











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






伯克利智能体观看视频片段学习动作技能,无需手动标注
2018年10月10日 由 浅浅 发表
519119
0
 无论是像洗手这样的日常动作还是惊人的杂技技能,人类都可以通过观察其他人来学习。随着YouTube等来源的公开视频数据的激增,现在比以往任何时候都更容易找到我们感兴趣的任何技能的视频剪辑。每分钟都会有300小时视频上传到YouTube。不幸的是,我们的机器从大量的视觉数据中学习技能仍然非常具有挑战性。大多数模仿学习方法都需要简洁的表征,例如从动作捕捉(mocap)记录的表征。但获取mocap数据可能非常麻烦,通常需要大量的仪器。Mocap系统也往往局限于室内环境,闭塞程度最小,这可以限制可记录的技能类型。如果我们的智能体也可以通过观看视频片段来学习技能,那就相当好了。
无论是像洗手这样的日常动作还是惊人的杂技技能,人类都可以通过观察其他人来学习。随着YouTube等来源的公开视频数据的激增,现在比以往任何时候都更容易找到我们感兴趣的任何技能的视频剪辑。每分钟都会有300小时视频上传到YouTube。不幸的是,我们的机器从大量的视觉数据中学习技能仍然非常具有挑战性。大多数模仿学习方法都需要简洁的表征,例如从动作捕捉(mocap)记录的表征。但获取mocap数据可能非常麻烦,通常需要大量的仪器。Mocap系统也往往局限于室内环境,闭塞程度最小,这可以限制可记录的技能类型。如果我们的智能体也可以通过观看视频片段来学习技能,那就相当好了。在这项工作中,我们提出了一个从视频(SFV)学习技能的框架。通过结合计算机视觉和强化学习方面的最先进技术,我们的系统使模拟角色能够从视频剪辑中学习各种各样的技能。给定演员执行某些技能的单个单眼视频,例如侧翻或后空翻,我们的角色能够学习在物理模拟中再现该技能的策略,而无需任何手动姿势标注。
[video width="854" height="480" mp4="https://www.atyun.com/uploadfile/2018/10/SIGGRAPH-Asia-2018_-Skills-from-Videos-paper-main-video.mp4"][/video]
从视频学习全身动作技能的问题在计算机图形学中受到了一些关注。以前的技术通常依赖于手工制作的控制结构,这些控制结构对可以产生的行为施加了强大的限制。因此,这些方法往往受限于可以学习的技能类型,并且所产生的动作看起来相当不自然。最近,深度学习技术已经证明了在诸如Atari等领域的视觉模仿以及相当简单的机器人任务方面有希望的结果。但是这些任务通常只在演示和代理的环境之间进行适度的域转换,并且持续控制的结果主要是在动态相对简单的任务上。
框架
我们的框架结构作为管道,由三个阶段组成:姿势估计,动作重建和动作模仿。输入视频首先由姿势估计阶段处理,姿势估计阶段预测每帧中演员的姿势。接下来,动作重建阶段将姿势预测合并到参考动作中并修复可能由姿势预测引入的伪像。最后,参考动作被传递到动作模拟阶段,其中训练模拟角色以使用强化学习来模仿动作。
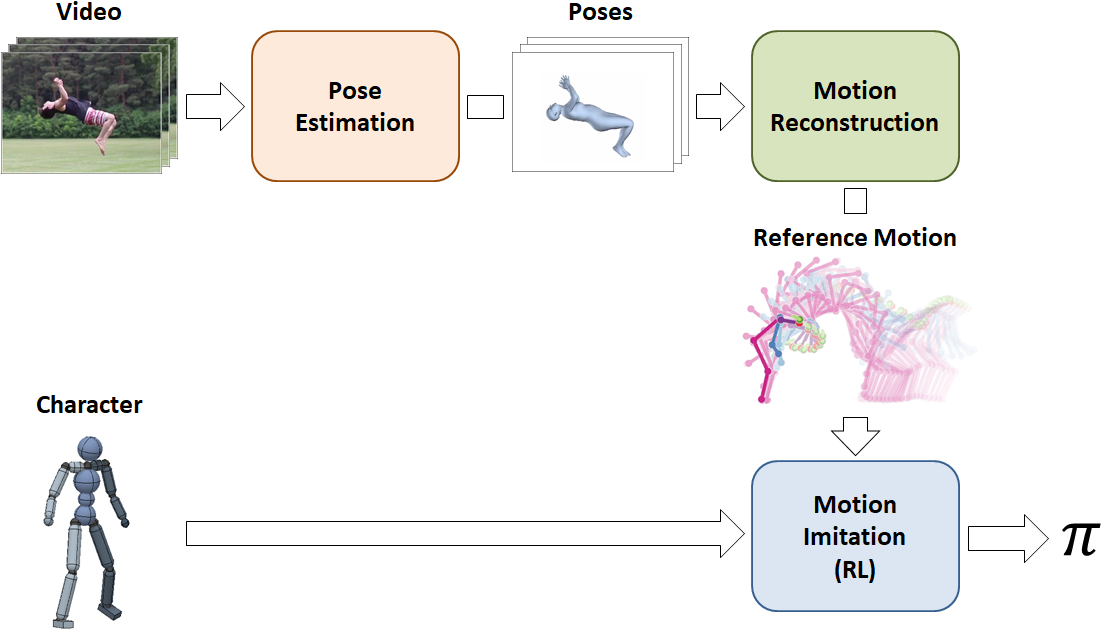
该管道包括三个阶段:姿势估计,动作重建和动作模仿。它接收作为输入的执行特定技能的演员和模拟角色模型的视频剪辑,并学习使角色能够在物理模拟中再现技能的控制策略。
姿势估计
给定视频剪辑,我们使用基于视觉的姿势估计器来预测每个帧中演员的姿势。姿势估计器建立在人体网格恢复的工作之上,该网格恢复使用弱监督的对抗方法来训练姿势估计器以预测来自单眼图像的姿势。虽然需要姿势注释来训练姿势估计器,但是一旦经过训练,姿势估计器可以应用于新图像而无需任何标注。


基于视觉的姿势估计器用于预测每个视频帧中的演员的姿势。
动作重建
由于姿势估计器针对每个视频帧独立地预测演员的姿势,因此帧之间的预测可能不一致,从而导致抖动伪像。此外,虽然近年来基于视觉的姿势估计器已经大大改善,但它们仍然偶尔会犯一些相当大的错误,这可能导致偶尔会出现奇怪的姿势。这些文物可以产生物理上不可能模仿的动作。因此,动作重建阶段的作用是减轻这些伪影,以便产生更加物理上合理的参考动作,这将使模拟人物更容易模仿。为此,我们优化新的参考动作
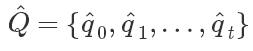 ,以满足以下目标:
,以满足以下目标: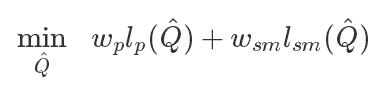
其中
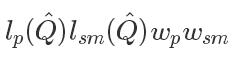 鼓励参考动作类似于原始姿势预测,并且使相邻帧中的姿势相似,以便产生更平滑的动作。
鼓励参考动作类似于原始姿势预测,并且使相邻帧中的姿势相似,以便产生更平滑的动作。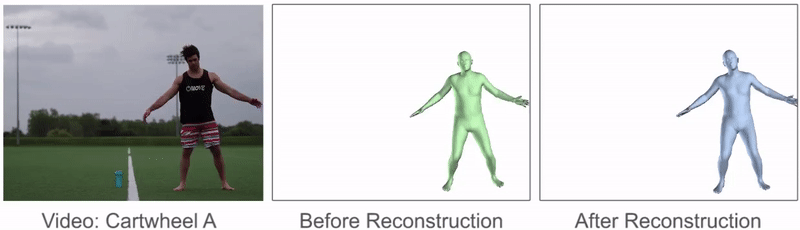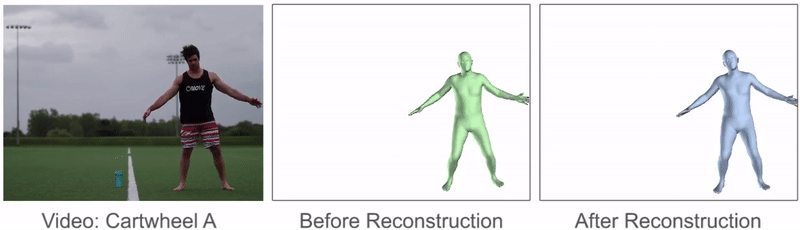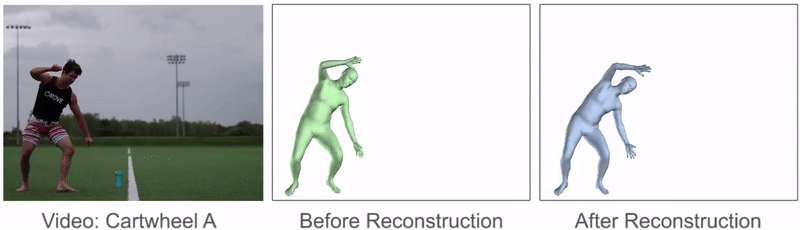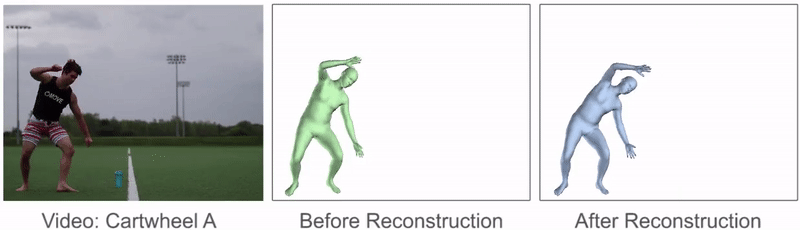
该过程可以显着改善参考动作的质量,并且可以从原始姿势预测中修复许多伪像。动作重建前后参考动作的比较。动作重建可减轻许多伪影并产生更平滑的参考动作。
动作模仿
一旦我们有参考动作
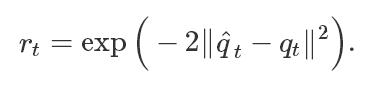
同样,这种简单的方法最终工作得非常好,我们的角色能够学习各种具有挑战性的杂技技巧,其中每项技能都是通过单个视频演示学习的。




模拟人形机器人学习通过模仿视频剪辑来执行各种技能。
结果
总的来说,我们的角色能够从YouTube收集的各种视频剪辑中学习20多种不同的技能。

我们的框架可以通过视频演示学习大量的技能。
尽管我们角色的形态通常与视频中的演员完全不同,但政策仍然能够密切复制许多技能。作为更极端的形态差异的一个例子,我们还可以训练模拟的Atlas机器人来模仿人类的视频剪辑。
拥有模拟角色的一个优点是我们可以利用模拟将行为推广到新环境。在这里,我们模拟了人物学会使动作适应不规则地形,原始视频剪辑是从平地上的演员录制的。


动作可以适应不规则的环境。
尽管环境与原始视频中的环境完全不同,但学习算法仍然为处理这些新环境制定了相当合理的策略。
总而言之,我们的框架实际上只是采取了解决视频模仿问题时任何人都能想到的最明显的方法。关键在于将问题分解为更易于管理的组件,为这些组件选择正确的方法,并将它们有效地集成在一起。然而,模仿视频技能仍然是一个极具挑战性的问题,而且有很多视频剪辑我们还无法重现:
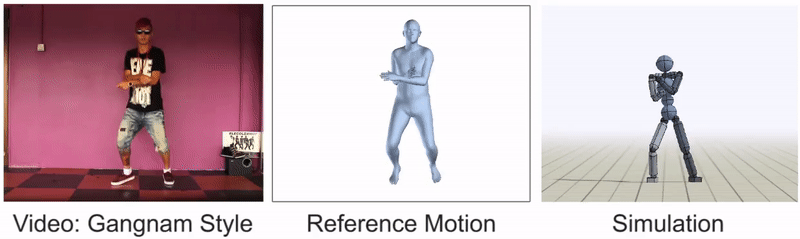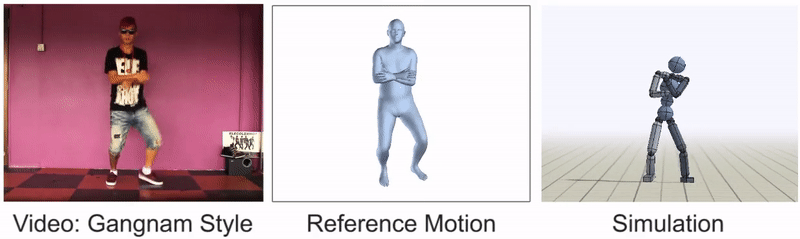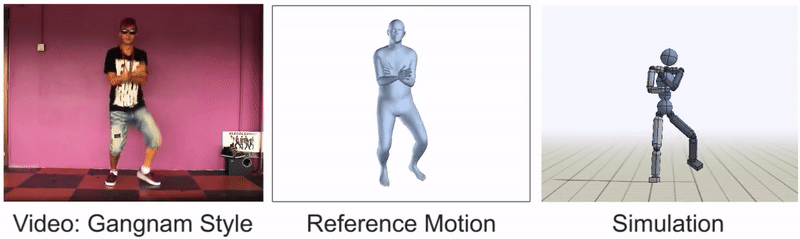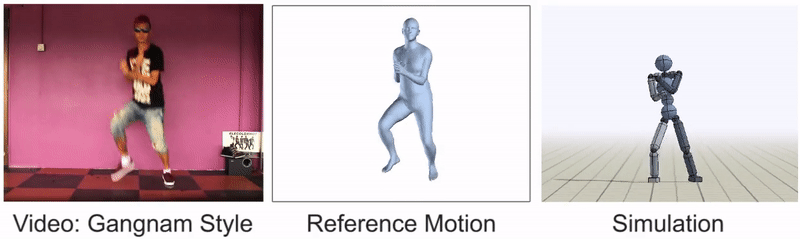
灵活的舞步,如这个Gangnam Style的剪辑,仍然很难模仿。
但令人鼓舞的是,仅仅通过整合现有技术,我们就可以在这个具有挑战性的问题上取得相当大的进展。我们希望这项工作能够激发未来的技术,使智能体能够利用大量公开的视频数据来获得真正惊人的技能。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消