











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






腾讯AI Lab开源了覆盖性广、准确性高的汉语词汇语料库
2018年10月19日 由 浅浅 发表
689578
0
 腾讯开源了一个语料库,为超过800万个汉语词汇提供了200维向量表征,即嵌入,这些词汇是在大规模高质量数据上预先训练的。这些向量捕获中文单词和短语的语义含义,可以广泛应用于许多下游中文处理任务(例如,命名实体识别和文本分类)以及进一步的研究中。
腾讯开源了一个语料库,为超过800万个汉语词汇提供了200维向量表征,即嵌入,这些词汇是在大规模高质量数据上预先训练的。这些向量捕获中文单词和短语的语义含义,可以广泛应用于许多下游中文处理任务(例如,命名实体识别和文本分类)以及进一步的研究中。数据描述
预训练的嵌入在Tencent_AILab_ChineseEmbedding.txt中。第一行显示嵌入的总数及其尺寸大小,以空格分隔。在下面的每一行中,第一列表示中文单词或短语,后跟一个选项卡及其嵌入。对于每次嵌入,其在不同维度中的值由空格分隔。
强调
与现有的汉语嵌入语料库相比,该语料库的优越性主要在于覆盖率,新鲜度和准确性。
- 覆盖范围。我们的语料库包含大量特定领域的词汇或词汇俚语,如“喀拉喀什河”,“皇帝菜”,“不念僧面念佛面”,“冰火两重天”,“煮酒论”英雄,大多数现有的嵌入语料库都没有涵盖。
- 新鲜度。我们的语料库包含最近出现或流行的新词,如“恋与制作人”,“三生三世十里桃花”,“打电话”,“十动然拒”,“因吹斯汀”等。
- 准确性。我们的嵌入可以更好地反映中文单词或短语的语义,归因于大规模数据和精心设计的训练算法。
训练
为了确保语料库的覆盖范围,新鲜度和准确性,我们从以下几个方面精心设计了数据准备和训练流程:
- 数据收集。我们的训练数据包含从新闻,网页和小说收集的大型文本。来自不同域的文本数据使得能够覆盖各种类型的单词和短语。此外,最近收集的网页和新闻数据使我们能够学习新词的语义表示。
- 词汇建设。为了丰富我们的词汇,我们涉及维基百科和百度百科的短语。我们还在基于语料库的语义类挖掘中应用短语发现方法:分布式与基于模式的方法,这增强了新兴短语的覆盖范围。
- 训练算法。我们的语料库使用Directional Skip-Gram进行训练:明确区分用于单词嵌入的左右上下文,其基于单词共现和单词对的方向,即在上下文窗口中哪个单词在左侧。
简单案例
为了举例说明学习的表示,在下面展示了一些样本单词最相似的单词。这里嵌入之间的余弦距离用于计算两个单词/短语的距离。
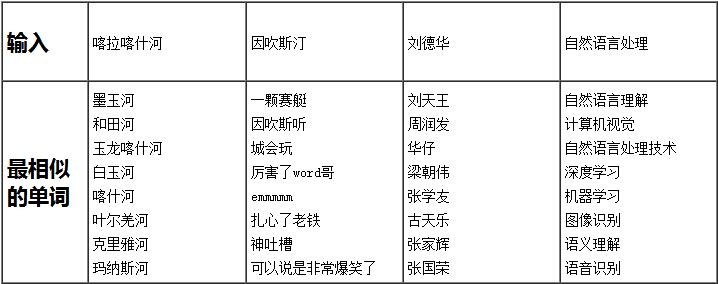
下载:ai.tencent.com/ailab/nlp/embedding.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消