











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






RetentionScience评估机器学习预测:客户流失和CLV [RS Labs]
2018年09月21日 由 荟荟 发表
736210
0
在Retention Science,我们致力于使机器学习和人工智能更容易理解。本博客介绍了我们评估两个关键预测模型(客户流失预测和客户未来价值(CFV))准确性的过程。这两个预测为如何让客户保持参与提供了宝贵的见解。
我们的评估框架目的是双重的。在内部,它可以帮助我们为手头的预测问题选择性能最佳的预测模型。其次,它作为营销人员的报告工具来检查模型的预测准确性。
流失预测评估
方法:在我们之前的博客文章中,我们描述了我们如何构建和调整我们的流失模型。在给定日期,我们的模型预测每个用户的流失概率。由于这些原始概率不可行,我们根据概率将这些概率分为三个部分:低,中和高流失组。
一旦预测完成,我们等待保持时间 - 通常约3个月 - 来评估模型在该期间的表现。通过使用该保留期作为基线,我们可以定义我们认为流失的标签。例如,我们可以说一个购物者在这3个月内没有购买。然后我们继续评估不同的指标。
流失评估指标:指标分为两类:与流失细分相关的评估指标,二进制分类性能
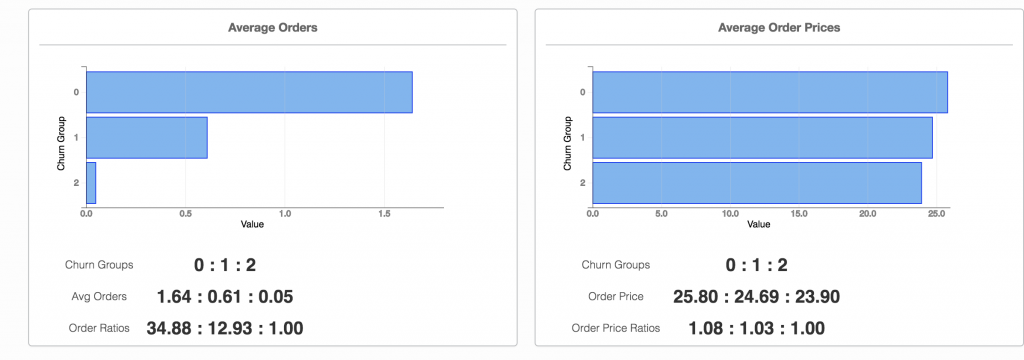
第一类指标显示了流失群体的歧视程度。我们为每个流失组提供流失率,在保留时间内每组用户的平均订单数量以及组中每个用户的平均订单价格(参见图1)
这告诉营销人员对流失段的行为有何歧视性。可以基于不同段相对于彼此的行为来做出营销决策。例如,当营销人员制定激励决策时,与低概率流失用户相比,了解用户平均带来多少高流失概率会很有帮助。
第二类指标评估原始客户流失评分预测。我们使用它来计算评估指标,例如 F-措施,ROC曲线,精确回忆曲线,可靠性曲线
这些不同的强大指标为您的营销团队中的数据科学家/分析师提供了有关流失模型能够对流失者和非流失者进行分类的信息 - 例如,预计流失的人数实际上是多少 - 以及可能比较它带有标准基线。每个指标对于流氓和非流氓的不同分布都是健壮的,并且对性能有自己的见解。可靠性曲线将概率校准为真正的流失率,从而获得更好的可解释性。
[caption id="attachment_30074" align="aligncenter" width="1024"]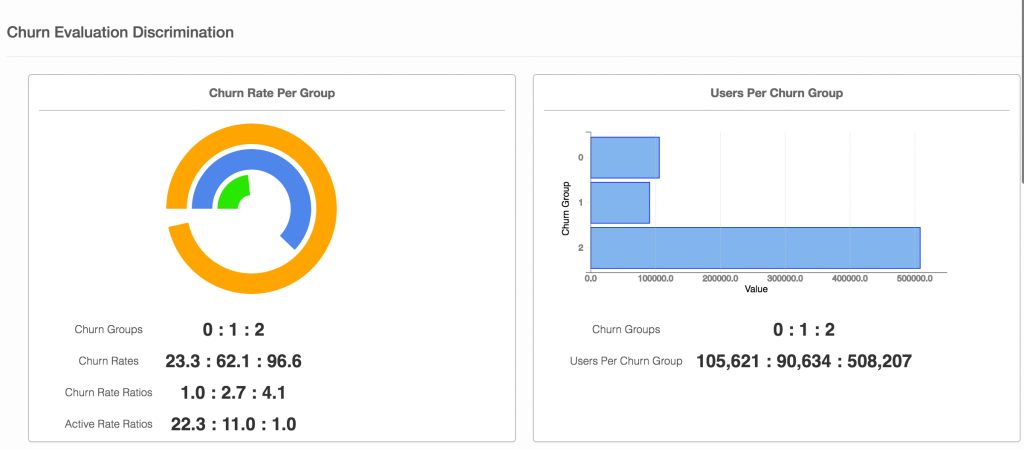 图1.1流失段结果显示在RS-Sauron上[/caption]
图1.1流失段结果显示在RS-Sauron上[/caption]
[caption id="attachment_30076" align="aligncenter" width="1024"]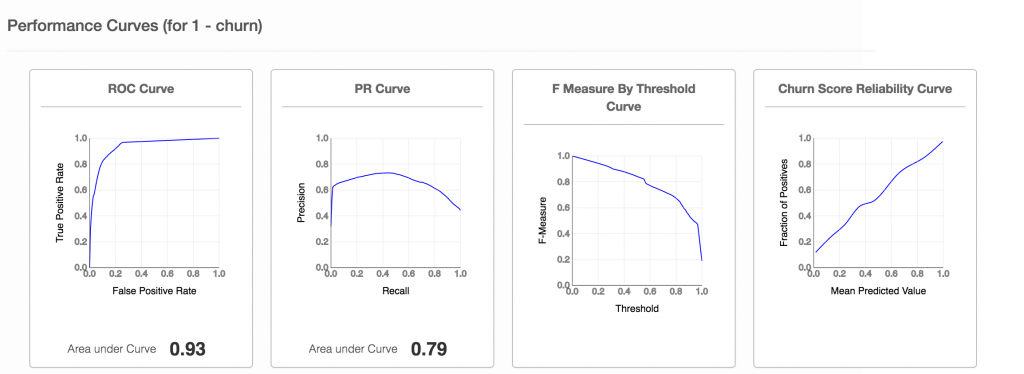 图1.2评估二元分类的测量[/caption]
图1.2评估二元分类的测量[/caption]
CFV验证:
我们将客户生命周期价值(CLV)定义为用户的过去值(观察到的组件)和未来值(预测组件)的总和。一个重要的CRM预测是用户将来会带来多少价值 - 在ReSci,我们使用全利润分析。
方法:与流失模型类似,在给定日期,我们的模型预测用户将在下一个'n'个月内带来的预期值,并根据值将其分为三组:低,中和高值。我们等待暂停时间('n'个月),然后看看未来如何展开 - 以及我们的预测是多么准确。
一旦我们获得了用户购买的真实价值,该数字就可用于评估我们预测用户将带来的价值.CFV评估指标分为两类:CFV整体准确度指标 集团CFV歧视指标
总体准确度指标提供用户级准确度和站点级(公司范围内)准确性。用户级精度显示有多少预测用户值被超出,有多少我们得到了完全正确,平均绝对误差是多少。它提供了其他统计指标,如Pearson的Correlation和RMSE。
[caption id="attachment_30079" align="aligncenter" width="1024"]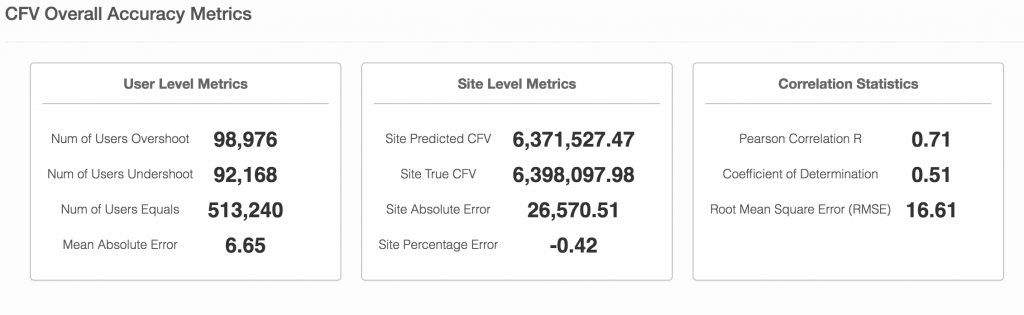 图2.1。结果描述了整体未来的收入评估[/caption]
图2.1。结果描述了整体未来的收入评估[/caption]
[caption id="attachment_30080" align="aligncenter" width="1024"]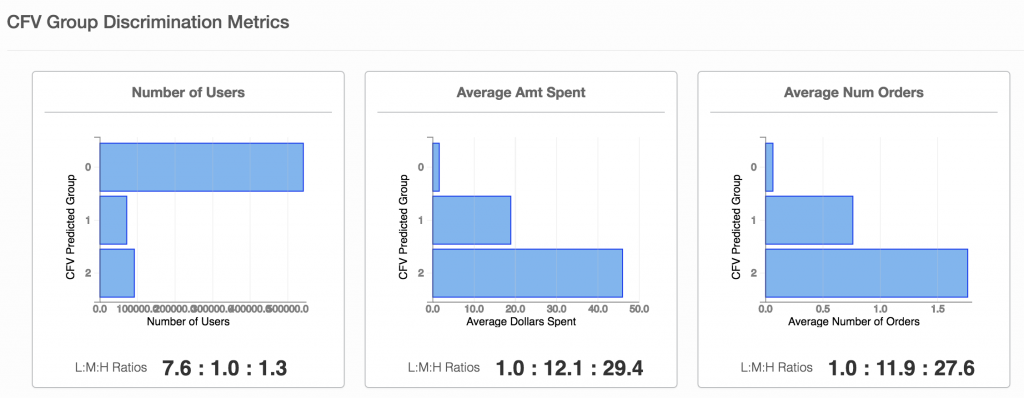 图2.2描述CFV组区分的结果[/caption]
图2.2描述CFV组区分的结果[/caption]
第二类指标是群体级别歧视指标。如前所述,营销人员可以在未来价值方面拥有3个用户群:低,中,高价值客户。然后,我们衡量这些群体的表现 - 每个群体平均带来多少价值,以及每个群体带来的订单数量。
结论:
为了减少机器学习的负担并自动监控,我们已经建立了电子邮件警报,如果这些评估参数中的任何一个稍微下降,就会发出警告。这样,我们就能够跟踪模型的性能并确保我们保持最佳状态。
我们的评估框架目的是双重的。在内部,它可以帮助我们为手头的预测问题选择性能最佳的预测模型。其次,它作为营销人员的报告工具来检查模型的预测准确性。
流失预测评估
方法:在我们之前的博客文章中,我们描述了我们如何构建和调整我们的流失模型。在给定日期,我们的模型预测每个用户的流失概率。由于这些原始概率不可行,我们根据概率将这些概率分为三个部分:低,中和高流失组。
一旦预测完成,我们等待保持时间 - 通常约3个月 - 来评估模型在该期间的表现。通过使用该保留期作为基线,我们可以定义我们认为流失的标签。例如,我们可以说一个购物者在这3个月内没有购买。然后我们继续评估不同的指标。
流失评估指标:指标分为两类:与流失细分相关的评估指标,二进制分类性能
第一类指标显示了流失群体的歧视程度。我们为每个流失组提供流失率,在保留时间内每组用户的平均订单数量以及组中每个用户的平均订单价格(参见图1)
这告诉营销人员对流失段的行为有何歧视性。可以基于不同段相对于彼此的行为来做出营销决策。例如,当营销人员制定激励决策时,与低概率流失用户相比,了解用户平均带来多少高流失概率会很有帮助。
第二类指标评估原始客户流失评分预测。我们使用它来计算评估指标,例如 F-措施,ROC曲线,精确回忆曲线,可靠性曲线
这些不同的强大指标为您的营销团队中的数据科学家/分析师提供了有关流失模型能够对流失者和非流失者进行分类的信息 - 例如,预计流失的人数实际上是多少 - 以及可能比较它带有标准基线。每个指标对于流氓和非流氓的不同分布都是健壮的,并且对性能有自己的见解。可靠性曲线将概率校准为真正的流失率,从而获得更好的可解释性。
[caption id="attachment_30074" align="aligncenter" width="1024"]
图1.1流失段结果显示在RS-Sauron上[/caption][caption id="attachment_30076" align="aligncenter" width="1024"]
图1.2评估二元分类的测量[/caption]CFV验证:
我们将客户生命周期价值(CLV)定义为用户的过去值(观察到的组件)和未来值(预测组件)的总和。一个重要的CRM预测是用户将来会带来多少价值 - 在ReSci,我们使用全利润分析。
方法:与流失模型类似,在给定日期,我们的模型预测用户将在下一个'n'个月内带来的预期值,并根据值将其分为三组:低,中和高值。我们等待暂停时间('n'个月),然后看看未来如何展开 - 以及我们的预测是多么准确。
一旦我们获得了用户购买的真实价值,该数字就可用于评估我们预测用户将带来的价值.CFV评估指标分为两类:CFV整体准确度指标 集团CFV歧视指标
总体准确度指标提供用户级准确度和站点级(公司范围内)准确性。用户级精度显示有多少预测用户值被超出,有多少我们得到了完全正确,平均绝对误差是多少。它提供了其他统计指标,如Pearson的Correlation和RMSE。
[caption id="attachment_30079" align="aligncenter" width="1024"]
图2.1。结果描述了整体未来的收入评估[/caption][caption id="attachment_30080" align="aligncenter" width="1024"]
图2.2描述CFV组区分的结果[/caption]第二类指标是群体级别歧视指标。如前所述,营销人员可以在未来价值方面拥有3个用户群:低,中,高价值客户。然后,我们衡量这些群体的表现 - 每个群体平均带来多少价值,以及每个群体带来的订单数量。
结论:
为了减少机器学习的负担并自动监控,我们已经建立了电子邮件警报,如果这些评估参数中的任何一个稍微下降,就会发出警告。这样,我们就能够跟踪模型的性能并确保我们保持最佳状态。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消