


















机器学习练习:出租车车费预测的挑战

在课程,书籍和视频上花了大量的时间(和金钱)后,我得出了一个结论:学习数据科学最有效的方法是做数据科学项目。阅读,听课和记笔记是很有价值的,但直到你解决问题时,概念才会从抽象的概念固化为你可以自信使用的工具。
在本文中,我将介绍另一种用Python进行的机器学习练习,并为你留下一个挑战:尝试开发更好的解决方案(包括一些有用的提示)!项目完整的Jupyter Notebook可以在Kaggle上运行(无需下载),也可以访问GitHub获取。
Kaggle:https://www.kaggle.com/willkoehrsen/a-walkthrough-and-a-challenge
GitHub:https://github.com/WillKoehrsen/taxi-fare/blob/master/A%20Walkthrough%20and%20a%20Challenge.ipynb
问题叙述
纽约市出租车车费预测竞赛是一个有监督的回归的机器学习任务。给定上车和下车地点,行程时间和乘客数量,目标是预测出租车车费。像大多数Kaggle比赛一样,这个问题不能100%反映行业中的情况,但它确实提供了一个真实的数据集和任务,让我们可以磨练我们的机器学习技能。
要解决这个问题,我们将遵循标准的数据科学流程:
- 了解问题和数据
- 数据探索或数据清理
- 特征工程或特征选择
- 模型评估和选择
- 模型优化
- 解释结果和预测
这个大纲似乎从开始到完成显示为线性路径,但数据科学是一个高度非线性的过程,其中的步骤是重复的或无序完成的。随着我们对数据的熟悉,我们经常希望回过头来重新审视过去的决策或采取新的方法。
虽然最终的Jupyter Notebook看起来紧密而流畅,但开发过程非常混乱,涉及重写代码和更改早期决策。
在整篇文章中,我将指出一些我认为一个有进取心的数据科学家可以改进的地方。我已将这些潜在的改进标记为标签,因为机器学习作为一个主要靠经验的领域,有些事情不能完全确定。
纽约市出租车费预测挑战
开始
出租车车费数据集是5500万个训练行比较大,但简单易懂,只有6个特征。这fare_amount是目标,我们将训练模型去预测连续值:
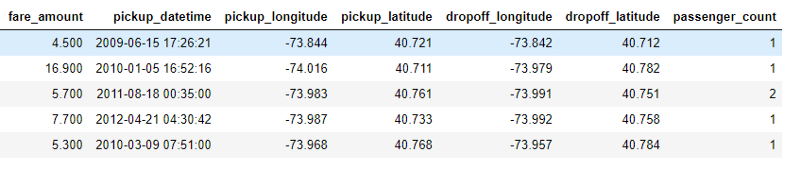
训练数据
在整个笔记本中,我只使用了5,000,000行的样本来更快地进行计算。我的第一个建议是:
- 潜在改进1:使用更多数据来训练模型
不能保证大量数据一定会有所帮助,但研究发现,一般来说,随着用于训练模型的数据量的增加,性能会提高。在更多数据上训练的模型可以更好地学习实际信号,尤其是在具有大量特征的高维问题中(这不是高维数据集,因此使用更多数据的回报也许有限)。
虽然庞大的数据集可能很吓人,但像Dask这样的框架允许你在自己的笔记本上处理大量数据集。此外,一旦数据超出了计算机的能力,学习如何设置和使用云计算(如Amazon ECS)是一项至关重要的技能。
幸运的是,要理解这些数据并不需要太多研究:我们大多数人都做过出租车,我们知道出租车是根据行驶里程收费的。因此,对于特征工程,我们希望找到一种方法根据已知的信息来表示所走的距离。我们还可以阅读其他数据科学家的notebook,或通过竞赛的讨论阅读有关如何解决问题的思路。
数据探索和清理
虽然Kaggle数据通常比实际数据更“干净”,但是这个数据集仍然存在一些问题,即几个特征中的异常。我喜欢将数据清理作为探索过程的一部分,在发现异常或数据错误时进行纠正。对于这个问题,我们可以通过使用df.describe()查看数据的统计数据来发现异常值。
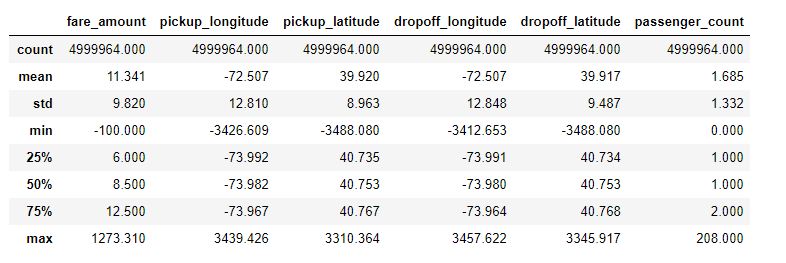
训练数据的统计描述
通过观察数据分布并结合领域知识来解决passenger_count、coordinates和fare_amount的异常。例如,阅读纽约市的出租车车费,我们发现最低价为2.50美元,这意味着我们应该根据车费排除部分乘车。对于坐标,我们可以查看分布并排除远远超出标准的值。识别出异常值后,我们可以使用以下代码删除它们:
# Remove latitude and longtiude outliers
data = data.loc[data['pickup_latitude'].between(40, 42)]
data = data.loc[data['pickup_longitude'].between(-75, -72)]
data = data.loc[data['dropoff_latitude'].between(40, 42)]
data = data.loc[data['dropoff_longitude'].between(-75, -72)]
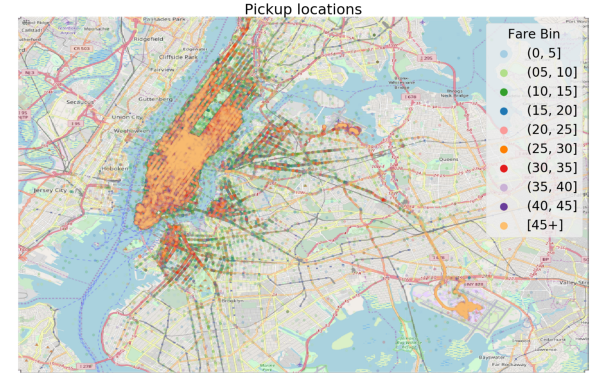
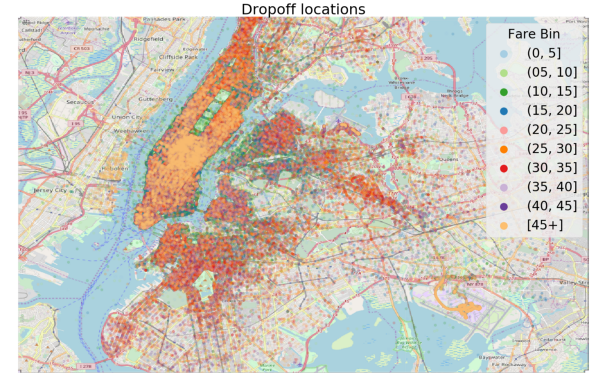
一旦我们清理了数据,我们就可以进行可视化。下面是纽约的上车和下车位置的图表,通过分箱车费着色(bin,国内一般称为分箱,是将连续变量转换为离散变量的一种方式)。
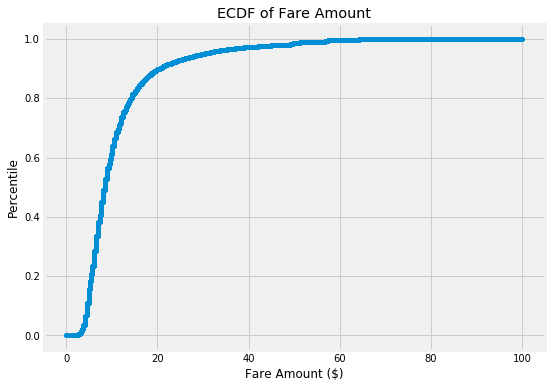
我们还想看看目标变量。以下是目标变量的经验累积分布函数(ECDF)图,即车费金额。对于一个变量,ECDF是比直方图更好的可视化选择,因为它没有来自分箱的伪迹。
情节可以帮助我们识别异常、关联新特征的概念等。在地图中,颜色代表车费,我们可以看到在机场(右下角)的车费往往是最贵的。回到领域知识,我们读到乘坐JFK机场的标准车费是45美元,所以如果我们能找到识别机场搭车的方法,那么我们就能准确地知道车费。
虽然我在本文中没有做得那么深入,但使用领域知识进行数据清理和特征工程非常有价值。我的第二个改进建议是:
- 潜在改进2:尝试不同的方法删除异常值和数据清理。
这可以通过领域知识(例如地图)或统计方法(例如z分数)来实现(解决这个问题的一个有趣的方法是删除在水中开始或结束的搭乘,如这位作者:https://www.kaggle.com/breemen/nyc-taxi-fare-data-exploration)。
包含或排除异常值会对模型性能产生重大影响。然而,像机器学习中的大多数问题一样,数据清理没有标准的方法。
特征工程
特征工程是从现有数据集中创建新特征(预测变量)的过程。因为机器学习模型只能从它给出的特征中学习,所以这是机器学习中最重要的一步。
对于具有多个表和表之间关联的数据集,我们可能希望使用自动特征工程,但由于此问题的列数相对较少且只有一个表,因此我们可以手工构建一些高价值特征。
例如,既然我们知道乘坐出租车的费用与距离成正比,我们就会想要使用起点和终点来尝试找到驾驶距离。距离的一个粗略近似是起始经纬度和结束经纬度之差的绝对值。
# Absolute difference in latitude and longitude
data['abs_lat_diff'] = (data['dropoff_latitude'] - data['pickup_latitude']).abs()
data['abs_lon_diff'] = (data['dropoff_longitude'] - data['pickup_longitude']).abs()
特性不一定要复杂才有用!下面是新特征的图由分箱车费着色。
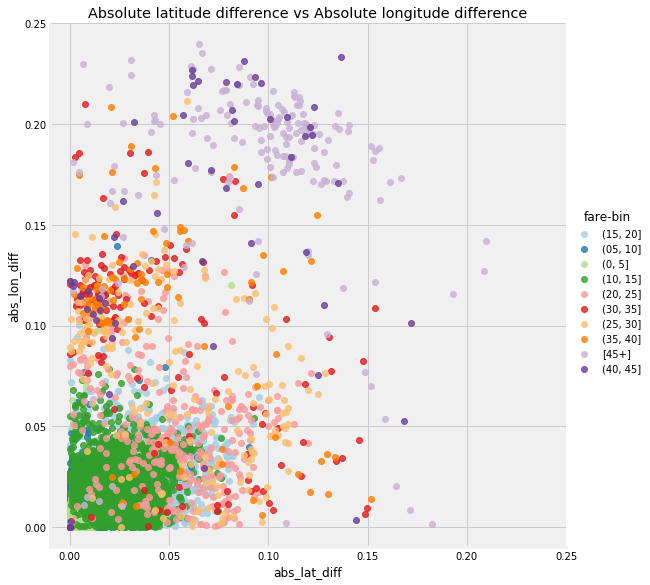
绝对经度与绝对纬度
这些特征给我们的是距离的相对度量,因为它们是根据经纬度而不是实际度量来计算的。这些特征可以用来对照,但如果我们想要以千米为单位进行度量,我们可以在行程的开始和结束之间应用半正矢公式,计算大圆距离。这仍然是一个近似值,因为它沿着地球球面上绘制一条线(我告诉地球是一个球体)给出连接两点的距离,旦显然,出租车不沿直线行进。
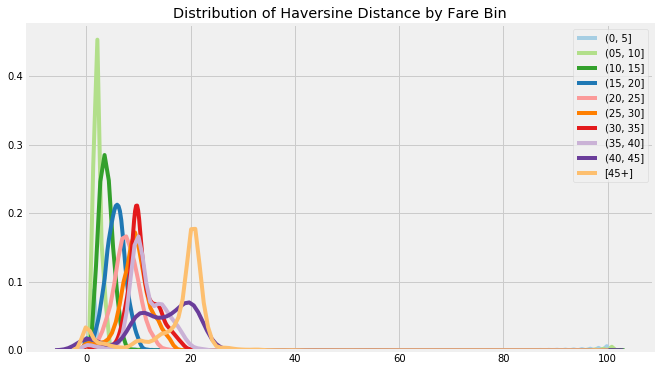
通过车费计算的距离
这个问题另一个主要特征的来源是时间。给定日期和时间,我们可以提取许多新变量。构建时间特征是一项常见任务,在notebook中我提供了一个有用的函数,它可以从一个时间戳构建很多特征。
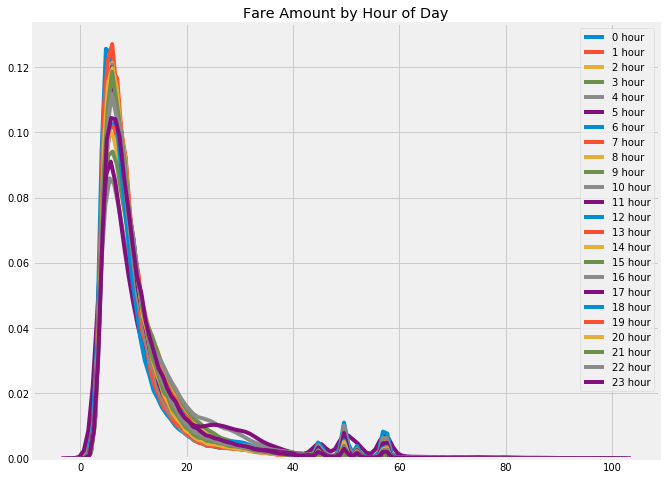
车费根据一天中的时间着色
虽然我在这个项目中构建了近20个特征,但还有更多特征有待发现。特性工程的难点在于你永远不知道什么时候你已经用尽了所有的选择。我的下一个建议是:
- 潜在改进3:构建更多的特性或对现有的特征进行特征选择,以找到最优特征集。
特征工程还涉及问题专业知识或应用自动为你构建特征的算法。构建特征后,通常需要应用特征选择才能找到最相关的特征。
获得干净的数据和一组特征后,就可以开始测试模型了。即使特征工程先于轮廓建模,但在项目的过程中,我经常要回到这一步。
模型评估与选择
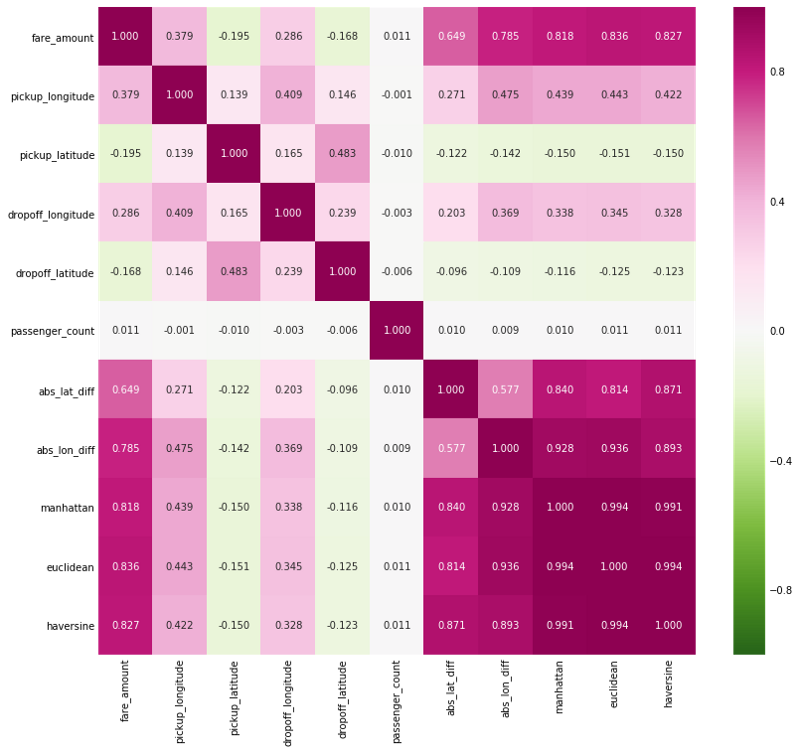
在回归任务上建立基线的第一选择模型是简单的线性回归。此外,如果我们查看这个问题的特征与车费的Pearson相关量,我们会发现几个非常强的线性关系,如下所示。
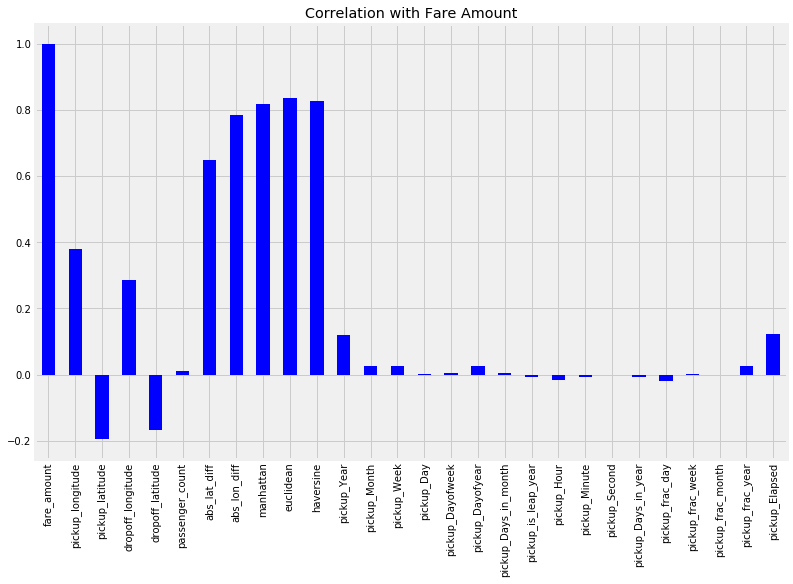
特征与目标的Pearson相关
基于某些特征与目标之间的线性关系的强度,我们可以期待线性模型的表现。虽然集成模型和深度神经网络最受瞩目,但如果一个简单的,可解释的模型可以实现几乎相同的性能,那么没有理由使用过于复杂的模型。尽管如此,尝试不同的模型仍然有意义,特别是因为它们很容易使用Scikit-Learn构建。
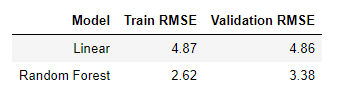
起始模型,仅对三个特征(位置差异的绝对值和passenger_count)进行训练的线性回归实现了5.32美元的验证均方根误差(RMSE)和28.6%的平均绝对百分误差。简单线性回归的好处是我们可以查看系数,有助于有更多的发现,例如,根据模型,一个乘客的增加会使票价上涨0.02美元。
# Linear Regression learned parameters
Intercept 5.0819
abs_lat_diff coef: 113.6661
abs_lon_diff coef: 163.8758
passenger_count coef: 0.0204
对于Kaggle比赛,我们可以使用验证集(这里我使用了1,000,000个实例)并通过向竞赛提交测试预测来评估模型。这使我们能够将我们的模型与其他数据科学家进行比较 - 线性回归大约为600/800。理想情况下,我们只想使用测试集一次来估计我们的模型在新数据上的表现,并使用验证集(或交叉验证)执行一些优化。Kaggle的问题在于排行榜会鼓励竞争对手构建针对测试数据过度优化的复杂模型。
我们还想将我们的模型与不使用机器学习的简单基线进行比较,在回归的情况下,可以猜测训练集上目标的平均值。结果RMSE为9.35美元,这使我们有信心机器学习适用于该问题。
即使对其他特征进行线性回归训练也不会产生很好的排行榜得分,下一步就是尝试更复杂的模型。我的下一个选择通常是随机森林。随机森林是比线性回归更灵活的模型,这意味着它具有较少的偏差 - 它可以更好地你和训练数据。随机森林通常也具有低方差,这意味着它可以推广到新数据。对于这个问题,随机森林优于线性回归,在同一个特征集上实现了4.20美元的验证RMSE。
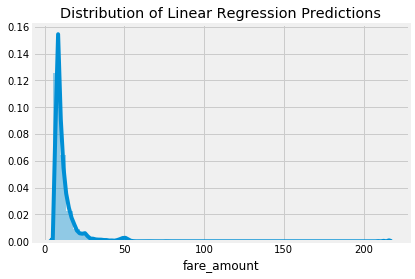
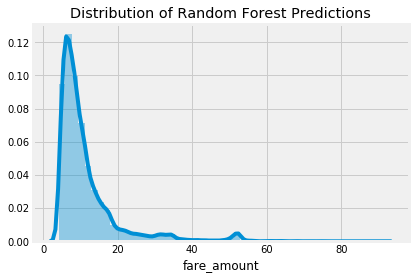
测试集预测分布
随机森林通常优于线性回归是因为它具有更大的灵活性和更低的偏见,并且由于它的许多决策树的预测结合在一起,它已经降低了方差。。线性回归是一种简单的方法,因此具有较高的偏差 - 它假设数据是线性的。线性回归也可能受到异常值的高度影响,因为它解决的是最小平方误差和的拟合问题。
模型(和超参数)的选择代表机器学习中偏差和方差的权衡:具有高偏差的模型甚至不能准确地学习训练数据,而具有高方差的模型本质是记忆训练数据并且不能推广到新的实例。因为机器学习的目标是推广到新数据,我们需要一个既有低偏差又有低方差的模型。
关于一个问题的最佳模型不一定是所有问题的最佳模型,因此研究跨越复杂范围的多种模型非常重要。应使用验证数据评估每个模型,然后可以在模型调优中优化性能最好的模型。由于验证结果,我选择了随机森林,我鼓励你尝试一些其他模型(甚至将模型集合在一起)。
模型优化
在机器学习问题中,我们有一些提高性能的方法:
- 获取更多数据
- 构建更多特征/执行特征选择
- 优化选定的模型
- 尝试更复杂的模型
从1和2仍然可以获得收益(这是挑战的一部分),但我也想提供一个优化所选模型的框架。
模型优化是在给定数据集上为模型找到最佳超参数的过程。由于超参数的最佳值取决于数据,因此必须针对每个新问题再次执行此操作。
我喜欢把模型优化(也称为模型调优)看作是寻找机器学习模型的理想设置。
优化方法有很多,从手动调整到自动超参数调整,但在实践中,随机搜索效果比较好,并且易于实现。在notebook中,我提供了运行随机搜索模型优化的代码。为了使计算时间合理,我再次对数据进行采样,并且仅运行50次迭代。即使这样也需要相当长的时间,因为超参数是使用3倍交叉验证来评估的。这意味着在每次迭代时,模型都要使用选定的超参数组合进行3次训练!
The best parameters were
{'n_estimators': 41, 'min_samples_split': 2, 'max_leaf_nodes': 49, 'max_features': 0.5, 'max_depth': 22, 'bootstrap': True}
with a negative mae of -2.0216735083205952
我还尝试了许多不同的特征,发现最好的模型只使用了27个特征中的12个。这是有道理的,因为许多特征高度相关,因此不是必需的。
在运行随机搜索并选择特征之后,最终的随机森林模型实现了3.38的RMSE,百分比误差为19.0%。这比简单的使用基线误差减少了66%,比第一个线性模型的误差减少了30%。这样的性能说明了机器学习的关键:
特征工程的回报远远大于模型优化的回报。因此,在操心最佳超参数之前,确保拥有一组良好的特征至关重要。
虽然我运行了50次随机搜索,但超参数值可能尚未完全优化。于是,我的下一个建议是:
- 潜在改进4:运行模型调优以在更多数据上进行更多迭代。
这样做的回报可能比特征工程要少,但仍有可能获得性能上的提升。如果你正在调优,还可以尝试使用Hyperopt等工具进行自动模型调整。
解释模型并做出预测
虽然随机森林比线性回归更复杂,但它并不完全是一个黑箱。一个随机森林决策树的集合,其这些决策树本身就是非常直观的流图模型。我们甚至可以检查森林中的单个决策树,以了解他们如何做出决定。另一种打开随机森林黑箱的方法是检查特征重要性。在这里,技术细节并不重要,但我们可以使用相对值来确定哪些特征与模型相关。
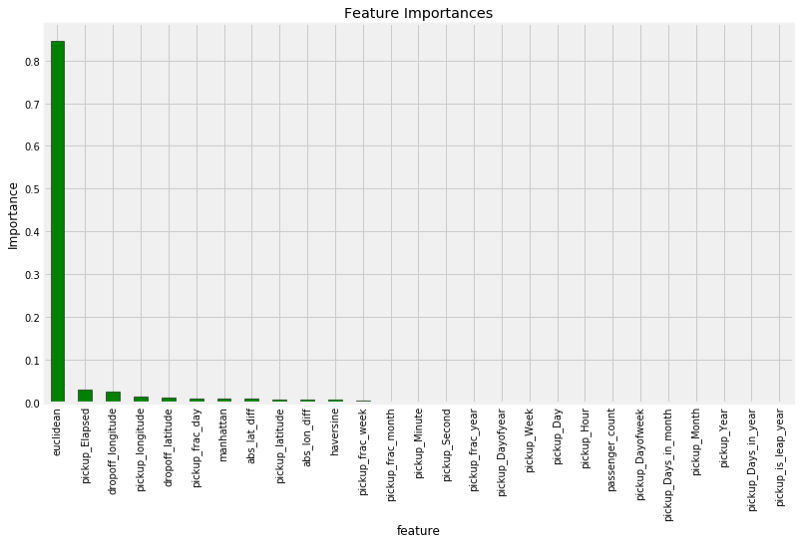
从所有特征的训练中获得的特征重要性
到目前为止,最重要的特征是出租车的欧几里得距离,其次是时间变量pickup_Elapsed。鉴于我们已经完成了这两个特征,我们确信我们的特征工程得到了很好的利用!我们还可以为特征工程或特征选择提供特征重要性,因为我们不需要保留所有变量。
最后,我们可以看一下验证数据和测试数据的模型预测。因为我们有验证答案,我们可以计算预测的误差,我们可以检查极值的测试预测。下面是最终模型的验证预测图。
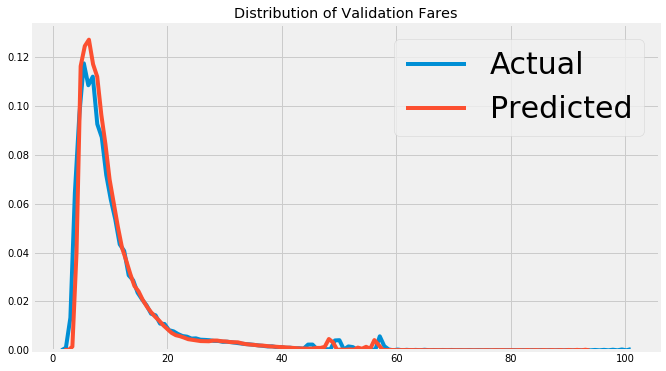
随机森林验证预测和真值。
模型解释仍然是一个相对较新的领域,但有一些有前途的方法可用于检验模型。虽然机器学习的主要目标是对新数据进行准确预测,但同样重要的是要知道模型为何准确,以及它是否能教会我们关于这个问题的任何东西。
下一步
虽然我们尝试了许多不同的技术并实现了完整的解决方案,但仍然有一些步骤可以改进模型。我的下一个方法是尝试更复杂的模型,例如深度神经网络或梯度增强算法(GBM)。我没有在notebook中实现这些,但我正在研究它们(我不能把所有的答案都给你!)。
- 潜在改进5:尝试更复杂的模型,如GBM
对于机器学习项目,总是有更多的方法可以尝试,如果对现有选项不满意,甚至可以提出自己的方法!机器学习是一个很大程度上是经验性的领域,没有标准化的规则,要知道某样东西是否有效,唯一的方法就是测试它。
接下来的步骤取决于你!









