











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深度学习实践:通过图像识别技术检测年龄解决方案的练习题
2017年07月13日 由 xiaoshan.xiang 发表
906712
0
在实践操作中应用所学到的深度学习知识可以帮助你提高你的学习效率。深度学习已经为相机的人脸检测提供了帮助。今天我们将用深度学习通过图像识别技术检测年龄解决方案的练习题
为什么要参与实践操作(深度学习)
如果你已经学习过关于深度学习的知识,并且希望应用你的新技能——实践操作是最好的开始。
下面是一些你要学会实践操作的理由:
建立基础:应该建立一个正确的foundation并且多实践操作,很多人在编码时没有考虑问题和理解数据。
互相学习(论坛或者博客):在实践操作当中,参与者在论坛或者博客上分享他们的方法并且时刻准备着去讨论新的方法。
实践:实践操作就是你走出理论去解决在现实生活中遇到问题,你应该评估自己的表现,尽力做好,在这段期间你的目标应该是充分利用工具,算法和数据集。
测试你的知识:在这个地方你可以应用你学习到的知识,也可以帮助你巩固你学到的知识。结果并不重要,因为它仅仅是用来练习的。
又有什么问题
首先要理解问题。在这篇文章中,我们将看到一个最近出版的实践操作:印度演员的年龄识别。
下面是一些来自我们的数据的随机例子。



但是你能猜到这些吗?


这些都是中年演员。
为了解决这些问题,你需要一个简化的方法,我们会在下一部分看到。
解决问题
知道问题之后就要去解决它。在解决问题之前,需要在电脑上安装numpy,scipy,pandas,scikit-learn和keras。
解决问题的第一步:下载数据并将其加载到笔记本中,下面是实践操作的链接。
(https://datahack.analyticsvidhya.com/contest/practice-problem-age-detection/)。
在建立模型之前,需要进行一个简单的练习:
写一个脚本,随机地将图像加载到笔记本中并输出出来。
下面是练习的方法: 先导入所有必要的模块。
然后加载csv文件。
写一个脚本来随机选择一个图像并输出。
得到的结果:年轻

练习的目的是你可以随机查看数据集,并检查在构建模型时可能遇到的问题。
以下是在练习过程中可能会遇到的问题
尺寸变化:一个图像有一个尺寸(66,46),而另一个图像具有不同的尺寸(102,87)。
多种角度:可能会遇到不同方位的视图。
这里有些例子:

图像质量:某些图像被打上马赛克。
这是一个例子

亮度和对比度差异:检查下面的图像;


现在,我们只解决尺寸变化这一个问题。
加载所有的图像,并将它们调整为单个numpy数组。
对于测试图像也是如此
规范图像可以帮助我们建立一个更好的模型。
现在来看目标变量,尝试对数据分类
中场休息:第一次提交
在数据分类的基础上,创建一个简单的提交。我们看到大多数演员都是中年人。 所以就可以说在我们测试数据集中的所有演员的年龄都是中年。
在提交页面上传这个文件,查看结果。
解决问题。第二部分:构建更好的模型
在创建实质性的东西之前,将图片尺寸设置为目标变量。将目标转换成虚拟列。
主要部分是建立模型。由于问题与图像处理相关,使用神经网络来解决问题更适合。 建立一个简单的前馈神经网络。
首先指定在这个网络中会需要的所有参数。
然后输入必要的keras模块
接下来确定网络
查看模型结果;输出
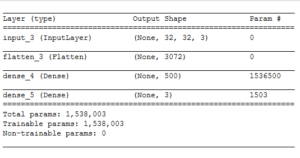
编译网络并让它训练一会。
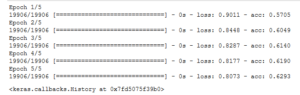
接下来进行验证。调整一下代码,交叉验证。
提交结果。
中场休息:对预测的视觉检查
输出图像以及训练过模型的预测。
接下来要做什么
已经建立了一个简单的解决方案。我们还能做些什么?
这里有一些小建议:
1.合适的神经网络模型:你可以尝试一个能更好适应图片相关问题的卷积神经网络。下面是一些供你查阅的简单的CNN。
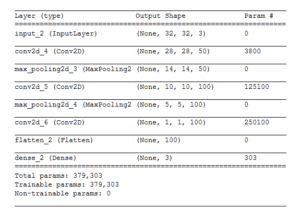
2.你可以增加模型的训练集的数量。可以调整神经网络中的参数。 下面是一个帮助调整神经网络的指南。
(https://www.analyticsvidhya.com/blog/2016/10/tutorial-optimizing-neural-networks-using-keras-with-image-recognition-case-study/)
3.我们在解决问题时可能遇到另一些问题,如果我们对数据进行适当的预处理,那么问题可能会简单很多。
4.理解问题:当你更好地理解问题时,可能就会有更好的解决问题的方法。
为什么要参与实践操作(深度学习)
如果你已经学习过关于深度学习的知识,并且希望应用你的新技能——实践操作是最好的开始。
下面是一些你要学会实践操作的理由:
建立基础:应该建立一个正确的foundation并且多实践操作,很多人在编码时没有考虑问题和理解数据。
互相学习(论坛或者博客):在实践操作当中,参与者在论坛或者博客上分享他们的方法并且时刻准备着去讨论新的方法。
实践:实践操作就是你走出理论去解决在现实生活中遇到问题,你应该评估自己的表现,尽力做好,在这段期间你的目标应该是充分利用工具,算法和数据集。
测试你的知识:在这个地方你可以应用你学习到的知识,也可以帮助你巩固你学到的知识。结果并不重要,因为它仅仅是用来练习的。
又有什么问题
首先要理解问题。在这篇文章中,我们将看到一个最近出版的实践操作:印度演员的年龄识别。
下面是一些来自我们的数据的随机例子。
中年
老年
年轻
但是你能猜到这些吗?
这些都是中年演员。
为了解决这些问题,你需要一个简化的方法,我们会在下一部分看到。
解决问题
知道问题之后就要去解决它。在解决问题之前,需要在电脑上安装numpy,scipy,pandas,scikit-learn和keras。
解决问题的第一步:下载数据并将其加载到笔记本中,下面是实践操作的链接。
(https://datahack.analyticsvidhya.com/contest/practice-problem-age-detection/)。
在建立模型之前,需要进行一个简单的练习:
写一个脚本,随机地将图像加载到笔记本中并输出出来。
下面是练习的方法: 先导入所有必要的模块。
% pylab inline
import os
import random
import pandas as pd
from scipy.misc import imread
然后加载csv文件。
root_dir = os.path.abspath('.')
data_dir = '/mnt/hdd/datasets/misc'
train = pd.read_csv(os.path.join(data_dir, 'train.csv'))
test = pd.read_csv(os.path.join(data_dir, 'test.csv'))写一个脚本来随机选择一个图像并输出。
i = random.choice(train.index)
img_name = train.ID[i]
img = imread(os.path.join(data_dir, 'Train', img_name))
print(‘Age: ‘, train.Class[i])
imshow(img)
得到的结果:年轻
练习的目的是你可以随机查看数据集,并检查在构建模型时可能遇到的问题。
以下是在练习过程中可能会遇到的问题
尺寸变化:一个图像有一个尺寸(66,46),而另一个图像具有不同的尺寸(102,87)。
多种角度:可能会遇到不同方位的视图。
这里有些例子:
正面
侧面
图像质量:某些图像被打上马赛克。
这是一个例子
亮度和对比度差异:检查下面的图像;
现在,我们只解决尺寸变化这一个问题。
加载所有的图像,并将它们调整为单个numpy数组。
from scipy.misc import imresize
temp = []
for img_name in train.ID:
img_path = os.path.join(data_dir, 'Train', img_name)
img = imread(img_path)
img = imresize(img, (32, 32))
img = img.astype('float32') # this will help us in later stage
temp.append(img)
train_x = np.stack(temp)
对于测试图像也是如此
temp = []
for img_name in test.ID:
img_path = os.path.join(data_dir, 'Test', img_name)
img = imread(img_path)
img = imresize(img, (32, 32))
temp.append(img.astype('float32'))
test_x = np.stack(temp)
规范图像可以帮助我们建立一个更好的模型。
train_x = train_x / 255.
test_x = test_x / 255.
现在来看目标变量,尝试对数据分类
train.Class.value_counts(normalize=True)
MIDDLE 0.542751
YOUNG 0.336883
OLD 0.120366
Name: Class, dtype: float64
中场休息:第一次提交
在数据分类的基础上,创建一个简单的提交。我们看到大多数演员都是中年人。 所以就可以说在我们测试数据集中的所有演员的年龄都是中年。
test['Class'] = 'MIDDLE'
test.to_csv(‘sub01.csv’, index=False)
在提交页面上传这个文件,查看结果。
解决问题。第二部分:构建更好的模型
在创建实质性的东西之前,将图片尺寸设置为目标变量。将目标转换成虚拟列。
import keras
from sklearn.preprocessing import LabelEncoder
lb = LabelEncoder()
train_y = lb.fit_transform(train.Class)
train_y = keras.utils.np_utils.to_categorical(train_y)
主要部分是建立模型。由于问题与图像处理相关,使用神经网络来解决问题更适合。 建立一个简单的前馈神经网络。
首先指定在这个网络中会需要的所有参数。
input_num_units = (32, 32, 3)
hidden_num_units = 500
output_num_units = 3
epochs = 5
batch_size = 128
然后输入必要的keras模块
from keras.models import Sequential
from keras.layers import Dense, Flatten, InputLayer
接下来确定网络
model = Sequential([
InputLayer(input_shape=input_num_units),
Flatten(),
Dense(units=hidden_num_units, activation='relu'),
Dense(units=output_num_units, activation='softmax'),
])
查看模型结果;输出
model.summary()
编译网络并让它训练一会。
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=batch_size,epochs=epochs,verbose=1)
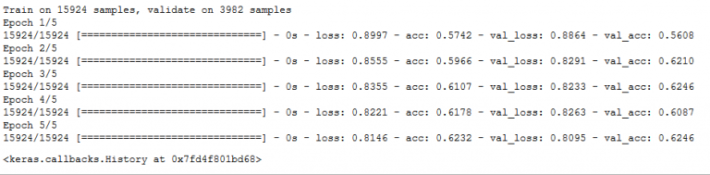
接下来进行验证。调整一下代码,交叉验证。
model.fit(train_x, train_y, batch_size=batch_size,epochs=epochs,verbose=1, validation_split=0.2)
提交结果。
pred = model.predict_classes(test_x)
pred = lb.inverse_transform(pred)
test['Class'] = pred
test.to_csv(‘sub02.csv’, index=False)
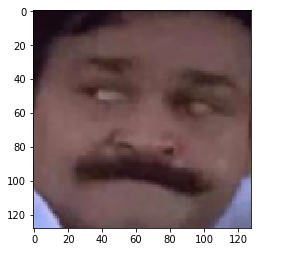
中场休息:对预测的视觉检查
输出图像以及训练过模型的预测。
i = random.choice(train.index)
img_name = train.ID[i]
img = imread(os.path.join(data_dir, 'Train', img_name)).astype('float32')
imshow(imresize(img, (128, 128)))
pred = model.predict_classes(train_x)
print('Original:', train.Class[i], 'Predicted:', lb.inverse_transform(pred[i]))
Original: MIDDLE Predicted: MIDDLE
接下来要做什么
已经建立了一个简单的解决方案。我们还能做些什么?
这里有一些小建议:
1.合适的神经网络模型:你可以尝试一个能更好适应图片相关问题的卷积神经网络。下面是一些供你查阅的简单的CNN。
2.你可以增加模型的训练集的数量。可以调整神经网络中的参数。 下面是一个帮助调整神经网络的指南。
(https://www.analyticsvidhya.com/blog/2016/10/tutorial-optimizing-neural-networks-using-keras-with-image-recognition-case-study/)
3.我们在解决问题时可能遇到另一些问题,如果我们对数据进行适当的预处理,那么问题可能会简单很多。
4.理解问题:当你更好地理解问题时,可能就会有更好的解决问题的方法。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消