











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用DataRobot和DataRobot API
2018年03月29日 由 荟荟 发表
383929
0
在这篇博客文章中,我们将演示如何使用Python和DataRobot?API?(访问我们的完整??API文档)?来量化和可视化预测分布,这些预测分布在我们的主题医院的不同患者再入院概率范围内。
单次重新接收预测是模型的最佳猜测,但不包括通常在训练数据中发现的采样偏差所发生的可能预测的分布。理想情况下,训练数据是整个人群的无偏见和有代表性的样本,但由于数据集只是一个样本,因此它们将包含偏差。建模最终将适合那些采样偏差。
这些预测分布可用于评估模型置信度,对模型进行有针对性的改进,并最终以预测置信度对新数据做出决策。
引导,一种依赖于随机抽样和替换的方法,允许我们通过创建用于建模的训练数据的分布来分配预测再现性的度量。通过拟合每个训练数据集来构建模型,并且将产生不同的预测。用于评估预测分布的自举的基本思想是可以通过重新采样训练数据并对来自重采样数据的样本进行推断来建模关于总体的分布。训练数据成为总体,重采样数据成为样本。由于人口未知,样本统计数据与人口价值的真实误差未知。在bootstrap-resamples中,'population'实际上是样本,这是已知的; 因此'真实'推理的质量
了解预测分布在模型中增加了另一层信息和信心,可用于做出更好的决策。例如,如果模型预测再入院概率为0.4,则医院管理员可能不会采取任何行动。但是,如果预测值在0.4范围内的可信度很低,医院可能会采取不同的措施来避免代价高昂的假阴性。另一方面,建模者可以使用该信息来解释整个预测范围内给定模型的稳健性或确定性。他们可以进行模型改进,获取更多数据,或确定模型对于某些预测范围是稳定且可靠的,从而使管理员得出结论,无需进一步开发。
以下方法向我们展示了如何使用DataRobot凭经验估计每个预测概率范围的预测分布。
背景和目标
使用案例:
预测未来30天内患者再入院的概率。
由于在出院后30天内对患者再入院征收罚款,医院有兴趣预测患者再入院的可能性。
方法:
根据10K糖尿病培训数据中捕获的历史再入院统计数据训练模型。
培训数据包含10K个患者示例,其中包含50多个功能。
训练数据还表明患者是否在解雇后30天内再入院。
主要目标:
估计和可视化10个大小相等的概率范围中的每一个的预测分布。
方法
加载输入数据并初始化DataRobot API客户端实例。
创建100个自举数据集,并替换原始输入数据。
使用DataRobot的自动机器学习 API,为每个自举数据集构建模型集。
选择适合每个引导数据集的最准确模型。
使用最佳模型,对原始数据集进行预测。
根据每个记录的平均预测概率对预测进行排序和分类。
使用箱线图可视化预测区间。
码
将datarobot 导入为dr
将pandas 导入为pd
pd 。选项。显示。max_columns = 1000
导入numpy 为np
进口时间
导入matplotlib 。作为plt的pyplot
来自jupyterthemes import jtplot
如果没有提供参数,#当前安装的主题将用于设置打印样式
jtplot 。风格()
get_ipython ()。魔术('matplotlib inline')
加载并初始化DataRobot API客户端实例
#load输入数据
df = pd 。read_csv ('../demo_data/10kDiabetes.csv')
#initialize datarobot客户端实例
博士。客户(config_path = '/ Users / benjamin.miller/.config/datarobot/my_drconfig.yaml')
引导
#创建100个样本,替换原始的10K糖尿病数据集
samples = []
对于我在范围(100 ):
样品。追加(df 。样本(10000 ,替换= 真))
造型
#遍历每个样本数据帧
for i ,s in enumerate (samples ):
#initialize project
project = 博士。项目。开始(
project_name = 'API_Test_ {}' 。格式(i + 20 ),
sourcedata = s,
target = 'readmitted',
worker_count = 2
)
...等待每个自举样本的建模完成
#获取所有项目
项目= []
对于项目在 博士。项目。list ():
如果 “API_Test” 的项目。项目名:
项目。追加(项目)
#*对于每个项目...... *
#使用最准确的模型对原始数据集进行预测
#初始化用于合并结果的所有预测的列表
bootstrap_predictions = []
#循环遍历每个相关项目以获得对原始输入数据集的预测
对于项目中的项目:
#获得最佳表现模型
model = dr 。模型 。得到(项目= 项目。ID ,MODEL_ID = 项目。get_models ()[ 0 ]。 id)的
#upload数据集
new_data = 项目。upload_dataset (df)
#开始预测工作
predict_job = model 。request_predictions (NEW_DATA 。ID)
#每5秒获取一次工作状态并继续“进入”
对于我在范围(100 ):
时间。睡觉(5)
尝试:
job_status = dr 。PredictJob 。得到(
project_id = 项目。id ,
predict_job_id = predict_job 。ID
)。状态
除了:#通常,job_status在完成时会产生错误
打破
#现在预测已经完成
预测= 博士。PredictJob 。get_predictions(
project_id = 项目。ID,
predict_job_id = predict_job 。ID
)
#解压缩所有记录的行ID和正概率,并设置为字典
pred_dict = { ? :v 为? ,v 在拉链(预测。ROW_ID ,预测。positive_probability )}
#将预测字典附加到bootstrap预测
bootstrap_predictions 。追加(pred_dict )
可视化结果
#将所有预测组合成单个数据帧,并将键作为ID
#每条记录都是一行,每列都是一组与之相关的预测
#从引导数据集创建的模型
df_predictions = pd 。DataFrame ( bootstrap_predictions ).T
#在df_predictions中为每个观察添加平均预测
df_predictions [ 'mean' ] = df_predictions 。平均值(轴= 1)
#使用均值将每条记录放入相同大小的概率组中
df_predictions [ 'probability_group' ] = pd 。qcut(df_predictions [ 'mean' ], 10)
#聚合每个概率组的所有预测
d = {} #dictionary包含{Interval(probability_group):array([predictions])}
对于 PG 在集( df_predictions 。 probability_group ):
#组合给定组的所有预测
frame = df_predictions [ df_predictions 。probability_group == pg ]。iloc [:, 0 :100 ]
d [ str ( pg )] =框架。as_matrix ()。flatten ()
#从所有概率组预测中创建数据帧
df_pg = pd 。DataFrame ( d)
#按照增加概率范围的顺序创建箱图
道具=字典(方框= “青灰” ,中位数= “黑” ,晶须= “青灰”)
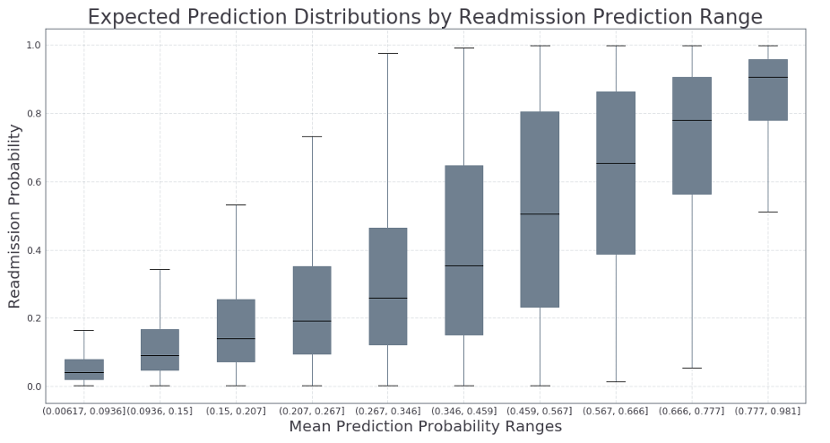
即= df_pg 。情节。盒(颜色=道具, figsize =(15 ,7 ), patch_artist = 真,腐= 45)
grid =即。网格(False , axis = 'x')
ylab =即。set_ylabel (' Readmission Probability')
xlab =即。set_xlabel ('平均预测概率范围')
title = viz 。SET_TITLE(
label = '重新预测范围的预期预测分布' ,
fontsize = 18
)
关于这个例子的说明......
输入数据集虽然基于实际历史数据,但只是完整数据集的一小部分。如果输入数据集较大,预测间隔很可能会减少。此外,我使用完整的Autopilot在每个引导数据集上执行建模,但更好的方法是为每个项目使用单个模型。这将确保更多的“苹果与苹果”比较。选择最佳模型仍然是合适的,但可能会使预测间隔膨胀。最后,应该对未用于训练任何模型的数据进行预测。在示例开头应该分离一个保持力。这些保持数据应该用于生成预测和评估预期的预测间隔。
结论
我们可以使用此方法来评估对新数据进行预测的可信度,而不是单一概率。我们可以根据我们对单点预测的信任程度,使用此信息来决定如何处理每个新案例。低风险个体(P <0.2)很可能不会再入院,而高风险个体(P> 0.8)可能需要在接下来的30天内重新入院。这些结果添加了管理员可用于做出更好决策的另一层信息。
单次重新接收预测是模型的最佳猜测,但不包括通常在训练数据中发现的采样偏差所发生的可能预测的分布。理想情况下,训练数据是整个人群的无偏见和有代表性的样本,但由于数据集只是一个样本,因此它们将包含偏差。建模最终将适合那些采样偏差。
这些预测分布可用于评估模型置信度,对模型进行有针对性的改进,并最终以预测置信度对新数据做出决策。
引导,一种依赖于随机抽样和替换的方法,允许我们通过创建用于建模的训练数据的分布来分配预测再现性的度量。通过拟合每个训练数据集来构建模型,并且将产生不同的预测。用于评估预测分布的自举的基本思想是可以通过重新采样训练数据并对来自重采样数据的样本进行推断来建模关于总体的分布。训练数据成为总体,重采样数据成为样本。由于人口未知,样本统计数据与人口价值的真实误差未知。在bootstrap-resamples中,'population'实际上是样本,这是已知的; 因此'真实'推理的质量
了解预测分布在模型中增加了另一层信息和信心,可用于做出更好的决策。例如,如果模型预测再入院概率为0.4,则医院管理员可能不会采取任何行动。但是,如果预测值在0.4范围内的可信度很低,医院可能会采取不同的措施来避免代价高昂的假阴性。另一方面,建模者可以使用该信息来解释整个预测范围内给定模型的稳健性或确定性。他们可以进行模型改进,获取更多数据,或确定模型对于某些预测范围是稳定且可靠的,从而使管理员得出结论,无需进一步开发。
以下方法向我们展示了如何使用DataRobot凭经验估计每个预测概率范围的预测分布。
背景和目标
使用案例:
预测未来30天内患者再入院的概率。
由于在出院后30天内对患者再入院征收罚款,医院有兴趣预测患者再入院的可能性。
方法:
根据10K糖尿病培训数据中捕获的历史再入院统计数据训练模型。
培训数据包含10K个患者示例,其中包含50多个功能。
训练数据还表明患者是否在解雇后30天内再入院。
主要目标:
估计和可视化10个大小相等的概率范围中的每一个的预测分布。
方法
加载输入数据并初始化DataRobot API客户端实例。
创建100个自举数据集,并替换原始输入数据。
使用DataRobot的自动机器学习 API,为每个自举数据集构建模型集。
选择适合每个引导数据集的最准确模型。
使用最佳模型,对原始数据集进行预测。
根据每个记录的平均预测概率对预测进行排序和分类。
使用箱线图可视化预测区间。
码
将datarobot 导入为dr
将pandas 导入为pd
pd 。选项。显示。max_columns = 1000
导入numpy 为np
进口时间
导入matplotlib 。作为plt的pyplot
来自jupyterthemes import jtplot
如果没有提供参数,#当前安装的主题将用于设置打印样式
jtplot 。风格()
get_ipython ()。魔术('matplotlib inline')
加载并初始化DataRobot API客户端实例
#load输入数据
df = pd 。read_csv ('../demo_data/10kDiabetes.csv')
#initialize datarobot客户端实例
博士。客户(config_path = '/ Users / benjamin.miller/.config/datarobot/my_drconfig.yaml')
引导
#创建100个样本,替换原始的10K糖尿病数据集
samples = []
对于我在范围(100 ):
样品。追加(df 。样本(10000 ,替换= 真))
造型
#遍历每个样本数据帧
for i ,s in enumerate (samples ):
#initialize project
project = 博士。项目。开始(
project_name = 'API_Test_ {}' 。格式(i + 20 ),
sourcedata = s,
target = 'readmitted',
worker_count = 2
)
...等待每个自举样本的建模完成
#获取所有项目
项目= []
对于项目在 博士。项目。list ():
如果 “API_Test” 的项目。项目名:
项目。追加(项目)
#*对于每个项目...... *
#使用最准确的模型对原始数据集进行预测
#初始化用于合并结果的所有预测的列表
bootstrap_predictions = []
#循环遍历每个相关项目以获得对原始输入数据集的预测
对于项目中的项目:
#获得最佳表现模型
model = dr 。模型 。得到(项目= 项目。ID ,MODEL_ID = 项目。get_models ()[ 0 ]。 id)的
#upload数据集
new_data = 项目。upload_dataset (df)
#开始预测工作
predict_job = model 。request_predictions (NEW_DATA 。ID)
#每5秒获取一次工作状态并继续“进入”
对于我在范围(100 ):
时间。睡觉(5)
尝试:
job_status = dr 。PredictJob 。得到(
project_id = 项目。id ,
predict_job_id = predict_job 。ID
)。状态
除了:#通常,job_status在完成时会产生错误
打破
#现在预测已经完成
预测= 博士。PredictJob 。get_predictions(
project_id = 项目。ID,
predict_job_id = predict_job 。ID
)
#解压缩所有记录的行ID和正概率,并设置为字典
pred_dict = { ? :v 为? ,v 在拉链(预测。ROW_ID ,预测。positive_probability )}
#将预测字典附加到bootstrap预测
bootstrap_predictions 。追加(pred_dict )
可视化结果
#将所有预测组合成单个数据帧,并将键作为ID
#每条记录都是一行,每列都是一组与之相关的预测
#从引导数据集创建的模型
df_predictions = pd 。DataFrame ( bootstrap_predictions ).T
#在df_predictions中为每个观察添加平均预测
df_predictions [ 'mean' ] = df_predictions 。平均值(轴= 1)
#使用均值将每条记录放入相同大小的概率组中
df_predictions [ 'probability_group' ] = pd 。qcut(df_predictions [ 'mean' ], 10)
#聚合每个概率组的所有预测
d = {} #dictionary包含{Interval(probability_group):array([predictions])}
对于 PG 在集( df_predictions 。 probability_group ):
#组合给定组的所有预测
frame = df_predictions [ df_predictions 。probability_group == pg ]。iloc [:, 0 :100 ]
d [ str ( pg )] =框架。as_matrix ()。flatten ()
#从所有概率组预测中创建数据帧
df_pg = pd 。DataFrame ( d)
#按照增加概率范围的顺序创建箱图
道具=字典(方框= “青灰” ,中位数= “黑” ,晶须= “青灰”)
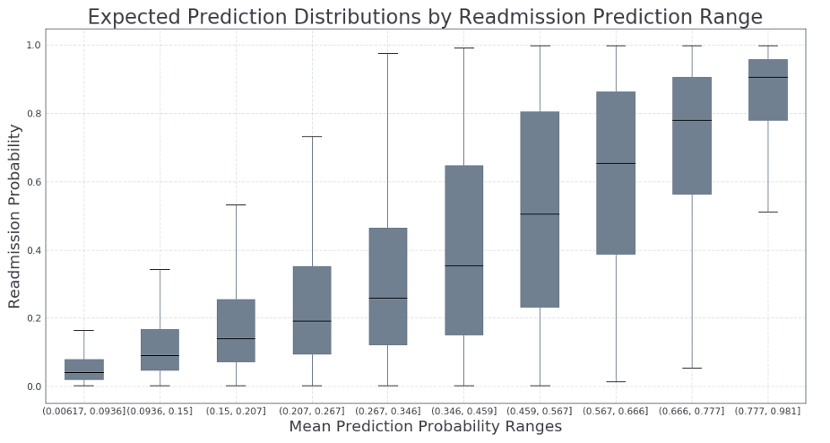
即= df_pg 。情节。盒(颜色=道具, figsize =(15 ,7 ), patch_artist = 真,腐= 45)
grid =即。网格(False , axis = 'x')
ylab =即。set_ylabel (' Readmission Probability')
xlab =即。set_xlabel ('平均预测概率范围')
title = viz 。SET_TITLE(
label = '重新预测范围的预期预测分布' ,
fontsize = 18
)
关于这个例子的说明......
输入数据集虽然基于实际历史数据,但只是完整数据集的一小部分。如果输入数据集较大,预测间隔很可能会减少。此外,我使用完整的Autopilot在每个引导数据集上执行建模,但更好的方法是为每个项目使用单个模型。这将确保更多的“苹果与苹果”比较。选择最佳模型仍然是合适的,但可能会使预测间隔膨胀。最后,应该对未用于训练任何模型的数据进行预测。在示例开头应该分离一个保持力。这些保持数据应该用于生成预测和评估预期的预测间隔。
结论
我们可以使用此方法来评估对新数据进行预测的可信度,而不是单一概率。我们可以根据我们对单点预测的信任程度,使用此信息来决定如何处理每个新案例。低风险个体(P <0.2)很可能不会再入院,而高风险个体(P> 0.8)可能需要在接下来的30天内重新入院。这些结果添加了管理员可用于做出更好决策的另一层信息。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消