱动器,请设置$PYENV_ROOT为这些计算机所有文件都可见(或至少在所有计算机上都有一个公共路径)。安装所用的库(你可以使用你想要使用的任何keras后端交换tensorflow,如theano tensorflow-gpu tensorflow cntk):
export PYENV_ROOT="$HOME/.pyenv"
curl -L https://github.com/pyenv/pyenv-installer/raw/master/bin/pyenv-installer | bash
echo 'export PATH="$HOME/.pyenv/bin:$PATH"' >> ~/.bash_profile
echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
source ~/.bash_profile
sudo apt install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev xz-utils tk-dev
env PYTHON_CONFIGURE_OPTS="--enable-shared" MAKEOPTS="-j 8" pyenv install 3.6.5
pyenv local 3.6.5
pip install tensorflow git+https://github.com/hyperopt/hyperopt git+https://github.com/maxpumperla/hyperas keras pssh matplotlib h5py pymongo
你现在将拥有一个自包含的python安装在$HOME/.pyenv/versions/3.6.5。请记住,它需要构建一个python安装,因此可能需要一段时间。你可以将~/.pyenv文件夹复制到要运行的任何计算机上。只需记住将你的~/.bash_profile(或其他与此相同的)复制到你想要作为“工作者”的每台机器上。
代码
我们还需要选择一项优化任务!Hyperas使用模板生成hyperopt可以使用的代码,因此你需要严格遵循这个模板。创建一个名为optimise_task.py的文件。我们将找到单层稠密网络的最佳的层数和dropout参数(在搜索空间内,参见l1_size和l1_dropout变量)来解决MNIST任务。不同参数分布的文档在这里:https://github.com/hyperopt/hyperopt/wiki/FMin#21-parameter-expressions
为达到我们的目的:
- quniform是具有给定间隔和步长的离散值的正态分布。在我们的示例中,它将返回范围[12,256]中的浮点数,step=4
- uniform是连续值的正态分布
Hyperas.distributions中提供了更多可用的分布:https://github.com/maxpumperla/hyperas/blob/master/hyperas/distributions.py
from hyperas import optim
from hyperas.distributions import quniform, uniform
from hyperopt import STATUS_OK, tpe, mongoexp
import keras
from keras.layers import Dense, Dropout
from keras.models import Sequential
from keras.optimizers import RMSprop
from keras.datasets import mnist
import tempfile
from datetime import datetime
def data():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
num_classes = 10
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
return x_train, y_train, x_test, y_test
def create_model(x_train, y_train, x_test, y_test):
"""
Create your model...
"""
l1_size = {{quniform(12, 256, 4)}}
l1_dropout = {{uniform(0.001, 0.7)}}
params = {
'l1_size': l1_size,
'l1_dropout': l1_dropout
}
num_classes = 10
model = Sequential()
model.add(Dense(int(l1_size), activation='relu'))
model.add(Dropout(l1_dropout))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
start = datetime.now()
model.fit(x_train, y_train, batch_size=128, epochs=10, validation_data=(x_test, y_test))
score, acc = model.evaluate(x_test, y_test, verbose=0)
out = {
'loss': -acc,
'score': score,
'status': STATUS_OK,
'duration': (datetime.now() - start).total_seconds(),
'ho_params': params,
'model_config': model.get_config()
}
# optionally store a dump of your model here so you can get it from the database later
temp_name = tempfile.gettempdir()+'/'+next(tempfile._get_candidate_names()) + '.h5'
model.save(temp_name)
with open(temp_name, 'rb') as infile:
model_bytes = infile.read()
out['model_serial'] = model_bytes
return out
if __name__ == "__main__":
trials = mongoexp.MongoTrials('mongo://username:pass@mongodb.host:27017/jobs/jobs', exp_key='mnist_test')
best_run, best_model = optim.minimize(model=create_model,
data=data,
algo=tpe.suggest,
max_evals=10,
trials=trials,
keep_temp=True) # this last bit is important
print("Best performing model chosen hyper-parameters:")
print(best_run)
请注意实验密钥的名称:mnist_test,这将是mongodb中jobs数据库的jobs集合的密钥。每个模型完成后,它将存储在mongodb中。可以将权重存储在输出文档中(输出model.get_weights(),但是mongodb每个文档的限制为4MB。为了解决这个问题,GridFS用于在模型本身的数据库中临时存储blob。
我也将持续时间存储在result对象中,因为你可能会发现两个损失非常相似的模型,但损失稍微好一些的模型可能会有更高的运行时间。
运行
运行它有两个部分:
- 试验控制器,它决定每个模型运行时将使用的参数
- 实际运行单个模型的工作者
调节器
从计算机运行它(它必须在所有jobs运行时处于活动状态):
python optimise_task.py
你应该得到一个调用的输出文件temp_model.py(如果你没有,请确保你已经更新到github的最新hyperas代码)。确保该文件对工作者可见。
工作者
工作者是你的所有其他机器(也可能包括控制器机器)。确保你安装了pyenv,只需压缩.pyenv文件夹并将其复制到工作机器上的主目录并解压即可。这样你就不会错过任何依赖。
运行以下命令:
mkdir hyperopt_job
touch hyperopt_job/job.sh
chmod +x hyperopt_job/job.sh
将temp_model.py文件复制到hyperopt_job文件夹中( ~/hyperopt_job/job.sh):
#!/bin/bash
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
export PYTHONPATH=~/hyperopt_job/
cd ~/hyperopt_job
pyenv local 3.6.5
hyperopt-mongo-worker --mongo="mongo://username:password@mongodb.host:27017/jobs" --exp-key=mnist_test
现在你可以在你的工作机器上运行~/hyperopt_job/job.sh了!请记住,他们需要能够访问mongodb。工作者继续运行,直到你达到max_evals末尾定义的optimise_task.py。
如果.pyenv文件夹还不存在,您还可以让该脚本从URL中获取压缩版本的.pyenv文件夹,方法是在脚本前加上如下内容:
if [ ! -d "$HOME/.pyenv" ]; then
wget https://url.to/mypenv.zip
unzip mypyenv.zip
fi
如果工作者计算机上的主驱动器空间有限,请考虑解压缩到
tmp目录并设置相应地PYENV_ROOT环境变量。你可能需要:
- 通过ssh或常规登录登录计算机
- 开始屏幕
- 启动脚本
我们可以通过使用pssh对给定主机列表自动执行上述操作来做得更好。
pssh -h hosts.txt bash -c "nohup ~/hyperopt_job/job.sh &"
结果
完成所有工作后,你可以使用mongodb浏览器(如Robo3T)查看结果。下面一个小脚本,用于从数据库中获取具有最低损失分数的模型并反序列化你的模型:
from pymongo import MongoClient, ASCENDING
from keras.models import load_model
import tempfile
c = MongoClient('mongodb://username:pass@mongodb.host:27017/jobs')
best_model = c['jobs']['jobs'].find_one({'exp_key': 'mnist_test', 'result.status': 'ok'}, sort=[('result.loss', ASCENDING)])
temp_name = tempfile.gettempdir()+'/'+next(tempfile._get_candidate_names()) + '.h5'
with open(temp_name, 'wb') as outfile:
outfile.write(best_model['result']['model_serial'])
model = load_model(temp_name)
# do things with your model here
model.summary()
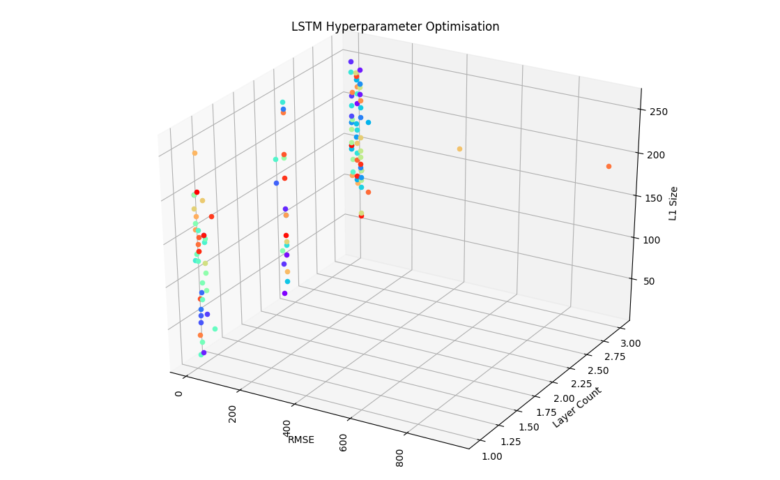
你可以使用以下代码将搜索空间子集的结果可视化(具有2个以上参数的典型搜索空间,因此可能并不清楚哪一个(或哪个组合)对你的模型性能影响最大):
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from pymongo import MongoClient
import numpy as np
if __name__ == "__main__":
# get the data
jobs = MongoClient('mongodb://username:pass@mongodb.host:27017/jobs')['jobs']['jobs']
cursor = jobs.find({'exp_key': 'mnist_test', 'result.status': 'ok'})
results = defaultdict(lambda: defaultdict(list))
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for i in ax.get_xticklabels():
i.set_rotation(90)
for row in cursor:
cc = row['tid']
results[cc]['x'].append(row['result']['loss'])
results[cc]['y'].append(row['result']['ho_params']['l1_size'])
results[cc]['z'].append(row['result']['ho_params']['l1_dropout'])
colors = cm.rainbow(np.linspace(0, 1, len(results)))
it = iter(colors)
for k, v in results.items():
ax.scatter(v['x'], v['y'], v['z'], label=k, color=next(it))
ax.set_xlabel('RMSE')
ax.set_ylabel('Layer Count')
ax.set_zlabel('L1 Size')
plt.title("Hyperparameter Optimisation Results")
plt.show()
下面是我的一个实验的输出,正如你所看到的,优化器可以快速找到聚集在给定搜索空间的最小可实现错误评分附近的模型:

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消