


















深度学习语义分割的入门指导和代码
什么是语义分割?
深度学习和计算机视觉群体中的大多数人都了解图像分类是什么:希望我们的模型告诉我们图像中存在什么物体或场景。分类非常宽泛且高级。
许多人也熟悉对象检测,我们通过在图像中绘制边界框对框中的内容进行分类来定位和分类图像中的多对象。检测是中级的,我们有一些非常有用和详细的信息,但它仍然有点宽泛,因为我们只绘制边界框并没有真正准确地了解对象形状。
语义分割是这三者中信息最丰富的,如你在图中看到的一样,我们希望对图像中的每个像素进行分类!在过去的几年里,这完全是通过深度学习完成的。

本文将详细介绍语义分割模型的基本结构和工作原理,以及所有最新和最先进的方法。如果你想自己试用这些模型,请访问Github获取完整的TensorFlow训练和测试代码!
GitHub:https://github.com/GeorgeSeif/Semantic-Segmentation-Suite
基本结构
我即将向展示的语义分割模型的基本结构存在于所有最先进的方法中。这使得实现不同的模型很容易,因为它们几乎都具有相同的底层主干、设置和流。
U-Net模型很好地说明了这种结构。模型的左侧表示经过训练用于图像分类的任何特征提取网络。包括VGGNet,ResNets,DenseNets,MobileNets和NASNets等网络!你可以用任何你想用的东西。
选择分类网络进行特征提取时,最主要的事情是要注重权衡。使用非常深的ResNet152将获得极高的准确性,但不会像MobileNet那样快。权衡在将这些网络应用于分类时出现,也会在使用它们进行分割时出现。需要记住的重要一点是,在设计/选择分割网络时,这些主干将成为主要驱动因素。所以,我再怎么强调也不为过。
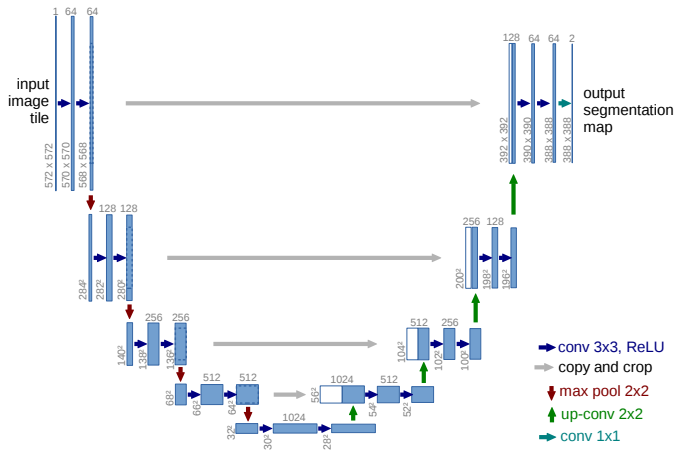
用于分割的U-Net模型
一旦提取了这些特征,它们就会以不同的尺度进一步处理。原因有两方面。首先,模型很可能会遇到许多不同大小的物体;处理不同尺度的特征将使网络具有处理这些不同大小的特征能力。
其次,在进行分割时需要权衡。如果想要良好的分类准确性,那么你肯定希望在网络后期处理这些高级特征,因为它们更具有识别力并包含更多有用的语义信息。另一方面,如果只处理这些深层特征,由于分辨率低,你将无法获得良好的定位!
最近的最先进方法都遵循上述多尺度特征处理的提取结构。因此,许多很容易实施和端对端的训练。选择使用哪一个取决于你对准确性与速度或内存的需求,因为所有人都在尝试找出解决这种权衡的新方法(高准确性的同时保持效率)。
在接下来,我将重点介绍最新的方法,因为在理解了上述基本结构之后,这些方法对大多数读者最有用。我们将按照大致的时间顺序进行演练,这也大致对应于最先进的技术进步。
最先进的演练
全分辨率剩余网络(FRRN)
FRRN模型是多尺度处理技术的明显例子。它使用2个独立的流机制完成此操作:剩余流(residual stream)和池化流(pooling stream)。
我们希望处理这些语义特征以获得更高的分类准确性,因此FFRRN逐步处理并向下采样池流中的特征映射。同时,它在剩余流中以全分辨率处理特征映射。因此,池化流处理高级语义信息(用于高分类精度),剩余流处理低级像素信息(用于高定位精度)!
现在,由于我们正在训练端到端网络,因此我们不希望这两个流完全分离。因此,在每次最大池化之后,FRRN对两个流中的特征映射进行联合处理,以组合它们的信息。
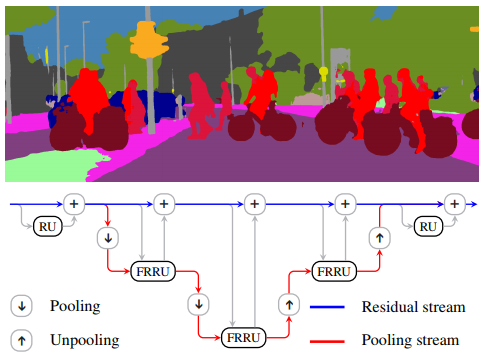
FRRN模型结构
金字塔场景解析网络(PSPNet)
FRRN在直接执行多尺度处理方面做得很好。但是,在每个尺度上进行大量处理都是计算密集型的。此外,FRRN在全分辨率下进行一些处理,非常的慢!
PSPNet提出了一种巧妙的方式,通过使用多尺度的池化来解决这个问题。它从标准特征提取网络(ResNet,DenseNet等)开始,采用第三次下采样的特征进行进一步处理。
为了获得多尺度信息,PSPNet应用4种不同的最大池化操作,它们具有4种不同的窗口大小和步幅。这有效地捕获了4个不同尺度的特征信息,而无需对每个尺度进行繁重的单独处理!我们只需对每个进行轻量级卷积,然后进行上采样,以便每个特征映射具有相同的分辨率,然后将它们全部连接起来。
瞧!我们结合了多尺度特征映射,且没有对它们进行很多次卷积!
所有这些都是在较低分辨率特征映射上高速完成的。最后,我们使用双线性插值调高输出分割映射到所需的大小。在许多最先进的工作中,只有在完成所有的处理之后才进行调高。
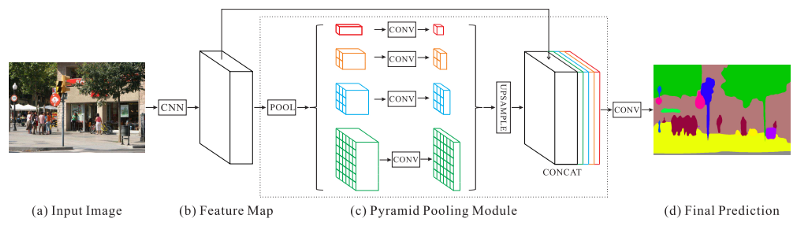
PSPNet模型结构
一百层提拉米苏(FCDenseNet)
如果深度学习带来了哪种可怕的趋势,其中一定有可怕的研究论文名称!在Hundred Layers Tiramisu FCDenseNet(听起来就好吃!)采用了类似U-Net的结构。它主要贡献是巧妙地使用了密集连接,类似于DenseNet分类模型。
这真正强调了计算机视觉的强劲趋势,其中特征提取前端是在任何其他任务上表现良好的主要支柱。因此,首先要寻找准确率提高的地方,通常是特征提取前端。
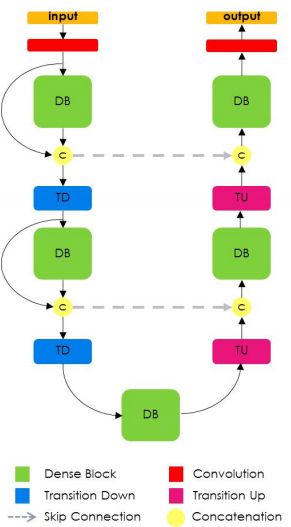
FCDenseNet模型结构
反思多孔卷积(DeepLabV3)
DeepLabV3是另一种做多尺度处理的巧妙方法,这个时候不增加参数。
这个型号非常轻巧。我们还是从特征提取前端开始,取第4次下采样的功能进行进一步处理。这个分辨率非常低(比输入小16倍),如果我们能在这里处理就太好了!棘手的是,在如此低的分辨率下,由于像素精度差,很难获得良好的定位。
这就是DeepLabV3的主要贡献所在,聪明地使用Atrous卷积。常规卷积只能处理非常有限的信息,因为权重总是紧挨着的。例如,在标准3x3卷积中,一个权重与任何其他权重之间的距离仅为单一个步长/像素。
对于多孔卷积(atrous convolution),我们将直接增加卷积权重之间的间距,而不会增加操作中的权重数量。所以我们仍然使用总共9个参数的3x3,我们只是将我们权重间隔得更远!每个权重之间的距离称为膨胀率(dilation rate)。下面的模型图很好地说明了这个想法。
当我们使用低膨胀率时,我们将处理局部的/低尺度的信息。当我们使用高膨胀率时,我们处理全局的/高尺度的信息。因此,DeepLabV3模型将混合多孔卷曲与不同的膨胀率以捕获多尺度信息。
这里还介绍了PSPNet在所有处理后的最后进行调高的技术。

DeepLabV3模型结构
多路径细化网络(RefineNet)
我们之前看到,FRRN如何很好地直接组合来自多个分辨率的信息并将它们集合在一起。缺点是在如此高分辨率下的处理是计算密集型的,我们仍然必须处理并将这些特征与低分辨率组合在一起!
RefineNet模型表示,并不需要这样做。当我们通过特征提取网络运行输入图像时,我们自然会在每次下采样后得到多尺度特征映射。
然后,RefineNet以自下而上的方式处理这些多分辨率特征映射,以组合多尺度信息。首先,每个特征映射都是独立处理的。然后,当我们升级时,我们将低分辨率特征映射与更高分辨率的特征映射组合在一起,对它们进行进一步处理。因此,多尺度特征映射既可以独立处理,也可以一起处理。整个过程在下图中从左向右移动。
这里还介绍了在所有处理之后最后进行调高的技术,如PSPNet和DeepLabV3所解释的那样。
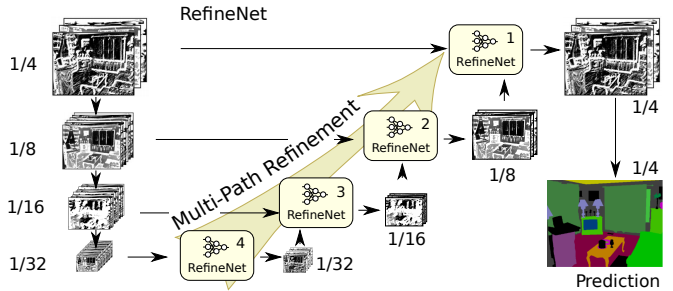
RefineNet模型结构
大内核问题(GCN)
此前,我们看到了DeepLabV3模型如何使用具有不同膨胀率的多孔卷积来捕获多尺度信息。这这个问题的棘手之处在于,我们一次只能处理一个尺度,之后必须将它们组合起来。例如,具有16膨胀率的多孔卷积将不能很好地利用局部信息,并且随后必须与来自具有小得多的膨胀率的卷积信息组合才能在语义分割中表现良好。
这是因为,在之前的方法中,多尺度处理首先是单独进行的,然后将结果组合在一起。我们最好能够一次性获得多尺度信息。
为此,全局卷积网络(GCN)提出使用大的一维内核替代方形内核。对于3x3,7x7等方形卷积,如果不大幅提高算力和内存消耗,就无法将它们做得太大。另一方面,一维内核的膨胀效率更高,而不会过度减慢网络速度(这篇论文甚至一直都达到15!)。
论文:https://arxiv.org/pdf/1703.02719.pdf
但你必须确保平衡水平和垂直卷积。此外,本文确实使用了具有低滤波器数的小的3x3卷积,以有效地细化一维卷积可能遗漏的内容。
GCN遵循与之前架构相同的样式,通过从特征提取前端处理每个尺度。由于一维卷积的高效率,GCN在所有尺度上执行处理直到全分辨率,不再进行先小后调高的模式。这是我们可以随尺度放大不断细化分割,而会由于保持较低分辨率而发生瓶颈。
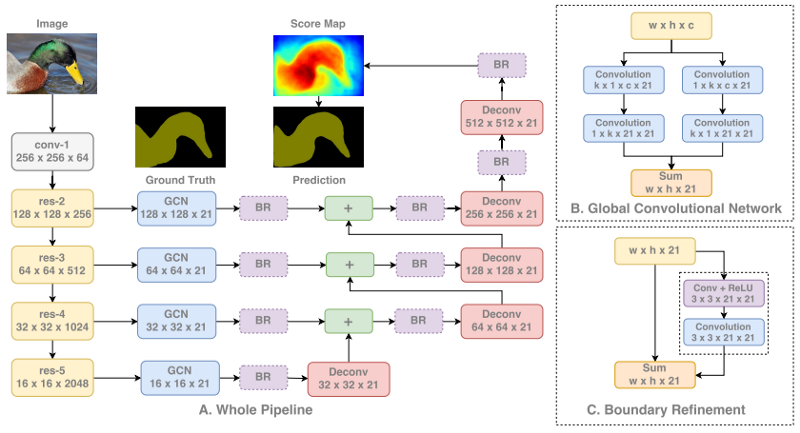
GCN模型结构
DeepLabV3 +
顾名思义,DeepLabV3+模型是DeepLabV3的快速扩展,它借鉴了之前的一些思路。正如我们之前看到的,如果我们只是简单地等待在网络末端使用双线性插值进行调高,则存在潜在的瓶颈。事实上,最初的DeepLabV3模型最终调高到x16!
为了解决这个问题,DeepLabV3 +在DeepLabV3之上添加一个中间解码器模块。在通过DeepLabV3处理之后,然后通过x4对特征进行上采样。然后,在通过x4再次调高之前,它们与特征提取前端的原始特征一起进一步处理。这减轻了网络末端的负载,并提供了从特征提取前端到网络近端的捷径。
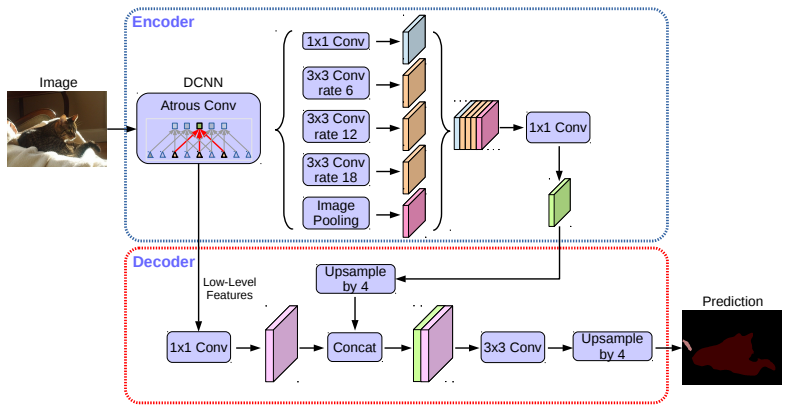
DeepLabV3 +模型结构
CVPR和ECCV 2018
我们在上面介绍的网络代表了进行语义分割时需要了解的大部分技术!今年在计算机视觉会议上发布的大部分内容都是微小的更新和准确性的小小提升,相对并不是非常关键。为了更全面,我在这里为任何感兴趣的人提供一个他们的贡献的快速回顾!
Image Cascade Network (ICNet) - 使用深度监监督并以不同的尺度运行输入图像,每个尺度通过各自的子网络,逐步组合结果。
Discriminative Feature Network (DFN) - 使用深度监督并尝试分别处理片段的平滑和边缘部分
DenseASPP - 将稠密连接与多孔卷曲相结合
Context Encoding - 通过添加通道注意模块来利用全局上下文来提高准确性,该模块基于新设计的损失函数触发对某些特征映射的注意。这个损失函数基于网络分支,该网络分支预测图像中存在哪些类(即,更高级别的全局上下文)。
Dense Decoder Shortcut Connections - 在解码阶段使用稠密连接以获得更高的精度(以前只在特征提取/编码期间使用)。
Bilateral Segmentation Network (BiSeNet) - 有2个分支:一个用于深入获取语义信息,另一个用于对输入图像进行很少的处理以保留低级像素信息。
ExFuse - 使用深度监督并在处理之前明确组合特征提取前端的多尺度特征,以确保多尺度信息在各级同时处理。
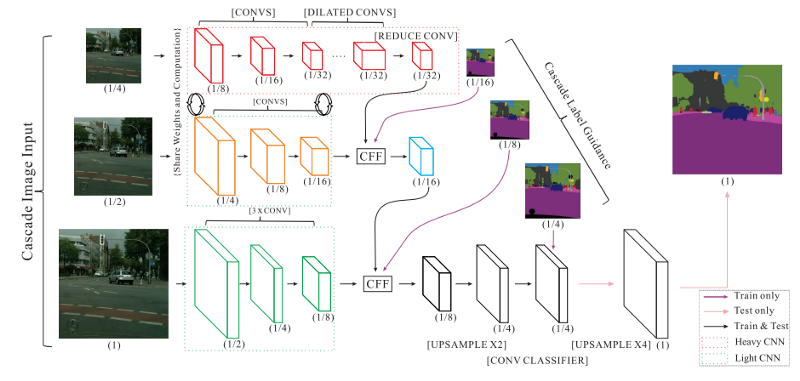
ICNet模型结构









