











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开发流体标注,标注图像数据集速度提高3倍
2018年10月23日 由 浅浅 发表
452490
0
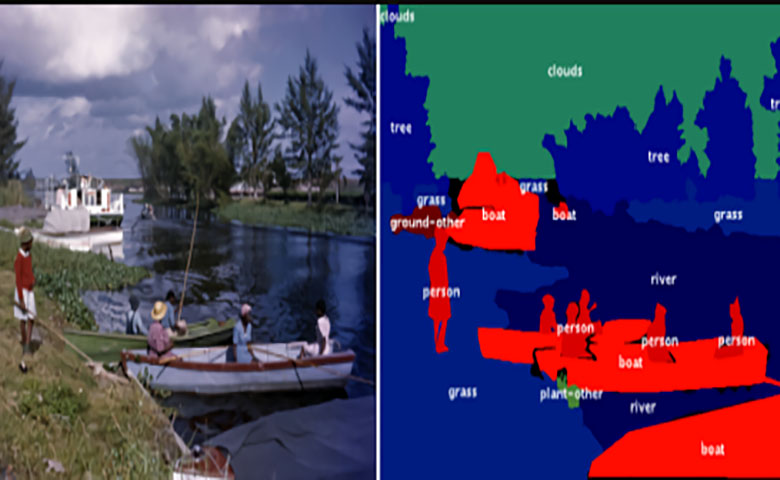 标注通常是AI模型训练过程中最艰巨的部分。在计算机视觉中尤其如此,传统的标记工具需要人类来描绘给定图像中的每个对象。例如,在流行的Coco + Stuff数据集中标记单张图片需要19分钟;标记包含164000张图像的整个数据集将花费53000小时。
标注通常是AI模型训练过程中最艰巨的部分。在计算机视觉中尤其如此,传统的标记工具需要人类来描绘给定图像中的每个对象。例如,在流行的Coco + Stuff数据集中标记单张图片需要19分钟;标记包含164000张图像的整个数据集将花费53000小时。幸运的是,谷歌开发了一种解决方案,有望大幅减少标注时间。它被称为流体标注(Fluid Annotation),它使用机器学习来标注类标签并勾勒出图片中的每个对象和背景区域。谷歌声称它可以将标注数据集的创建速度提高三倍。

流体标注从预训练的语义分割模型(Mask R-CNN)的输出开始,该模型生成大约1000个具有类别标签和置信度分数的图像片段(基本上,它将图像的每个像素与类别标签相关联,例如“花”,“人”,“道路”或“天空”)。具有最高置信度的片段被传递给人类工作者以进行标记。
标注器可以通过仪表板修改图像,选择要更正的内容和顺序。他们能够将现有细分的标签与自动生成的短名单中的另一个交换,添加细分以覆盖缺失的对象,移除现有细分或更改重叠细分的深度顺序。

使用传统手动标记工具(中间列)和流体注释(右)在三个COCO中的图像上进行标记比较。虽然使用手动标记工具时对象边界通常更准确,但标记差异的最大来源是因为人类标记者通常不同意确切的对象类。
“流体标注是使图像标注更快更容易的第一个探索性步骤,”谷歌机器感知部门的高级研究科学家Jasper Uijlings和Vittorio Ferrari在博客文章中写道,“在未来的工作中,我们的目标是改进对象边界的标记,通过包含更多的机器智能使界面更快,最后扩展界面来处理以前看不见的类,最需要高效的数据收集。”
谷歌并不是唯一一个将AI应用于数据标注的。旧金山创业公司Scale采用人工数据标注和机器学习算法相结合的方式,为Lyft、通用汽车、Zoox、Voyage、nuTonomy等客户整理原始的、没有标记的信息流。在同一个模型上进行监督:深度学习模型和群体协作的结合。总部位于瑞典的mapeera建立了一个街头图像数据库,利用计算机视觉技术分析了这些图像中的数据。
流体标注演示:fluidann.appspot.com/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消