











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用PyTorch实现神经过程
2018年09月29日 由 yuxiangyu 发表
787761
0
最近,Deepmind 在ICML上发表了神经过程(Neural Processes),这被称为高斯过程的深度学习版本。此外,Kaspar Martens发布了一篇博客文章,其中包含一些可视化(本文中不会讲这些)。我(作者)建议你可以先看看它们。
这篇文章是为了展示这些与VAE(变分自编码器)之间的联系,我觉得这很有启发性,并且展示了该方法的一些不足之处。所以,阅读本文前我建议你对VAE的工作知识有一定了解。此外,我不会讲神经过程的理论(因为你可以阅读论文和博客)。
最后,我会指出我认为是我在该方法中发现的一些相当重要的问题。我直接联系了论文的作者之一来讨论这些问题,但没有得到任何回应。我很高兴讨论一下,也许人们认为这些不足是由于我的错误或误解造成的,或者这些不足并不是什么大事。我没有在其他地方看到过这些内容,也没有讨论过这些内容,因此,这是对这种方法的缺点的讨论,而不是对这篇论文的攻击(事实上,我很喜欢这篇论文)。
VAE有一个简单的管道:
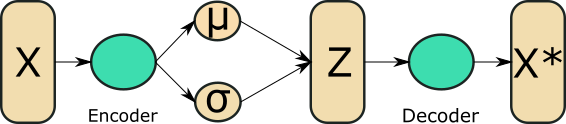
VAE编码单个数据点为潜在表示,并从其潜在变量中重构出数据点。如果我们正在学习图像的潜在表示,这就可以了,但是如果我们想要为函数执行此操作,我们还需要一个额外的步骤。
函数图(例如(X,sin(X))是在许多样本点上定义的。考虑嵌入以下函数:
我们所认为的“函数空间”实际上是由所有这些数据点的x,y坐标的集合定义的。如果我们就这样继续进行(将其提供给VAE),它无法捕获正确的东西。因此,我们所做的是引入一个中间步骤,即生成“函数表示”,它是所有数据点的单一表示。如果你曾经做过NLP,那么它与句子或文档嵌入的概念相同。我们可以清楚看到下图和前一个图是等价的都是普通的VAE。
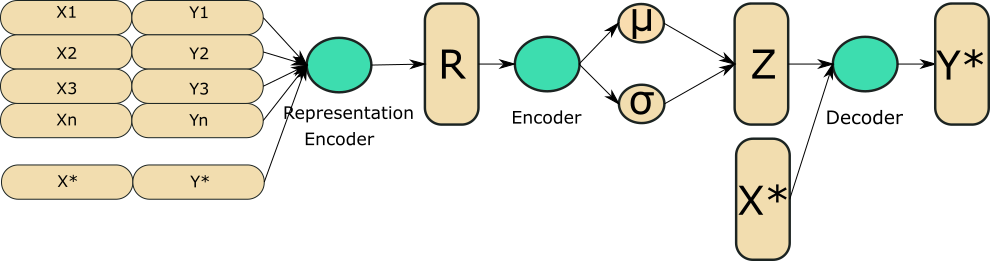
因此,正如图中所示,两个主要区别在于我们有一个额外的预处理步骤,我们将一个函数的多个点转换为一个表示,当我们重构时,我们同时使用潜在表示和我们想要预测的X* 。
在这里,我有一个非常简单的PyTorch实现,它遵循与Kaspar博客文章中第一个示例行数一样。我也使用他的R-Tensorflow代码调试我自己的代码中的一些问题,所以非常感谢他发布自己的代码!
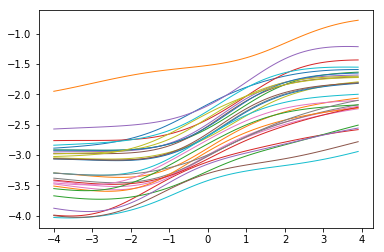
正如我们所看到的,我们得到的'高斯过程'就像之前的函数样本一样。
0步后的函数样本:
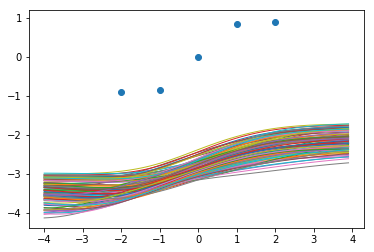
3000步后的函数样本:
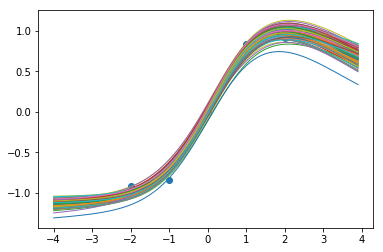
6000步后的函数样本:
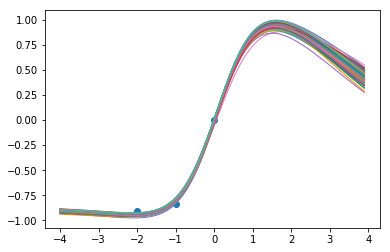
9000步后的函数样本:

当我们训练网络时,我们似乎在数据点内得到了很好的一致性,而当我们推断时,确定性降低了,这很不错!
在我的实现中,有一个看起来无伤大雅但实际至关重要的细节,我还没有谈过。那是我用过的权重初始化。大家会认为这是一件相当无关紧要的事情,但事实并非如此。例如,让我们重复上述步骤,但使用默认的PyTorch初始化。
0步后的函数样本:
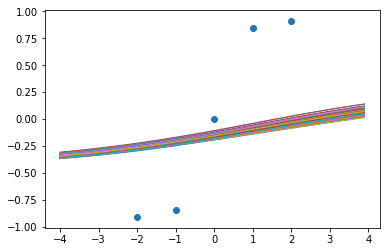
4500步后的函数样本:
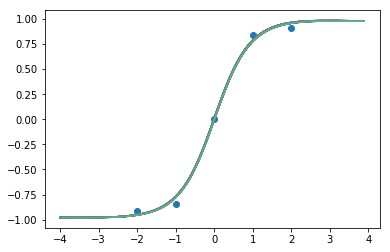
9000步后的函数样本:
嗯,它似乎基本上崩溃(collapse)到一个确定性的函数。让我们试试Xavier标准化。
0步后的函数样本:
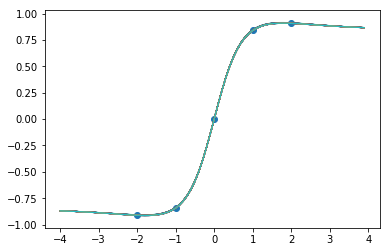
9000步后的函数样本:
这还是很奇怪。让我们重复第一个实验,但这一次,训练它的时间会更长一些。
0步后的函数样本:
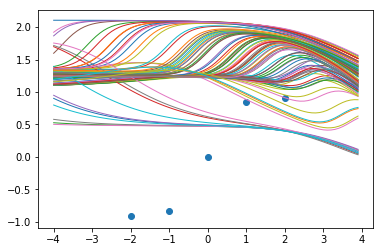
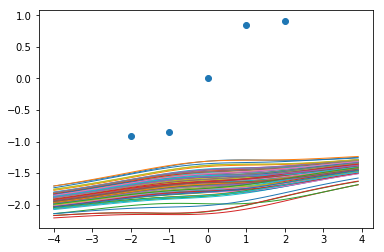
12500步后的函数样本:
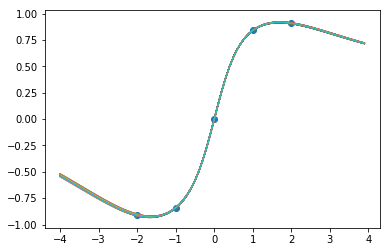
25000步后的函数样本:
因此,即使对于之前成功的那个,我们也会通过更多的训练来彻底摧毁我们所看到的好的一面。即使只进行一点额外的训练(12500 vs 9000),也使之看起来不像高斯过程。
首先,这不是神经网络高斯过程的独有现象。仅仅因为我们使用了分布而不是点估计,并不意味着这些方法给我们提供了适当的贝叶斯推论或者做了我们想要的。尽管上面我们有一个近似的后验,但后验本质上是一个质点。
贝叶斯方法最重要的部分之一是获得可靠的不确定性估计 - 如上所示,即使在简单的示例中也有可能得到一个在x=-4没有不确定性预测的神经过程,在这一点上,它从未见过任何数据。此外,我们可以看到的许多好的结果似乎都是非常特殊的初始化和恰到好处的训练量导致结果。
在一般的VAE公式中,先验是标准高斯函数。这意味着完全崩溃的后验有一些与之相关的成本。如果我们考虑两个高斯函数的分析KLD:
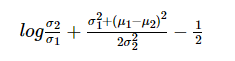
在这种表示法中,我们的近似后验用下标1表示,先验用下标2表示。这意味着σ2=1 在单变量的情况下。
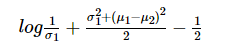
正如我们所看到的,使σ方法为零会产生一些小的成本(cost),但事实上它在log中,影响相当有限。σ1在我们获取大量成本之前,确实必须变得非常非常小。事实上,均值的差异显然是这里的主导因素。因此,即使对于普通的VAE,实际上并没有过多妨碍后验方差结果变小。
在神经高斯过程中,KLD散度是由下式给出的自适应先验来计算的。两者都来自同一个网络。
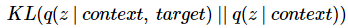
因为网络既能适应先验,又能适应后验,所以它能“欺骗”我们,而且两者的标准差都很小,并且几乎没有惩罚。要做到这一点,它必须学会使均值非常接近,这意味着包含目标点和不包含目标点的差别很小。
这篇文章是为了展示这些与VAE(变分自编码器)之间的联系,我觉得这很有启发性,并且展示了该方法的一些不足之处。所以,阅读本文前我建议你对VAE的工作知识有一定了解。此外,我不会讲神经过程的理论(因为你可以阅读论文和博客)。
最后,我会指出我认为是我在该方法中发现的一些相当重要的问题。我直接联系了论文的作者之一来讨论这些问题,但没有得到任何回应。我很高兴讨论一下,也许人们认为这些不足是由于我的错误或误解造成的,或者这些不足并不是什么大事。我没有在其他地方看到过这些内容,也没有讨论过这些内容,因此,这是对这种方法的缺点的讨论,而不是对这篇论文的攻击(事实上,我很喜欢这篇论文)。
VAE简介
VAE有一个简单的管道:
- 数据X输入“encoder network”输出q(Z| X.)的均值和方差。
- 对于每个数据点,使用重新参数化技巧从q生成一个潜在的样本
- 然后将该样本反馈到“'decoder network”中,该网络输出p (x | z)的均值和方差
- 生成重构数据点的样本(尽管通常只是平均值)。
与神经过程的比较
VAE编码单个数据点为潜在表示,并从其潜在变量中重构出数据点。如果我们正在学习图像的潜在表示,这就可以了,但是如果我们想要为函数执行此操作,我们还需要一个额外的步骤。
函数图(例如(X,sin(X))是在许多样本点上定义的。考虑嵌入以下函数:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x = np.arange(-4,5)
y = np.sin(x)
plt.scatter(x,y)
我们所认为的“函数空间”实际上是由所有这些数据点的x,y坐标的集合定义的。如果我们就这样继续进行(将其提供给VAE),它无法捕获正确的东西。因此,我们所做的是引入一个中间步骤,即生成“函数表示”,它是所有数据点的单一表示。如果你曾经做过NLP,那么它与句子或文档嵌入的概念相同。我们可以清楚看到下图和前一个图是等价的都是普通的VAE。
因此,正如图中所示,两个主要区别在于我们有一个额外的预处理步骤,我们将一个函数的多个点转换为一个表示,当我们重构时,我们同时使用潜在表示和我们想要预测的X* 。
Pytorch神经过程的实现
在这里,我有一个非常简单的PyTorch实现,它遵循与Kaspar博客文章中第一个示例行数一样。我也使用他的R-Tensorflow代码调试我自己的代码中的一些问题,所以非常感谢他发布自己的代码!
import numpy as np
import torch
import matplotlib.pyplot as plt
%matplotlib inline
class REncoder(torch.nn.Module):
"""Encodes inputs of the form (x_i,y_i) into representations, r_i."""
def __init__(self, in_dim, out_dim, init_func = torch.nn.init.normal_):
super(REncoder, self).__init__()
self.l1_size = 8
self.l1 = torch.nn.Linear(in_dim, self.l1_size)
self.l2 = torch.nn.Linear(self.l1_size, out_dim)
self.a = torch.nn.ReLU()
if init_func is not None:
init_func(self.l1.weight)
init_func(self.l2.weight)
def forward(self, inputs):
return self.l2(self.a(self.l1(inputs)))
class ZEncoder(torch.nn.Module):
"""Takes an r representation and produces the mean & standard deviation of the
normally distributed function encoding, z."""
def __init__(self, in_dim, out_dim, init_func=torch.nn.init.normal_):
super(ZEncoder, self).__init__()
self.m1_size = out_dim
self.std1_size = out_dim
self.m1 = torch.nn.Linear(in_dim, self.m1_size)
self.std1 = torch.nn.Linear(in_dim, self.m1_size)
if init_func is not None:
init_func(self.m1.weight)
init_func(self.std1.weight)
def forward(self, inputs):
softplus = torch.nn.Softplus()
return self.m1(inputs), softplus(self.std1(inputs))
class Decoder(torch.nn.Module):
"""
Takes the x star points, along with a 'function encoding', z, and makes predictions.
"""
def __init__(self, in_dim, out_dim, init_func=torch.nn.init.normal_):
super(Decoder, self).__init__()
self.l1_size = 8
self.l2_size = 8
self.l1 = torch.nn.Linear(in_dim, self.l1_size)
self.l2 = torch.nn.Linear(self.l1_size, out_dim)
if init_func is not None:
init_func(self.l1.weight)
init_func(self.l2.weight)
self.a = torch.nn.Sigmoid()
def forward(self, x_pred, z):
"""x_pred: No. of data points, by x_dim
z: No. of samples, by z_dim
"""
zs_reshaped = z.unsqueeze(-1).expand(z.shape[0], z.shape[1], x_pred.shape[0]).transpose(1,2)
xpred_reshaped = x_pred.unsqueeze(0).expand(z.shape[0], x_pred.shape[0], x_pred.shape[1])
xz = torch.cat([xpred_reshaped, zs_reshaped], dim=2)
return self.l2(self.a(self.l1(xz))).squeeze(-1).transpose(0,1), 0.005
def log_likelihood(mu, std, target):
norm = torch.distributions.Normal(mu, std)
return norm.log_prob(target).sum(dim=0).mean()
def KLD_gaussian(mu_q, std_q, mu_p, std_p):
"""Analytical KLD between 2 Gaussians."""
qs2 = std_q**2 + 1e-16
ps2 = std_p**2 + 1e-16
return (qs2/ps2 + ((mu_q-mu_p)**2)/ps2 + torch.log(ps2/qs2) - 1.0).sum()*0.5
r_dim = 2
z_dim = 2
x_dim = 1
y_dim = 1
n_z_samples = 10 #number of samples for Monte Carlo expecation of log likelihood
repr_encoder = REncoder(x_dim+y_dim, r_dim) # (x,y)->r
z_encoder = ZEncoder(r_dim, z_dim) # r-> mu, std
decoder = Decoder(x_dim+z_dim, y_dim) # (x*, z) -> y*
opt = torch.optim.Adam(list(decoder.parameters())+list(z_encoder.parameters())+
list(repr_encoder.parameters()), 1e-3)
未经训练的函数样本
x_grid = torch.from_numpy(np.arange(-4,4, 0.1).reshape(-1,1).astype(np.float32))
untrained_zs = torch.from_numpy(np.random.normal(size=(30, z_dim)).astype(np.float32))
mu, _ = decoder(x_grid, untrained_zs)
for i in range(mu.shape[1]):
plt.plot(x_grid.data.numpy(), mu[:,i].data.numpy(), linewidth=1)
plt.show()
正如我们所看到的,我们得到的'高斯过程'就像之前的函数样本一样。
训练
def random_split_context_target(x,y, n_context):
"""Helper function to split randomly into context and target"""
ind = np.arange(x.shape[0])
mask = np.random.choice(ind, size=n_context, replace=False)
return x[mask], y[mask], np.delete(x, mask, axis=0), np.delete(y, mask, axis=0)
def sample_z(mu, std, n):
"""Reparameterisation trick."""
eps = torch.autograd.Variable(std.data.new(n,z_dim).normal_())
return mu + std * eps
def data_to_z_params(x, y):
"""Helper to batch together some steps of the process."""
xy = torch.cat([x,y], dim=1)
rs = repr_encoder(xy)
r_agg = rs.mean(dim=0) # Average over samples
return z_encoder(r_agg) # Get mean and variance for q(z|...)
def visualise(x, y, x_star):
z_mu, z_std = data_to_z_params(x,y)
zsamples = sample_z(z_mu, z_std, 100)
mu, _ = decoder(x_star, zsamples)
for i in range(mu.shape[1]):
plt.plot(x_star.data.numpy(), mu[:,i].data.numpy(), linewidth=1)
plt.scatter(x.data.numpy(), y.data.numpy())
plt.show()
all_x_np = np.arange(-2,3,1.0).reshape(-1,1).astype(np.float32)
all_y_np = np.sin(all_x_np)
def train(n_epochs, n_display=3000):
losses = []
for t in range(n_epochs):
opt.zero_grad()
#Generate data and process
x_context, y_context, x_target, y_target = random_split_context_target(
all_x_np, all_y_np, np.random.randint(1,4))
x_c = torch.from_numpy(x_context)
x_t = torch.from_numpy(x_target)
y_c = torch.from_numpy(y_context)
y_t = torch.from_numpy(y_target)
x_ct = torch.cat([x_c, x_t], dim=0)
y_ct = torch.cat([y_c, y_t], dim=0)
# Get latent variables for target and context, and for context only.
z_mean_all, z_std_all = data_to_z_params(x_ct, y_ct)
z_mean_context, z_std_context = data_to_z_params(x_c, y_c)
#Sample a batch of zs using reparam trick.
zs = sample_z(z_mean_all, z_std_all, n_z_samples)
mu, std = decoder(x_t, zs) # Get the predictive distribution of y*
#Compute loss and backprop
loss = -log_likelihood(mu, std, y_t) + KLD_gaussian(z_mean_all, z_std_all,
z_mean_context, z_std_context)
losses.append(loss)
loss.backward()
opt.step()
if t % n_display ==0:
print(f"Function samples after {t} steps:")
x_g = torch.from_numpy(np.arange(-4,4, 0.1).reshape(-1,1).astype(np.float32))
visualise(x_ct, y_ct, x_g)
return losses
train(9001);
0步后的函数样本:
3000步后的函数样本:
6000步后的函数样本:
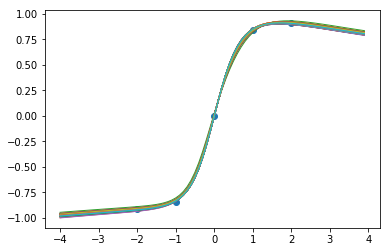
9000步后的函数样本:
当我们训练网络时,我们似乎在数据点内得到了很好的一致性,而当我们推断时,确定性降低了,这很不错!
关键的细节问题
在我的实现中,有一个看起来无伤大雅但实际至关重要的细节,我还没有谈过。那是我用过的权重初始化。大家会认为这是一件相当无关紧要的事情,但事实并非如此。例如,让我们重复上述步骤,但使用默认的PyTorch初始化。
repr_encoder = REncoder(x_dim+y_dim, r_dim, None) # (x,y)->r
z_encoder = ZEncoder(r_dim, z_dim, None) # r-> mu, std
decoder = Decoder(x_dim+z_dim, y_dim, None) # (x*, z) -> y*
opt = torch.optim.Adam(list(decoder.parameters())+
list(z_encoder.parameters())+list(repr_encoder.parameters()), 1e-3)
train(9001, 4500);
0步后的函数样本:
4500步后的函数样本:
9000步后的函数样本:
嗯,它似乎基本上崩溃(collapse)到一个确定性的函数。让我们试试Xavier标准化。
repr_encoder = REncoder(x_dim+y_dim, r_dim, torch.nn.init.xavier_normal_) # (x,y)->r
z_encoder = ZEncoder(r_dim, z_dim, torch.nn.init.xavier_normal_) # r-> mu, std
decoder = Decoder(x_dim+z_dim, y_dim, torch.nn.init.xavier_normal_) # (x*, z) -> y*
opt = torch.optim.Adam(list(decoder.parameters())+
list(z_encoder.parameters())+list(repr_encoder.parameters()), 1e-3)
train(9001, n_display=9000);
0步后的函数样本:
9000步后的函数样本:
这还是很奇怪。让我们重复第一个实验,但这一次,训练它的时间会更长一些。
repr_encoder = REncoder(x_dim+y_dim, r_dim) # (x,y)->r
z_encoder = ZEncoder(r_dim, z_dim) # r-> mu, std
decoder = Decoder(x_dim+z_dim, y_dim) # (x*, z) -> y*
opt = torch.optim.Adam(list(decoder.parameters())+
list(z_encoder.parameters())+list(repr_encoder.parameters()), 1e-3)
train(25001, n_display=12500);
0步后的函数样本:
12500步后的函数样本:
25000步后的函数样本:
因此,即使对于之前成功的那个,我们也会通过更多的训练来彻底摧毁我们所看到的好的一面。即使只进行一点额外的训练(12500 vs 9000),也使之看起来不像高斯过程。
这意味着什么?
首先,这不是神经网络高斯过程的独有现象。仅仅因为我们使用了分布而不是点估计,并不意味着这些方法给我们提供了适当的贝叶斯推论或者做了我们想要的。尽管上面我们有一个近似的后验,但后验本质上是一个质点。
贝叶斯方法最重要的部分之一是获得可靠的不确定性估计 - 如上所示,即使在简单的示例中也有可能得到一个在x=-4没有不确定性预测的神经过程,在这一点上,它从未见过任何数据。此外,我们可以看到的许多好的结果似乎都是非常特殊的初始化和恰到好处的训练量导致结果。
在这种情况下可能导致什么?
在一般的VAE公式中,先验是标准高斯函数。这意味着完全崩溃的后验有一些与之相关的成本。如果我们考虑两个高斯函数的分析KLD:
在这种表示法中,我们的近似后验用下标1表示,先验用下标2表示。这意味着σ2=1 在单变量的情况下。
正如我们所看到的,使σ方法为零会产生一些小的成本(cost),但事实上它在log中,影响相当有限。σ1在我们获取大量成本之前,确实必须变得非常非常小。事实上,均值的差异显然是这里的主导因素。因此,即使对于普通的VAE,实际上并没有过多妨碍后验方差结果变小。
在神经高斯过程中,KLD散度是由下式给出的自适应先验来计算的。两者都来自同一个网络。
x_context, y_context, x_target, y_target = random_split_context_target(
all_x_np, all_y_np, np.random.randint(1,4))
x_c = torch.from_numpy(x_context)
x_t = torch.from_numpy(x_target)
y_c = torch.from_numpy(y_context)
y_t = torch.from_numpy(y_target)
x_ct = torch.cat([x_c, x_t], dim=0)
y_ct = torch.cat([y_c, y_t], dim=0)
mu_ct, std_ct = data_to_z_params(x_ct,y_ct)
mu_c, std_c = data_to_z_params(x_c,y_c)
print("mu context, target: " ,mu_ct.data.numpy(), "\n mu context: ",mu_c.data.numpy())
print("*"*40)
print("sigma context, target: " ,std_ct.data.numpy(), "\n sigma context: ",std_c.data.numpy())mu context, target: [0.4896406 0.23645595]
mu context: [0.48979104 0.2365925 ]
****************************************
sigma context, target: [0.0069707 0.01075098]
sigma context: [0.00784972 0.01087389]
z_mean_all, z_std_all = data_to_z_params(x_ct, y_ct)
z_mean_context, z_std_context = data_to_z_params(x_c, y_c)
print("KLD value: ",KLD_gaussian(z_mean_all, z_std_all, z_mean_context, z_std_context).data.numpy())
KLD value: 0.013441861
因为网络既能适应先验,又能适应后验,所以它能“欺骗”我们,而且两者的标准差都很小,并且几乎没有惩罚。要做到这一点,它必须学会使均值非常接近,这意味着包含目标点和不包含目标点的差别很小。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
最小二乘法从何而来








广告


写评论取消
回复取消